安全隱患:神經網絡可以隱藏惡意軟件

編譯 | 禾木木
出品 | AI科技大本營(ID:rgznai100)
憑借數百萬和數十億的數值參數,深度學習模型可以做到很多的事情,例如,檢測照片中的對象、識別語音、生成文本以及隱藏惡意軟件。加州大學圣地亞哥分校和伊利諾伊大學的研究人員發現,神經網絡可以在不觸發反惡意軟件的情況下嵌入惡意負載。
惡意軟件隱藏技術 EvilModel 揭示了深度學習的安全問題,這已成為機器學習和網絡安全會議討論的熱門話題。隨著深度學習逐漸與我們的應用中變得必不可分,安全社區需要考慮新的方法來保護用戶免受這類新興的威脅。

深度學習模型中隱藏的惡意軟件
每個深度學習模型都是由多層人工神經元組成,根據層的類型,每個神經元與其上一層和下一層中的所有或部分神經元有所連接。根據深度學習模型在針對任務訓練時使用的參數數值不同,神經元間連接的強度也會不同,大型的神經網絡甚至可以擁有數億乃至數十億的參數。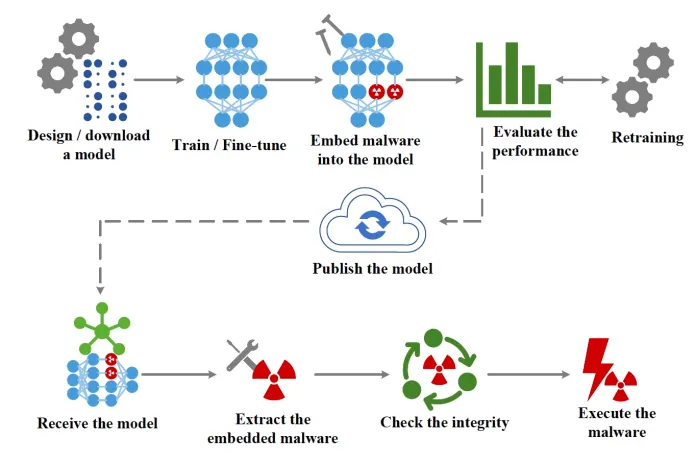 EvilModel 背后的主要思想是將惡意軟件嵌入到神經網絡的參數中,使其對惡意軟件掃描儀不可見。這是隱寫術的一種形式,將一條信息隱藏在另一條信息中的做法。同時,攜帶惡意病毒的深度學習模型還必須執行其主要任務(例如,圖像分類)做到和正常模型一樣號,以避免引起懷疑或使其對受害者無用。最后,攻擊者必須有一種機制將受感染的模型傳遞給目標設備,并從模型參數中提取惡意軟件。
EvilModel 背后的主要思想是將惡意軟件嵌入到神經網絡的參數中,使其對惡意軟件掃描儀不可見。這是隱寫術的一種形式,將一條信息隱藏在另一條信息中的做法。同時,攜帶惡意病毒的深度學習模型還必須執行其主要任務(例如,圖像分類)做到和正常模型一樣號,以避免引起懷疑或使其對受害者無用。最后,攻擊者必須有一種機制將受感染的模型傳遞給目標設備,并從模型參數中提取惡意軟件。

更改參數值
多數深度學習模型都會使用 32 位(4 個字節)的浮點數來存儲參數值。據研究者實驗,黑客可以在不顯著提升其中數值的前提下,每個參數中存儲最多存儲 3 字節的病毒。 大多數深度學習模型使用 32 位(4字節)浮點數來存儲參數值。根據研究,在不顯著提升其數值的前提下,最多有三字節可用于嵌入惡意代碼。在感染深度學習模型時,攻擊者會將病毒打散至 3 字節,并將數據嵌入到模型的參數之中。為了將惡意軟件傳輸至目標的手段,攻擊者可以將感染后的模型發布至 GitHub 或 TorchHub 等任意托管神經模型的網站。或是通過更復雜的供應鏈攻擊形式,讓目標設備上軟件的自動更新來傳播受感染的模型。一旦受感染后的模型交付給受害者,一個小小的軟件就可提取并執行負載。
大多數深度學習模型使用 32 位(4字節)浮點數來存儲參數值。根據研究,在不顯著提升其數值的前提下,最多有三字節可用于嵌入惡意代碼。在感染深度學習模型時,攻擊者會將病毒打散至 3 字節,并將數據嵌入到模型的參數之中。為了將惡意軟件傳輸至目標的手段,攻擊者可以將感染后的模型發布至 GitHub 或 TorchHub 等任意托管神經模型的網站。或是通過更復雜的供應鏈攻擊形式,讓目標設備上軟件的自動更新來傳播受感染的模型。一旦受感染后的模型交付給受害者,一個小小的軟件就可提取并執行負載。

在卷積神經網絡中隱藏的惡意軟件
為了驗證 EvilModel 的可行性,研究人員在多個卷積神經網絡(CNN)中進行了測試。CNN 是個很好的測試環境,首先,CNN 的體積都很大,通常會有幾十層和數百萬的參數;其次,CNN 包含各類架構,有不同類型的層(全連接層、卷積層)、不同的泛化技術(批歸一化、棄權、池化等等),這些多樣化讓評估各類病毒嵌入設定變得可能;第三,CNN 通常用于計算機視覺類的應用,這些都是惡意因素的主要攻擊對象;最后,很多經過預訓練的 CNN 可以在不經任何改動的情況下直接集成到新的應用程序中,而多數在應用中使用預訓練 CNN 的開發人員并不一定知道深度學習的具體應用原理。研究人員首先嘗試進行病毒嵌入的神經網路是AlexNet,一款曾在 2012 年重新激起人們對深度學習興趣的流行軟件,擁有 178 兆字節、五個卷積層和三個密集層或全連接層。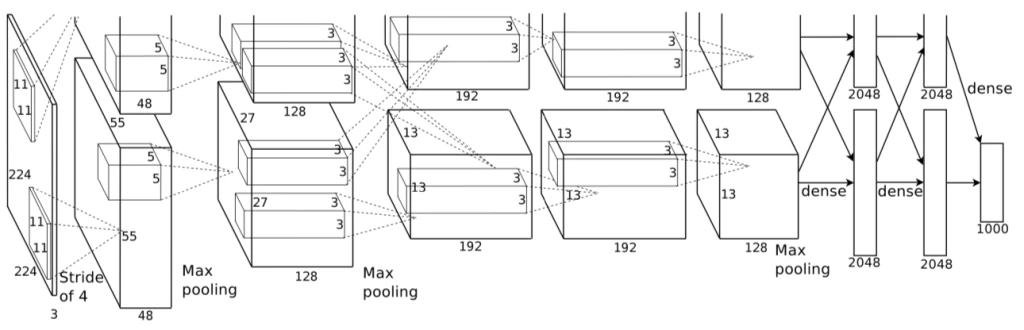 在用批量標準化(Batch Normalization,一種先分組標準化訓練樣本,再進入深度模型訓練的技術)訓練 AlexNet 時,研究者們成功將 26.8 M 的惡意軟件嵌入到了模型之中,并同時確保了其與正常模型預測的準確率相差不超過 1%。但如果增加惡意軟件的數據量,準確率將大幅下降。下一步的實驗是重新訓練感染后模型。通過凍結受感染神經元避免其在額外訓練周期中被修改,再加上批量標準化和再訓練,研究人員成功將惡意病毒的數據量提升至 36.9MB,并同時保證了模型的準確率在 90% 以上。
在用批量標準化(Batch Normalization,一種先分組標準化訓練樣本,再進入深度模型訓練的技術)訓練 AlexNet 時,研究者們成功將 26.8 M 的惡意軟件嵌入到了模型之中,并同時確保了其與正常模型預測的準確率相差不超過 1%。但如果增加惡意軟件的數據量,準確率將大幅下降。下一步的實驗是重新訓練感染后模型。通過凍結受感染神經元避免其在額外訓練周期中被修改,再加上批量標準化和再訓練,研究人員成功將惡意病毒的數據量提升至 36.9MB,并同時保證了模型的準確率在 90% 以上。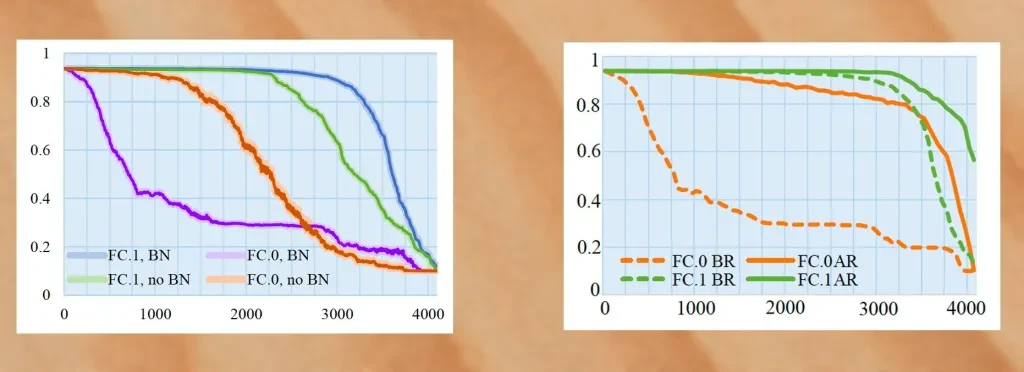 研究中實驗用的八個樣本病毒都是可以被線上病毒掃描網站 VirusTotal 識別為惡意軟件的,一旦樣本成功嵌入神經網絡,研究人員就會將模型上傳至 VirusTotal 中進行掃描。而病毒掃描結果卻顯示這些模型“安全”,意味著惡意軟件的偽裝并未暴露。研究人員又在其他幾個 CNN 架構上進行了相同的測試, 包括 VGG、ResNet、Inception,以及 Mobilenet。實驗結果類似,惡意軟件都未被成功檢測。這些隱匿的惡意軟件將會是所有大型神經網絡都需要面對的威脅。
研究中實驗用的八個樣本病毒都是可以被線上病毒掃描網站 VirusTotal 識別為惡意軟件的,一旦樣本成功嵌入神經網絡,研究人員就會將模型上傳至 VirusTotal 中進行掃描。而病毒掃描結果卻顯示這些模型“安全”,意味著惡意軟件的偽裝并未暴露。研究人員又在其他幾個 CNN 架構上進行了相同的測試, 包括 VGG、ResNet、Inception,以及 Mobilenet。實驗結果類似,惡意軟件都未被成功檢測。這些隱匿的惡意軟件將會是所有大型神經網絡都需要面對的威脅。

保護機器學習管道
考慮到潛藏在深度學習模型中的惡意負載可以避過病毒掃描的檢測,對抗 EvilModel 的唯一手段恐怕就只有直接銷毀病毒本身了。這類病毒只有在所有字節都完好無損才能保證感染成功。因此,如果收到 EvilModel 的受害者可以在不凍結受感染層的情況下重新訓練模型,改變參數數值,便可讓病毒數據直接被銷毀。這樣,即使只有一輪的訓練也足以摧毀任何隱藏在深度學習模型中的惡意病毒。但是,大多數開發人員都按原樣使用預訓練模型,除非他們想要針對其他應用做更細致的調整。而很多的細調都會凍結網絡中絕大多數的層,這些層里很大可能包含了受感染的那些。這就意味著,除了對抗攻擊,數據中毒、成員推理等其他已知的安全問題之外,受惡意軟件感染的神經網絡也將成為深度學習的未來中真正的威脅之一。 機器學習模型與經典的、基于規則的軟件之間的差別意味著我們需要新的方法來應對安全威脅。2021 年上半年的時候,不少組織都提出了對抗性機器學習威脅矩陣,一個可協助開發者們發現機器學習管道弱點并修補安全漏洞的框架。雖然威脅矩陣更側重于對抗性攻擊,但其所提出的方法也適用于 EvilModels 等威脅。在研究人員找到更可靠的手段來檢測并阻止深度學習網絡中的惡意軟件之前,我們必須確立機器學習管道中的信任鏈。既然病毒掃描和其他靜態分析工具無法檢測到受感染模型,開發者們必須確保他們所使用的模型是來自可信任的渠道,并且訓練數據和學習參數未受到損害。隨著我們在深度學習安全問題方面更深一步的研究,我們也必須對那些用于分析圖片或識別語音的、數量龐雜的數據背后所隱藏的東西保持警惕。參考鏈接:https://bdtechtalks.com/2021/12/09/evilmodel-neural-networks-malware
機器學習模型與經典的、基于規則的軟件之間的差別意味著我們需要新的方法來應對安全威脅。2021 年上半年的時候,不少組織都提出了對抗性機器學習威脅矩陣,一個可協助開發者們發現機器學習管道弱點并修補安全漏洞的框架。雖然威脅矩陣更側重于對抗性攻擊,但其所提出的方法也適用于 EvilModels 等威脅。在研究人員找到更可靠的手段來檢測并阻止深度學習網絡中的惡意軟件之前,我們必須確立機器學習管道中的信任鏈。既然病毒掃描和其他靜態分析工具無法檢測到受感染模型,開發者們必須確保他們所使用的模型是來自可信任的渠道,并且訓練數據和學習參數未受到損害。隨著我們在深度學習安全問題方面更深一步的研究,我們也必須對那些用于分析圖片或識別語音的、數量龐雜的數據背后所隱藏的東西保持警惕。參考鏈接:https://bdtechtalks.com/2021/12/09/evilmodel-neural-networks-malware
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






