想成為Python高手,必須看這篇爬蟲原理介紹!(附29個爬蟲項目)

互聯網是由一個個站點和網絡設備組成的大網,我們通過瀏覽器訪問站點,站點把HTML、JS、CSS代碼返回給瀏覽器,這些代碼經過瀏覽器解析、渲染,將豐富多彩的網頁呈現我們眼前。
如果我們把互聯網比作一張大的蜘蛛網,數據便是存放于蜘蛛網的各個節點,而爬蟲就是一只小蜘蛛,沿著網絡抓取自己的獵物(數據)爬蟲指的是:向網站發起請求,獲取資源后分析并提取有用數據的程序。
從技術層面來說就是 通過程序模擬瀏覽器請求站點的行為,把站點返回的HTML代碼/JSON數據/二進制數據(圖片、視頻) 爬到本地,進而提取自己需要的數據,存放起來使用;
二、爬蟲的基本流程
用戶獲取網絡數據的方式:
方式1:瀏覽器提交請求--->下載網頁代碼--->解析成頁面
方式2:模擬瀏覽器發送請求(獲取網頁代碼)->提取有用的數據->存放于數據庫或文件中
爬蟲要做的就是方式2。
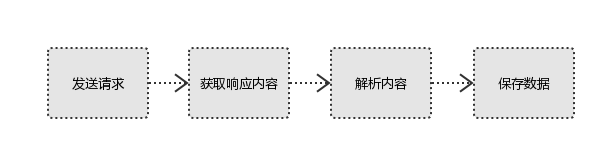
1、發起請求
使用http庫向目標站點發起請求,即發送一個Request
Request包含:請求頭、請求體等
Request模塊缺陷:不能執行JS 和CSS 代碼
2、獲取響應內容
如果服務器能正常響應,則會得到一個Response
Response包含:html,json,圖片,視頻等
3、解析內容
解析html數據:正則表達式(RE模塊),第三方解析庫如Beautifulsoup,pyquery等
解析json數據:json模塊
解析二進制數據:以wb的方式寫入文件
4、保存數據
數據庫(MySQL,Mongdb、Redis)
文件
三、http協議 請求與響應
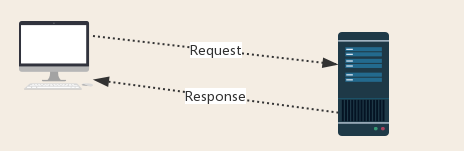
Request:用戶將自己的信息通過瀏覽器(socket client)發送給服務器(socket server)
Response:服務器接收請求,分析用戶發來的請求信息,然后返回數據(返回的數據中可能包含其他鏈接,如:圖片,js,css等)
ps:瀏覽器在接收Response后,會解析其內容來顯示給用戶,而爬蟲程序在模擬瀏覽器發送請求然后接收Response后,是要提取其中的有用數據。
四、 request
1、請求方式:
常見的請求方式:GET / POST
2、請求的URL
url全球統一資源定位符,用來定義互聯網上一個唯一的資源 例如:一張圖片、一個文件、一段視頻都可以用url唯一確定
url編碼
https://www.baidu.com/s?wd=圖片
圖片會被編碼(看示例代碼)
網頁的加載過程是:
加載一個網頁,通常都是先加載document文檔,
在解析document文檔的時候,遇到鏈接,則針對超鏈接發起下載圖片的請求
3、請求頭
User-agent:請求頭中如果沒有user-agent客戶端配置,服務端可能將你當做一個非法用戶host;
cookies:cookie用來保存登錄信息
注意:一般做爬蟲都會加上請求頭
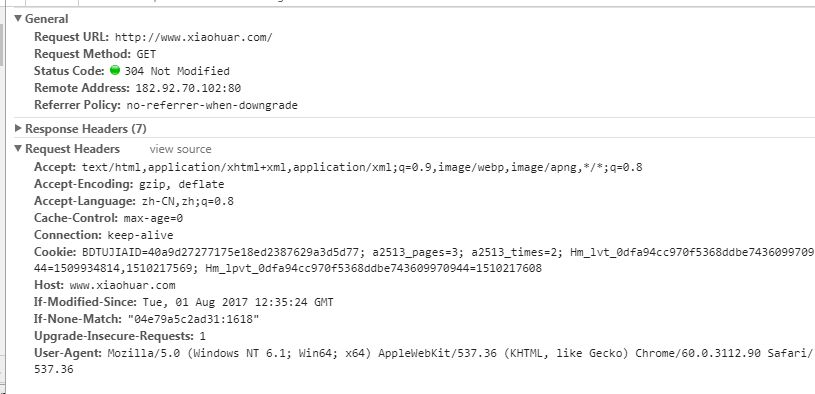
請求頭需要注意的參數:
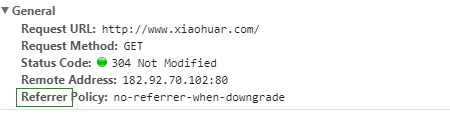
(1)Referrer:訪問源至哪里來(一些大型網站,會通過Referrer 做防盜鏈策略;所有爬蟲也要注意模擬)
(2)User-Agent:訪問的瀏覽器(要加上否則會被當成爬蟲程序)
(3)cookie:請求頭注意攜帶
4、請求體
請求體
如果是get方式,請求體沒有內容 (get請求的請求體放在 url后面參數中,直接能看到)
如果是post方式,請求體是format dataps:
1、登錄窗口,文件上傳等,信息都會被附加到請求體內
2、登錄,輸入錯誤的用戶名密碼,然后提交,就可以看到post,正確登錄后頁面通常會跳轉,無法捕捉到post
五、 響應Response
1、響應狀態碼
200:代表成功
301:代表跳轉
404:文件不存在
403:無權限訪問
502:服務器錯誤
2、respone header
響應頭需要注意的參數:
(1)Set-Cookie:BDSVRTM=0; path=/:可能有多個,是來告訴瀏覽器,把cookie保存下來
(2)Content-Location:服務端響應頭中包含Location返回瀏覽器之后,瀏覽器就會重新訪問另一個頁面
3、preview就是網頁源代碼
JSO數據
如網頁html,圖片
二進制數據等
六、總結
1、總結爬蟲流程:
爬取--->解析--->存儲
2、爬蟲所需工具:
請求庫:requests,selenium(可以驅動瀏覽器解析渲染CSS和JS,但有性能劣勢(有用沒用的網頁都會加載);)
解析庫:正則,beautifulsoup,pyquery
存儲庫:文件,MySQL,Mongodb,Redis
補充:29個Python爬蟲項目(所有鏈接指向GitHub)
WechatSogou [1]- 微信公眾號爬蟲。基于搜狗微信搜索的微信公眾號爬蟲接口,可以擴展成基于搜狗搜索的爬蟲,返回結果是列表,每一項均是公眾號具體信息字典。
鏈接:https://github.com/Chyroc/WechatSogou
DouBanSpider [2]- 豆瓣讀書爬蟲。可以爬下豆瓣讀書標簽下的所有圖書,按評分排名依次存儲,存儲到Excel中,可方便大家篩選搜羅,比如篩選評價人數>1000的高分書籍;可依據不同的主題存儲到Excel不同的Sheet ,采用User Agent偽裝為瀏覽器進行爬取,并加入隨機延時來更好的模仿瀏覽器行為,避免爬蟲被封。
鏈接:https://github.com/lanbing510/DouBanSpider
zhihu_spider [3]- 知乎爬蟲。此項目的功能是爬取知乎用戶信息以及人際拓撲關系,爬蟲框架使用scrapy,數據存儲使用mongo
鏈接:https://github.com/LiuRoy/zhihu_spider
bilibili-user [4]- Bilibili用戶爬蟲。總數據數:20119918,抓取字段:用戶id,昵稱,性別,頭像,等級,經驗值,粉絲數,生日,地址,注冊時間,簽名,等級與經驗值等。抓取之后生成B站用戶數據報告。
鏈接:https://github.com/airingursb/bilibili-user
SinaSpider [5]- 新浪微博爬蟲。主要爬取新浪微博用戶的個人信息、微博信息、粉絲和關注。代碼獲取新浪微博Cookie進行登錄,可通過多賬號登錄來防止新浪的反扒。主要使用 scrapy 爬蟲框架。
鏈接:https://github.com/LiuXingMing/SinaSpider
distribute_crawler [6]- 小說下載分布式爬蟲。使用scrapy,Redis, MongoDB,graphite實現的一個分布式網絡爬蟲,底層存儲MongoDB集群,分布式使用Redis實現,爬蟲狀態顯示使用graphite實現,主要針對一個小說站點。
鏈接:https://github.com/gnemoug/distribute_crawler
CnkiSpider [7]- 中國知網爬蟲。設置檢索條件后,執行src/CnkiSpider.py抓取數據,抓取數據存儲在/data目錄下,每個數據文件的第一行為字段名稱。
鏈接:https://github.com/yanzhou/CnkiSpider
LianJiaSpider [8]- 鏈家網爬蟲。爬取北京地區鏈家歷年二手房成交記錄。涵蓋鏈家爬蟲一文的全部代碼,包括鏈家模擬登錄代碼。
鏈接:https://github.com/yanzhou/CnkiSpider
scrapy_jingdong [9]- 京東爬蟲。基于scrapy的京東網站爬蟲,保存格式為csv。
鏈接:https://github.com/taizilongxu/scrapy_jingdong
QQ-Groups-Spider [10]- QQ 群爬蟲。批量抓取 QQ 群信息,包括群名稱、群號、群人數、群主、群簡介等內容,最終生成 XLS(X) / CSV 結果文件。
鏈接:https://github.com/caspartse/QQ-Groups-Spider
wooyun_public[11]-烏云爬蟲。烏云公開漏洞、知識庫爬蟲和搜索。全部公開漏洞的列表和每個漏洞的文本內容存在MongoDB中,大概約2G內容;如果整站爬全部文本和圖片作為離線查詢,大概需要10G空間、2小時(10M電信帶寬);爬取全部知識庫,總共約500M空間。漏洞搜索使用了Flask作為web server,bootstrap作為前端。
鏈接:https://github.com/hanc00l/wooyun_public
spider[12]- hao123網站爬蟲。以hao123為入口頁面,滾動爬取外鏈,收集****,并記錄****上的內鏈和外鏈數目,記錄title等信息,windows7 32位上測試,目前每24個小時,可收集數據為10萬左右。
鏈接:https://github.com/hanc00l/wooyun_public
findtrip [13]- 機****爬蟲(去哪兒和攜程網)。Findtrip是一個基于Scrapy的機****爬蟲,目前整合了國內兩大機****網站(去哪兒 + 攜程)。
鏈接:https://github.com/hanc00l/wooyun_public
163spider [14] - 基于requests、MySQLdb、torndb的網易客戶端內容爬蟲。
鏈接:https://github.com/leyle/163spider
doubanspiders[15]- 豆瓣電影、書籍、小組、相冊、東西等爬蟲集 writen by Python
鏈接:https://github.com/sdfzy/doubanspiders
QQSpider [16]- QQ空間爬蟲,包括日志、說說、個人信息等,一天可抓取 400 萬條數據。
鏈接:https://github.com/LiuXingMing/QQSpider
baidu-music-spider [17]- 百度mp3全站爬蟲,使用redis支持斷點續傳。
鏈接:https://github.com/Shu-Ji/baidu-music-spider
tbcrawler[18]- 淘寶和天貓的爬蟲,可以根據搜索關鍵詞,物品id來抓去頁面的信息,數據存儲在mongodb。
鏈接:https://github.com/pakoo/tbcrawler
stockholm [19]- 一個股****數據(滬深)爬蟲和選股策略測試框架。根據選定的日期范圍抓取所有滬深兩市股****的行情數據。支持使用表達式定義選股策略。支持多線程處理。保存數據到JSON文件、CSV文件。
鏈接:https://github.com/benitoro/stockholm
BaiduyunSpider[20]-百度云盤爬蟲。
鏈接:https://github.com/k1995/BaiduyunSpider
Spider[21]-社交數據爬蟲。支持微博,知乎,豆瓣。
鏈接:https://github.com/Qutan/Spider
proxy pool[22]-Python爬蟲代理IP池(proxy pool)。
鏈接:https://github.com/Qutan/Spider
music-163[23]-爬取網易云音樂所有歌曲的評論。
鏈接:https://github.com/RitterHou/music-163
CnblogsSpider[24]-cnblogs列表頁爬蟲。
鏈接:https://github.com/jackgitgz/CnblogsSpider
spider_smooc[25]-爬取慕課網視頻。
鏈接:https://github.com/jackgitgz/CnblogsSpider
knowsecSpider2[26]-知道創宇爬蟲題目。
鏈接:https://github.com/littlethunder/knowsecSpider2
SinaSpider[27]-動態IP解決新浪的反爬蟲機制,快速抓取內容。
鏈接:https://github.com/szcf-weiya/SinaSpider
csdn-spider[28]-爬取CSDN上的博客文章。
鏈接:https://github.com/Kevinsss/csdn-spider
ProxySpider[29]-爬取西刺上的代理IP,并驗證代理可用性。
鏈接:https://github.com/changetjut/ProxySpider
來源:玩轉單片機
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

