CES獲獎:RAPA:以注意力機制重塑 4D 雷達感知范式

CES 2026 人工智能(Artificial Intelligence)類 Best of Innovation
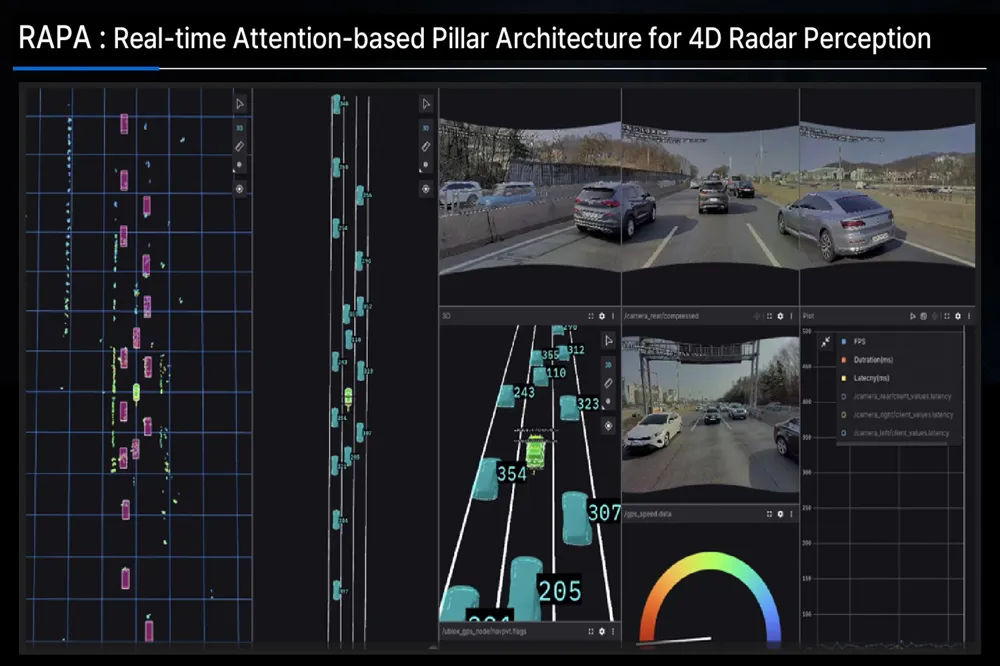
在 CES 2026 上,來自 Deep Fusion AI 的 RAPA(Real-time Attention-based Pillar Architecture for 4D Radar Perception) 榮獲 Artificial Intelligence 類別 Best of Innovation。
該系統是一套完全基于 4D 成像雷達的實時 360° 感知軟件架構,目標直指一個長期被認為“難以單獨成立”的技術命題:僅依靠雷達,實現接近 LiDAR 級別的自動駕駛環境感知能力。
背景:4D 雷達的潛力與現實落差
近年來,4D 成像雷達 被視為自動駕駛感知體系中的關鍵增量技術:
具備 距離、方位、俯仰 + 多普勒速度 的四維信息
全天候工作能力強,對雨、霧、雪、灰塵不敏感
成本顯著低于高線數 LiDAR,更易規模化部署
然而,在算法層面,4D 雷達長期存在兩個核心難題:
數據高度稀疏、噪聲強
傳統深度學習模型難以有效建模雷達信號特性
這導致雷達在多數系統中更多充當“輔助傳感器”,而非主感知來源。
RAPA,正是為打破這一技術天花板而設計。
RAPA 的核心定位:雷達原生(Radar-native)的感知架構
與“將雷達數據強行套用 LiDAR / Camera 網絡結構”的思路不同,RAPA 的設計原則是:
從雷達信號本身出發,構建原生適配 4D 雷達的數據表達與深度學習架構。
其關鍵特征包括:
軟件定義(software-defined)感知系統
100% 依賴多顆 4D 成像雷達
360° 全向覆蓋
無需攝像頭或 LiDAR 融合
這使 RAPA 成為一種真正意義上的 Radar-only Perception Solution。
注意力機制 + Pillar 表達:解決稀疏與噪聲問題
Radar Pillar Architecture:為雷達定制的空間建模方式
RAPA 采用了專門面向雷達點云的 Pillar(柱狀)表示方式,在空間上對雷達回波進行結構化編碼,使其更適合深度網絡處理。
與 LiDAR 點云相比,雷達點云具有:
點數更少
分布更不均勻
噪聲與虛警更多
Pillar 架構在此基礎上,引入了 針對雷達信號統計特性的優化過濾機制,顯著提升有效信息密度。
Attention-based Deep Learning:讓模型“學會忽略噪聲”
RAPA 的核心算法是一套 基于注意力機制(Attention)的深度學習模型,其訓練完全基于 Deep Fusion AI 的 自有 4D 雷達數據集。
注意力機制在這里承擔的角色是:
動態區分 高價值回波 vs. 噪聲回波
在稀疏數據中聚焦于 關鍵目標區域
提升在復雜場景下的魯棒性
這種設計,使模型不再被動接受雷達的“原始不完美數據”,而是 主動學習雷達信號的物理與統計特性。
多普勒速度:雷達感知的“殺手級維度”
RAPA 充分利用了雷達區別于其他傳感器的獨特優勢——多普勒速度信息。
通過速度維度,RAPA 能夠:
精準區分靜態目標與動態目標
在目標檢測與跟蹤階段顯著降低誤檢
在擁擠或弱紋理場景中保持穩定感知
在公開基準測試(public benchmarks)中,RAPA 在目標檢測與跟蹤任務上的整體準確率,相比同類方案提升超過 40%,這一提升主要來自對多普勒信息的深度建模與利用。
實時性與工程落地:為邊緣平臺而生
在性能之外,RAPA 的另一個關鍵價值在于 工程可落地性:
可在邊緣嵌入式平臺上高效運行
滿足自動駕駛與機器人對 實時性(real-time) 的嚴格要求
不依賴高功耗 GPU 或昂貴傳感器組合
這使其在成本、功耗與系統復雜度上具備明顯優勢。
應用場景:不止于自動駕駛汽車
雖然 RAPA 的核心應用場景是自動駕駛汽車(AV),但其雷達原生架構也天然適用于更多平臺:
自動駕駛車輛(AV)
成本敏感型 L2+/L3/L4 系統
無人水面艇(USV)
低能見度、復雜反射環境
機器人與移動平臺
室外全天候運行需求
在這些場景中,雷達往往比視覺更可靠,而 RAPA 則為其提供了“單獨成立”的算法基礎。
技術意義:雷達從“備胎”走向“主感知”
從行業角度看,RAPA 的意義不只是一次算法性能提升,而在于它驗證了一個重要方向:
通過為雷達量身定制的數據表示與注意力模型,雷達可以成為主感知傳感器,而非 LiDAR 的低配替代。
在自動駕駛產業面臨 成本壓力、規模化部署與冗余安全 多重挑戰的當下,這一方向具有極強的現實價值。
總結:一次雷達感知范式的躍遷
RAPA 之所以能夠獲得 CES 2026 人工智能類 Best of Innovation,本質原因在于它完成了三件難度極高的事情:
正視雷達數據的缺陷,而非回避
在模型結構上真正“為雷達而設計”
在實時性、精度與成本之間取得工程級平衡
如果說過去的雷達感知更多是“補充視覺與 LiDAR 的保險層”,那么 RAPA 展示的,是雷達作為 獨立、可規模化主感知方案 的現實可能性。
在自動駕駛、無人系統與機器人持續擴展的未來,這種 雷達原生 + 注意力驅動 的感知架構,極有可能成為下一階段的重要技術分支。





評論