大模型加持的機器人有多強,MIT CSAIL&IAIFI用自然語言指導機器人抓取物體

來自 MIT CSAIL 和 IAIFI 的研究者將準確的 3D 幾何圖形與來自 2D 基礎模型的豐富語義結合起來,讓機器人能夠利用 2D 基礎模型中豐富的視覺和語言先驗,完成語言指導的操作。
最近,具身智能成為人工智能領域關注的一個焦點。從斯坦福大學的 VIMA 機器人智能體,到谷歌 DeepMind 推出首個控制機器人的視覺 - 語言 - 動作(VLA)的模型 RT-2,大模型加持的機器人研究備受關注。
當前,自監督和語言監督的圖像模型已經包含豐富的世界知識,這對于泛化來說非常重要,但圖像特征是二維的。我們知道,機器人任務通常需要對現實世界中三維物體的幾何形狀有所了解。
基于此,來自 MIT CSAIL 和 IAIFI 的研究者利用蒸餾特征場(Distilled Feature Field,DFF),將準確的 3D 幾何圖形與來自 2D 基礎模型的豐富語義結合起來,讓機器人能夠利用 2D 基礎模型中豐富的視覺和語言先驗,完成語言指導的操作。

論文地址:https://arxiv.org/abs/2308.07931
具體來說,該研究提出了一種用于 6-DOF 抓取和放置的小樣本學習方法,并利用強大的空間和語義先驗泛化到未見過物體上。使用從視覺 - 語言模型 CLIP 中提取的特征,該研究提出了一種通過開放性的自然語言指令對新物體進行操作,并展示了這種方法泛化到未見過的表達和新型物體的能力。
方法介紹
該研究分析了少樣本和語言指導的操作,其中需要在沒見過類似物體的情況下,給定抓取演示或文本描述,機器人就能拾取新物體。為了實現這一目標,該研究圍繞預訓練圖像嵌入構建了系統,這也是從互聯網規模的數據集中學習常識先驗的可靠方法。
下圖 1 描述了該研究設計的系統:機器人首先使用安裝在自拍桿上的 RGB 相機拍攝一系列照片來掃描桌面場景,這些照片用于構建桌面的神經輻射場 (NeRF)。最重要的是,該神經輻射場經過訓練不僅可以渲染 RGB 顏色,還可以渲染來自預訓練視覺基礎模型的圖像特征。這會產生一種場景表征,稱為蒸餾特征場(DFF),它將 2D 特征圖的知識嵌入到 3D 體積中。然后,機器人參考演示和語言指令來抓取用戶指定的物體。
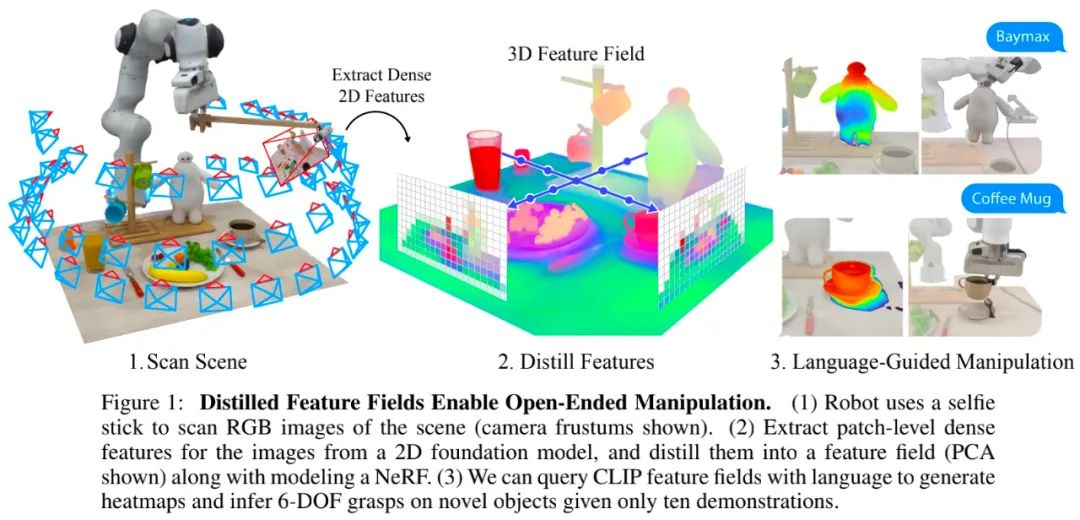
該研究的一大亮點是從 CLIP 模型中提取密集的二維特征,來給蒸餾特征場提供監督。此前,OpenAI 的 CLIP 模型僅提供圖片尺度的全局特征,而 3D 神經場的生成需要密集的 2D 描述符。
為了解決這個問題,研究團隊使用 MaskCLIP 對 CLIP 的視覺模型進行重新參數化,提取 patch 級密集特征。此方法不需要重新訓練,可以保證其描述符與語言模型的對齊。
具身智能 (embodied intelligence) 囊括機器人,自動駕駛汽車等和物理世界有相互作用的人工智能體。這類智能體需要對物理世界同時進行幾何空間和語義的理解來進行決策。
為了實現這樣的表征能力,研究團隊將視覺基礎模型和視覺 - 語言基礎模型中經過預訓練的二維視覺表征通過可微分的三維渲染,構建為 3D 特征場。團隊將這個方法運用在 6-DOF 機器人抓取任務上,這種方法叫作機器人操作特征場(Feature Fields for Robotic Manipulation,F3RM)的方法需要解決三個獨立的問題:
首先,如何以合理的速度自動生成場景的特征場;
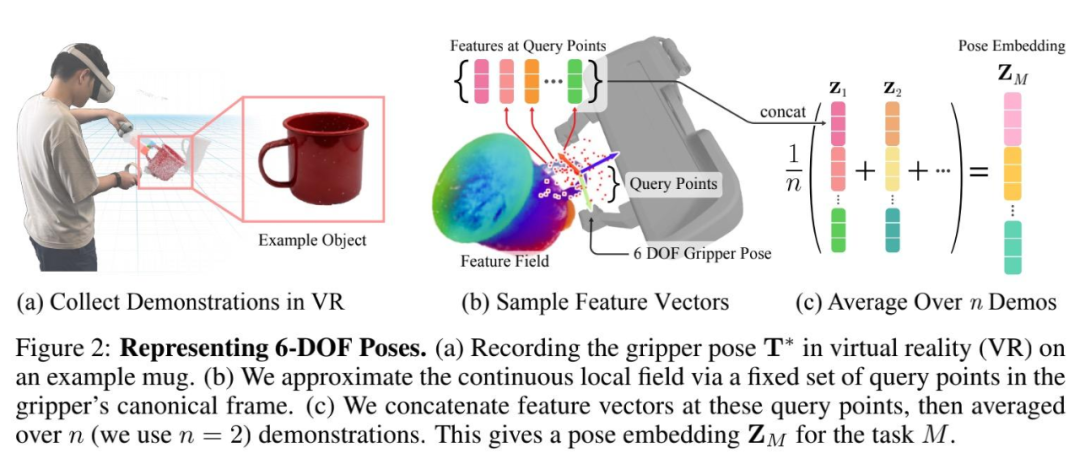
其次,如何表征和推斷 6-DOF 抓取和放置的姿勢;
最后,如何結合語言指導來實現開放文本命令。
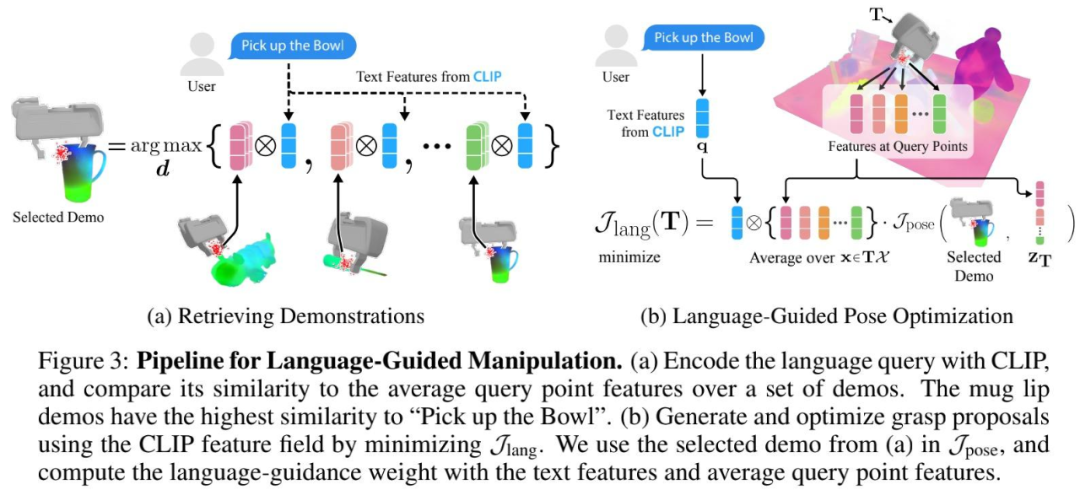
自然語言提供了一種將機器人操作擴展到開放物體集的方法,為目標物體照片不準確或不可用的情況提供了一種替代方案。在測試時,機器人接收來自用戶的開放文本語言查詢,其中指定要操作的物體。如下圖 3 所示,語言指導的姿勢推斷過程包括三個步驟:
檢索相關演示;
初始化粗略抓取;
語言指導的抓取姿勢優化。
實驗結果
我們先來看一些機器人抓取的實驗效果。例如,使用 F3RM 方法,機器人可以輕松抓取一個螺絲刀工具:

抓取小熊玩偶:

抓取透明杯子和藍色杯子:


把物體掛放在不同材質的架子上:


F3RM 還可以識別并抓取一些不常見的物體,比如化學領域會用到的量勺、量杯:


為了表明機器人能夠利用 2D 基礎模型中豐富的視覺和語言先驗,并且可以泛化到未見過的新型物體上,該研究還進行了一系列抓取和放置任務的實驗,我們來看下實驗結果。
從示例中學會抓握
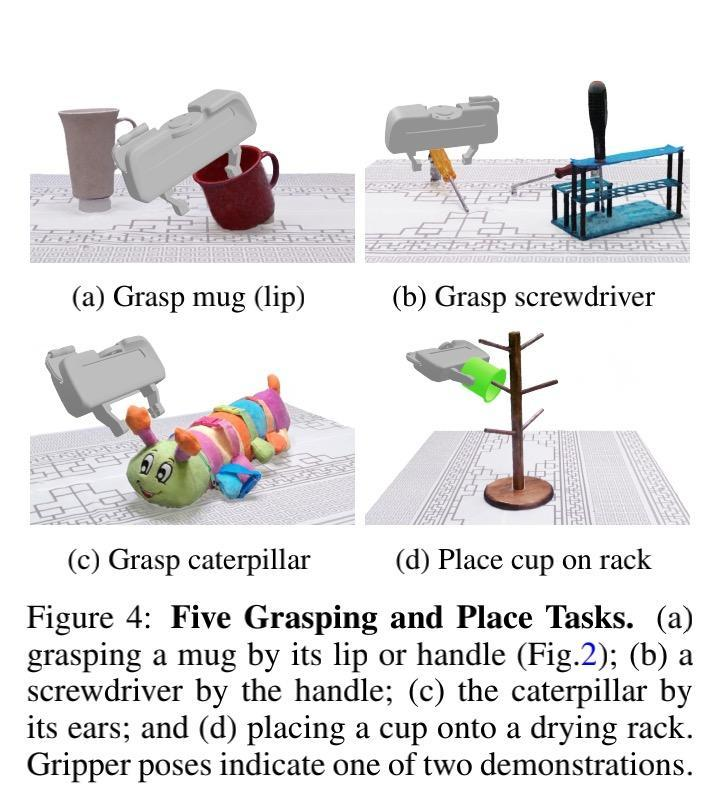
如下圖 4 所示,該研究進行了 6-DOF 抓取和放置任務,并為每個任務提供兩個演示。為了標記演示,該研究將 NeRF 重建的點云加載到虛擬現實中,并使用手動控制器將夾子移動到所需的姿勢(圖 2 (a))。
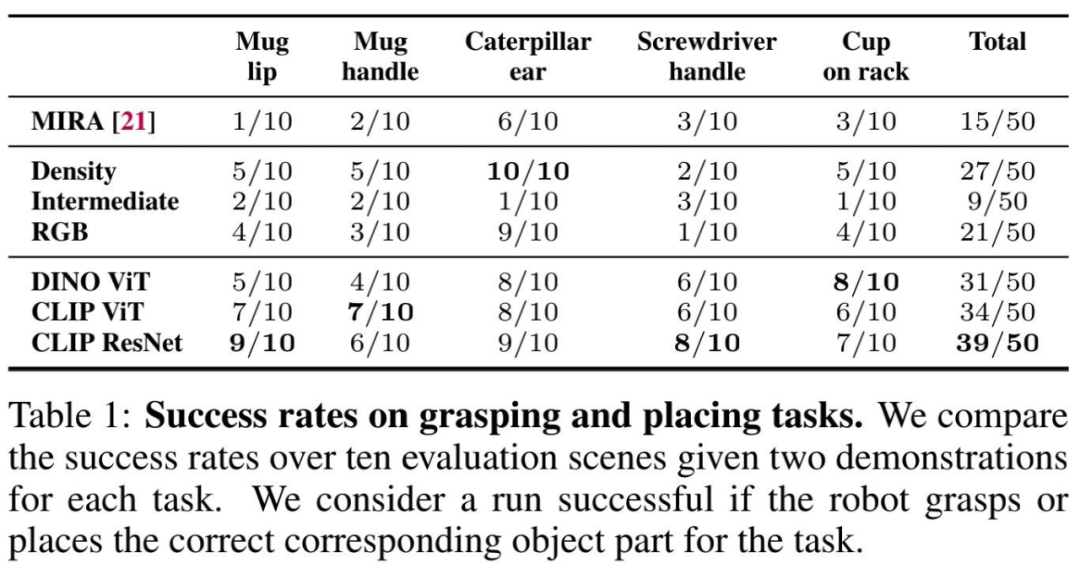
機器人在抓取和放置任務上的成功率如下表 1 所示:
下圖 5 展示了該研究所提方法在未見過的新物體上的泛化情況:

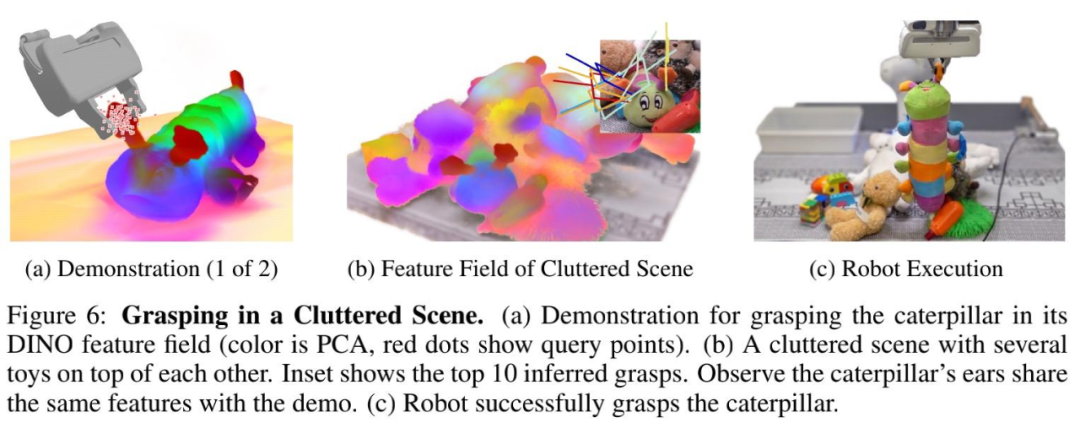
此外,語義特征和詳細 3D 幾何圖形之間的融合提供了一種對密集的堆疊進行建模的方法。例如,在下圖 6 (b) 中,毛毛蟲玩具被埋在其他玩具下面。圖 6 (c) 顯示機器人抓住了毛毛蟲玩具,并將其從玩具堆的底部拾起。
語言指導的機器人抓取
該研究設置了 13 個桌面場景來研究使用開放文本語言和 CLIP 特征場來指定要操作物體的可行性。
在下圖 7 中,機器人在語言指導下成功執行了 5 個抓握。整個場景包含 11 個物體,其中 4 個來自 YCB 物體數據集。

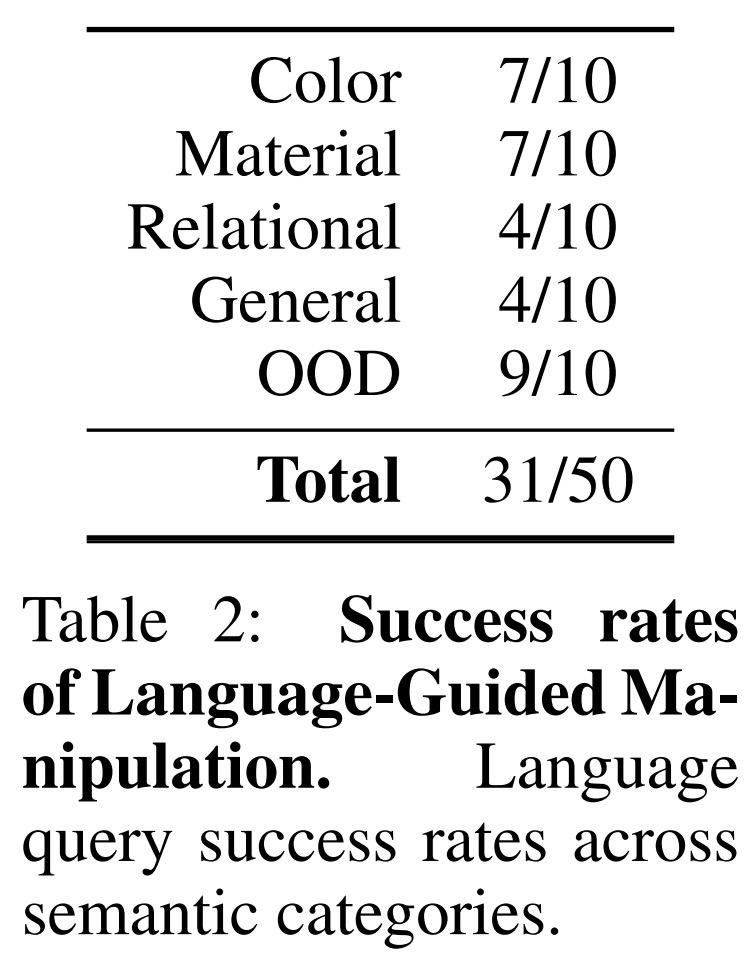
語言指導的操作成功率如下表 2 所示:
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






