基于LPC2138的中文輸入系統設計

3.2 漢字庫字模首地址查詢
漢字內碼是一個4位十六進制數,區位碼是一個4位的十進制數,每個漢字內碼或區位碼都對應著一個唯一的漢字或符號。圖6(a)和6(b)分別為區位碼表和漢字內碼表。其對應關系為:漢字內碼列=區碼+0xaO;漢字內碼行=位碼+0xaO。本文引用地址:http://cqxgywz.com/article/162830.htm

在E2PROM中,二級字庫字模的存儲格式為一維數組,而在漢字輸出匹配時采用的是漢字內碼格式(2個十六進制數表示),所以需要將漢字內碼的行和列二維地址換算成一維地址,從而對應找到24x 24字庫中漢字字模的起始位置。
對于最終匹配好的漢字編碼表中的漢字,取出其漢字內碼的行和列分別作為code_a和code_b(以“白”字為例,其漢字內碼為B0D7,則code_a=0xb0、code_b=0xd7)。則其對應的存儲器中24×24漢字字模首地址的計算關系為:存儲器中漢字字模首地址=[(code_a一0xal)+(code_b一0xb0)×94]×(24×24/8)。
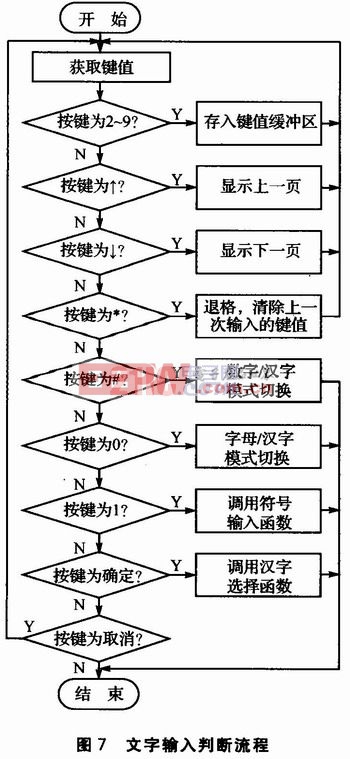
3.3 文字輸入判斷
T9鍵盤輸入時,需要對鍵值進行一系列的判斷。根據功能的不同,分別需要對數字鍵、翻頁鍵、退格鍵、數字/漢字切換鍵、字母/漢字切換鍵、符號鍵以及確定、取消鍵進行順次的判斷。其判斷流程如圖7所示。
3.4 數字、拼音和漢字匹配輸出
拼音編碼索引表和漢字編碼數組是一一對應的,如何實現對輸入數字序列與拼音列表之間的映射、拼音與漢字列表之間的映射、漢字與字庫芯片中漢字字模之間的映射是該系統的核心問題。
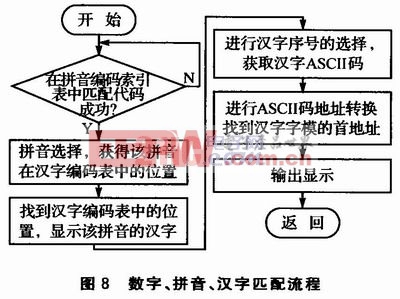
如圖8所示,數字、拼音和漢字匹配輸出程序步驟(以‘白’字為例):
①系統針對于所輸入的數字序列“224”,在拼音編碼索引表中進行匹配,得到兩個拼音“bai”和“cai”;
②通過光標選擇“bai”后,在拼音編碼索引表中可以獲得漢字編碼表中對應漢字的位置,即T9PY_IDX數組中的*hz_bai;
③在漢字編碼表中獲取hz_bai[]數組數據,送屏幕進行顯示“白百擺敗拜佰柏稗”;
④通過數字鍵選擇對應的漢字后,獲取該漢字的ASCII碼BOD7;
⑤將漢字內碼的ASCII碼通過漢字內碼地址的轉換,找到存儲芯片中該漢字字模數據的首地址,將字模數據送液晶顯示,完成一個漢字的輸入。
結語
本文介紹了基于Philips公司的ARM7微控制器LPC2138的T9中文輸入系統的設計方法,實現了漢字、英文字母、數字符號等文本信息的輸入。本方案可以為基于單片機的產品開發、中文輸入法研究等提供參考,具有一定的實用價值。




評論