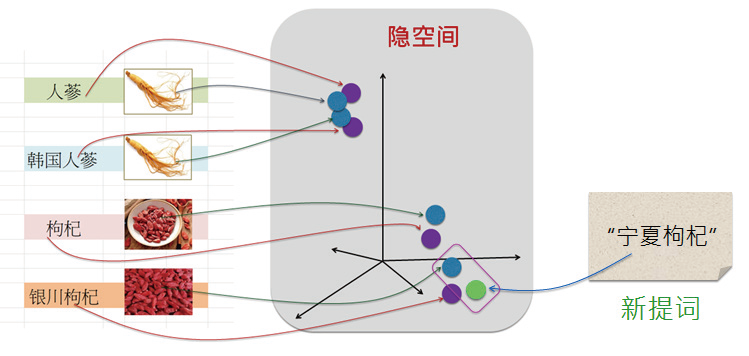
- 1 前言AIGC可生成的內容形式包含文本( 文句)、圖像、音頻和視頻。它能將文本中的語言符號信息或知識,與視覺中可視化的信息( 或知識) 建立出對應的關聯。兩者互相加強,形成圖文并茂的景象,激發人腦更多想象,擴大人們的思維空間。其中,最基礎的就是文本(Text) 與圖像(Image) 之間的知識關聯。本篇來介紹文本與圖像的關聯,并以CLIP 模型為例,深入介紹多模態AIGC 模型的幕后架構,例如隱空間(Latent space) 就是其中的關鍵性機制。2 簡介CLIP模型在2020 年,OpenAI 團隊
- 關鍵字:
202305 從隱空間 CLIP多模態模型
從隱空間介紹
您好,目前還沒有人創建詞條從隱空間!
歡迎您創建該詞條,闡述對從隱空間的理解,并與今后在此搜索從隱空間的朋友們分享。
創建詞條
關于我們 -
廣告服務 -
企業會員服務 -
網站地圖 -
聯系我們 -
征稿 -
友情鏈接 -
手機EEPW
Copyright ?2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《電子產品世界》雜志社 版權所有 北京東曉國際技術信息咨詢有限公司

京ICP備12027778號-2 北京市公安局備案:1101082052 京公網安備11010802012473