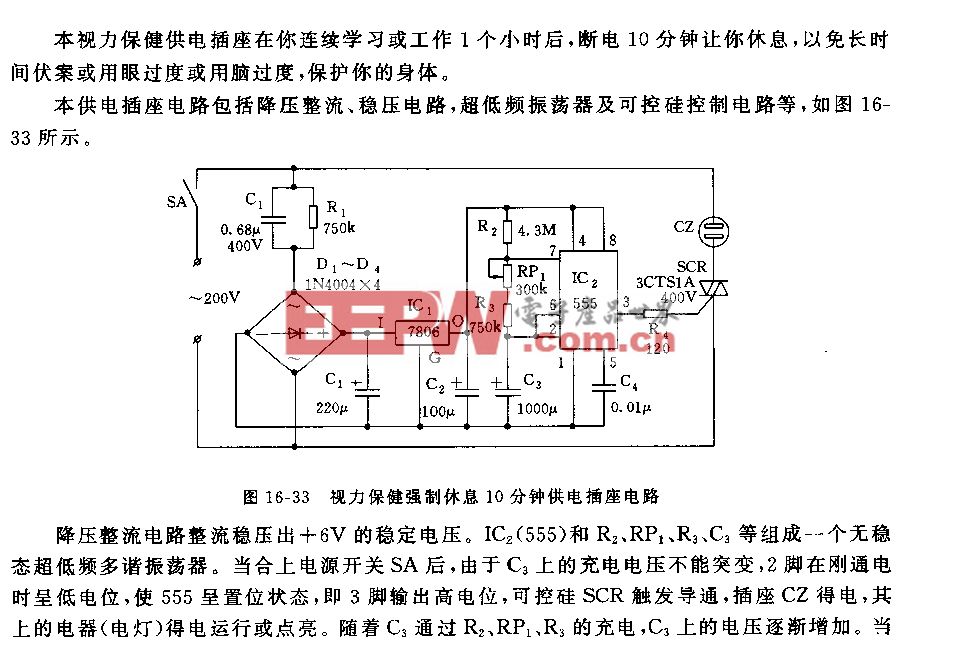
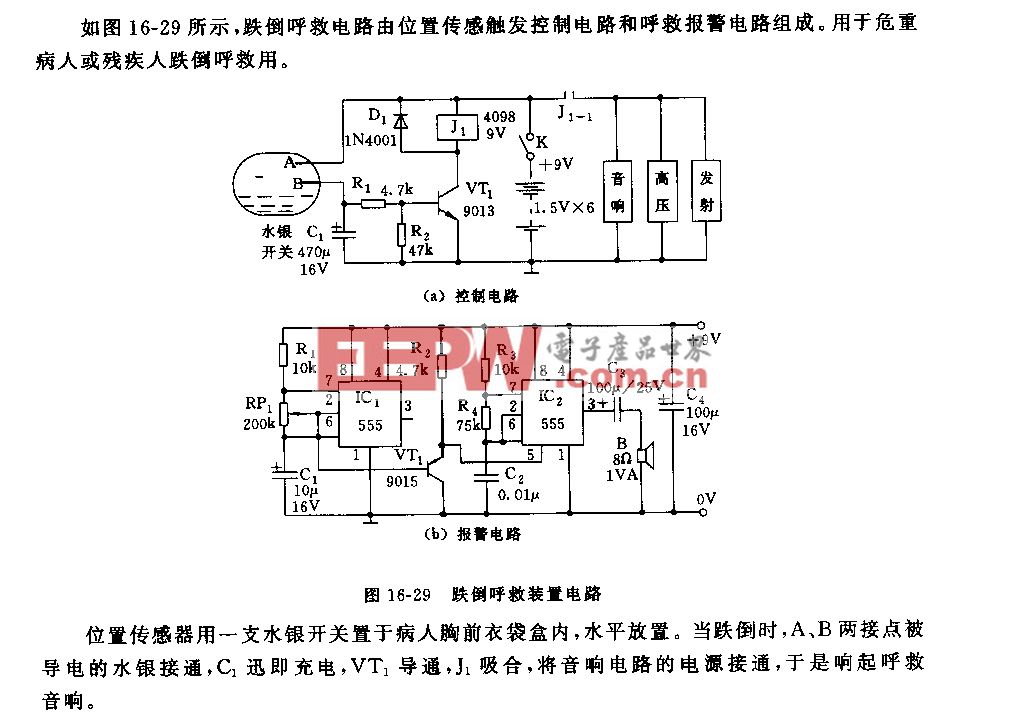
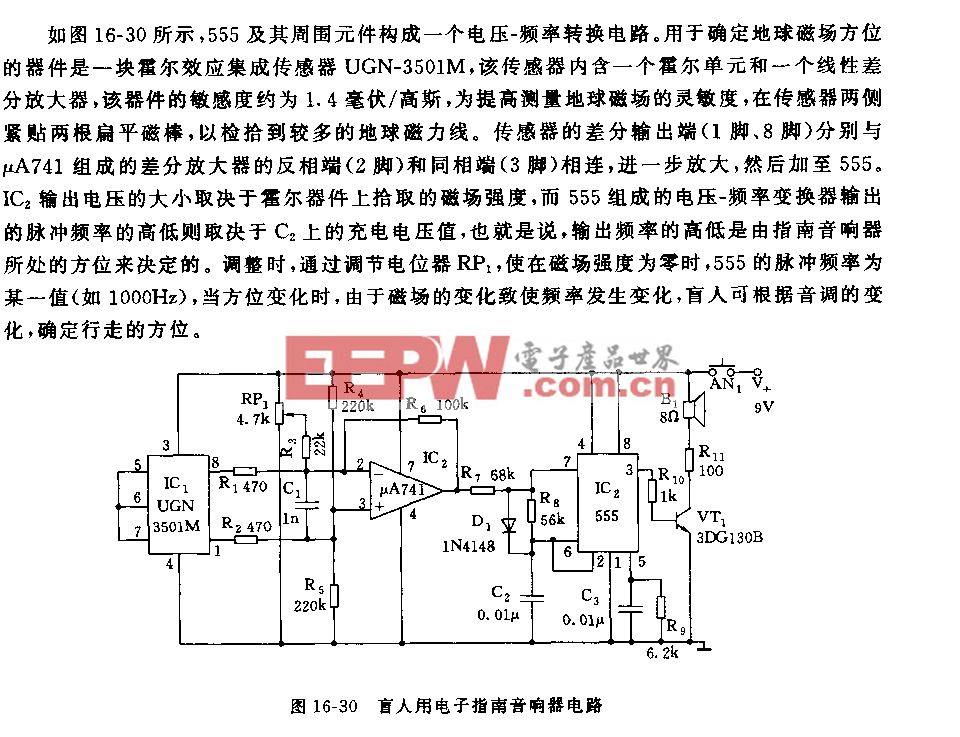
讓機(jī)器“解疑釋惑”:視覺世界中的結(jié)構(gòu)化理解|VALSE2018之八(3)

剛才我們所介紹的仍然是具有類似語義信息的這樣一些特征,其實這樣的特征并不一定要具有相同語義。在具體工作中,可以考慮這些特征可以具有不同的語義信息。比如說物體檢測中可能有專門對應(yīng)每一個物體的特征,比如說這位女士自己的特征,對于牙刷也有它自己的特征,小孩和他的牙刷都有自己的特征,往上走不同物體之間關(guān)系也有一組專門識別物體關(guān)系的特征。繼續(xù)上走,每個語句也有自己的特征。如果考慮每一個特征都是一個結(jié)點的話,仍然可以利用它們之間的關(guān)系,通用邊進(jìn)行信息傳遞,最終提高這三個不同任務(wù)的效果。


上面介紹利用結(jié)構(gòu)化信息傳遞在不同任務(wù)進(jìn)行結(jié)構(gòu)化信息建模。它面臨的問題是信息傳遞沒有任何理論指導(dǎo),我們只是通過觀察來設(shè)計并通過實驗發(fā)現(xiàn)這樣做有效。為了解決這個問題,我們引入統(tǒng)計模型。具體而言,我們引入條件隨機(jī)場,幫助我們進(jìn)行網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計。網(wǎng)絡(luò)結(jié)構(gòu)符合這樣的統(tǒng)計模型。在具體工作中,我們對特征之間的信息傳遞利用條件隨機(jī)場進(jìn)行建模,也對加入門限控制的特征信息傳遞利用條件隨機(jī)場進(jìn)行建模。

在統(tǒng)計模型指導(dǎo)下,另外一個優(yōu)勢可以利用統(tǒng)計模型中一個很好的信息傳遞方法,幫助指導(dǎo)我們怎樣在各個節(jié)點之間傳遞信息才是最有效的。

所以,對于結(jié)構(gòu)化信息傳遞,在已有基礎(chǔ)上考慮結(jié)構(gòu)化的輸出,可以引入結(jié)構(gòu)化特征,將結(jié)構(gòu)化特征和結(jié)構(gòu)化輸出進(jìn)行聯(lián)合學(xué)習(xí)。



除了結(jié)構(gòu)化學(xué)習(xí),我們實驗室在基礎(chǔ)網(wǎng)絡(luò)設(shè)計上我們也做了很多工作。林達(dá)華老師設(shè)計非常好的網(wǎng)絡(luò)-PoLyNet,它是一種非常深的網(wǎng)絡(luò)結(jié)構(gòu)。這個網(wǎng)絡(luò)結(jié)構(gòu)的基本想法是同一個模塊中,引入多個inception module,可以并行或串行。利用這個方法達(dá)華老師所帶的學(xué)生參加2016年的競賽,競賽中單個模型結(jié)果是當(dāng)時最好的。

另外一個工作動機(jī)是,如果有同樣大小的人臉,但是局部特征是不一樣的。比如說在這個例子中有三張同樣大小人臉,但是人的眼睛和嘴巴視覺信息大小是不一樣的。這就要求我們的神經(jīng)元具有多樣性能夠捕捉到這些不同大小的特征。

為了捕捉到不同大小的特征,有一種設(shè)計,就是設(shè)計不同大小的濾波器或者將不同大小的濾波器進(jìn)行疊加,比如說有3×3再往上疊,可以得到5x5,這會增大參數(shù)量和計算復(fù)雜度。
我們考慮另外一種方式就是下采樣。第一個分支中不采用任何下采樣,這樣情況下3×3的卷積對應(yīng)的視覺信息就是3×3的大小,如果另外一個分支使用2的下采樣,特征會變得原來1/2,3×3卷積看到大小就是6×6。通過這種方法,只需要改變下采樣的參數(shù),就能幫助我們實現(xiàn)捕捉不同大小特征的目的。最終,我們利用上采操作,使下采樣造成的不同大小分辨率的特征變成同樣大小,便于把它們連接起來。下采樣和上采樣不需要參數(shù),運(yùn)算快。這種做法取得了良好的實驗效果。
論文相關(guān)代碼在:
https://github.com/bearpaw/PyraNet.


另外一個問題,最近大家提出多種網(wǎng)絡(luò)結(jié)構(gòu)化,如ResNet,DenseNet,ResNext,甚至像GoogleNet和我們設(shè)計的PolyNet,這些網(wǎng)絡(luò)具有一個共性:它有多個分支。有一個問題是,對應(yīng)于有多個分支的網(wǎng)絡(luò)結(jié)構(gòu)情況下,常用的參數(shù)初始化方法的基本假設(shè)是不成立的。如果用這樣的參數(shù)初始化會帶來一些問題。為了解決這個問題,我們進(jìn)行嚴(yán)格的理論推導(dǎo),并給出最終答案。推導(dǎo)發(fā)現(xiàn)與輸入、輸出分支數(shù)和參數(shù)初始化是相關(guān)的。在圖像分類以及人體姿態(tài)識別上都發(fā)現(xiàn)使用我們的方法以后會得到更好的效果。

另外就是人的行為識別。行為識別和很多做視頻任務(wù)里很重要的信息是運(yùn)動。


如果要得到關(guān)于運(yùn)動的信息,我們發(fā)現(xiàn)有一種很簡單的操作,就是先得到兩幀圖像特征,把兩個特征點對點(element-wise)相減。這個相減是時間上的梯度,空間上的梯度可以用很簡單的操作得到。這樣簡單的操作它背后來源于我們數(shù)學(xué)的推導(dǎo),數(shù)學(xué)的推導(dǎo)告訴我們這樣特征的表示和光流(optical flow)是正交的,正交意味著它們是互補(bǔ)的,這種特征會擁有原來optical flow沒有的信息。實驗發(fā)現(xiàn)使用我們這種特征而不使用optical flow,能達(dá)到的相似的準(zhǔn)確率,但在速度上可以快很多。另外,由于特征是由它互補(bǔ)的,特征結(jié)合以后可以進(jìn)一步改善準(zhǔn)確率。論文相關(guān)代碼會在近期提供。

總結(jié)一下,結(jié)構(gòu)化深度學(xué)習(xí)在很多視覺任務(wù)中都是有效的。結(jié)構(gòu)化信息通常是來源于觀察,來源于對問題的理解。視覺領(lǐng)域的研究者對特定問題的觀察和理解可以聯(lián)合深度學(xué)習(xí)一起推進(jìn)整個視覺的進(jìn)步。另外,我們可以對輸出和特征進(jìn)行結(jié)構(gòu)化的建模。而深度學(xué)習(xí)這樣一個工具提供的能力是將結(jié)構(gòu)的建模和特征的學(xué)習(xí)進(jìn)行聯(lián)合學(xué)習(xí),增大最終解決任務(wù)的能力。

最后,廣而告之: 將在ECCV2018舉辦首屆WIDER Face and Pedestrian 競賽和workshop。該競賽包含以下三個子任務(wù):
WIDER Face:探索人臉檢測的新方法,
WIDER Pedestrian:探索監(jiān)控和自動駕駛環(huán)境下行人檢測的新方法,
WIDER Person Search:一個全新的從192部電影中人物檢索的挑戰(zhàn)。
每個任務(wù)的獲勝團(tuán)隊將獲得現(xiàn)金獎勵和亞馬遜服務(wù)器機(jī)時獎勵。 競賽中獲勝并具有創(chuàng)新方法的團(tuán)隊將獲邀參加ECCV workshop并共同撰寫競賽報告文章。
文中提到的參考文獻(xiàn)百度網(wǎng)盤鏈接:
https://pan.baidu.com/s/1hmclXnibvm_kUIgJTi_Zyw 密碼: n9bi
*博客內(nèi)容為網(wǎng)友個人發(fā)布,僅代表博主個人觀點,如有侵權(quán)請聯(lián)系工作人員刪除。

fpga相關(guān)文章:fpga是什么