一種用于抗噪語音識別的動態參數補償新方法

3.2 協方差補償
同樣根據(10)和相關假設,可以獲得對數譜域的帶噪語音特征的協方差補償算法。本文引用地址:http://cqxgywz.com/article/188936.htm
![]()
其中
且
附加隨機變量Zkl的引入以及附加隨機變量與語音和噪聲的動態特征不相關假設的使用降低了動態模型補償問題的求解維數。這種維數的降低同Gauss-Hermite數字積分的應用,使得新的DPCM成為一種十分有效的動態模型補償方法。
4 算法評估
算法評估實驗采用基于孤立字的6狀態HMM來做識別器。每個狀態有4個高斯密度函數。選取24個MFCC(12個靜態特征,12個動態特征)作為語音特征。訓練階段,用純凈語音訓練出純凈語音模型。在識別階段,使用純凈語音模型作為基本模型來識別。
使用TI―digits為算法評估語音庫,選用數據庫中有16個人(8男8女)的5081個短句,其中包含20個孤立詞,數字‘0’到‘9’和10個附加命令如‘go’、‘help’、‘repeate’等。訓練集含有641句,測試集包括5081句。算法分析窗口的長度為32ms,幀速率為9.6ms/幀。選取NOISEX-92中的White、Pink和Destoryerengine 3種噪聲作為評估的環境噪聲。使用200幀非重疊的噪聲來估計噪聲模型。全局信噪比定義為:
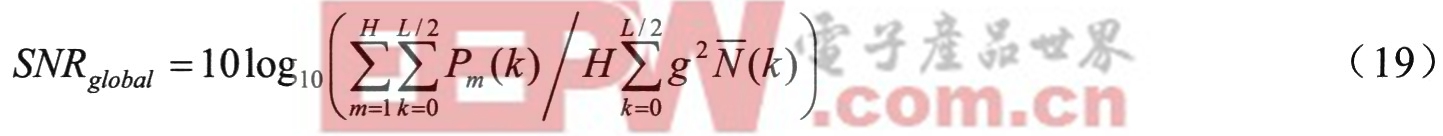
其中Pm(k)是第m幀的純凈語音功率普,N(k)是估計的噪聲能量平均譜,H是每句的語音幀數,L是FFT的長度,g是縮放因子讓所加的噪聲符合指定的全局信噪比。帶噪語音由(20)生成。
![]()
其中y(i)是帶噪語音,x(i)和n(i)分別是純凈語音和噪聲。對于文中語音的動態特征參數是依據(21)獲得。
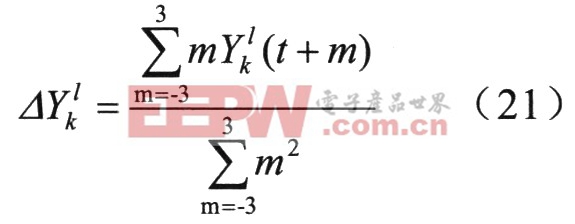
為了比較DPCM方法的性能,采用5種識別方法:失配情況下的識別,Log―Add PMC,Log―Normal PMC,以及Log-AddPMC與Log―Normal PMC和DPCM相結合的方法。
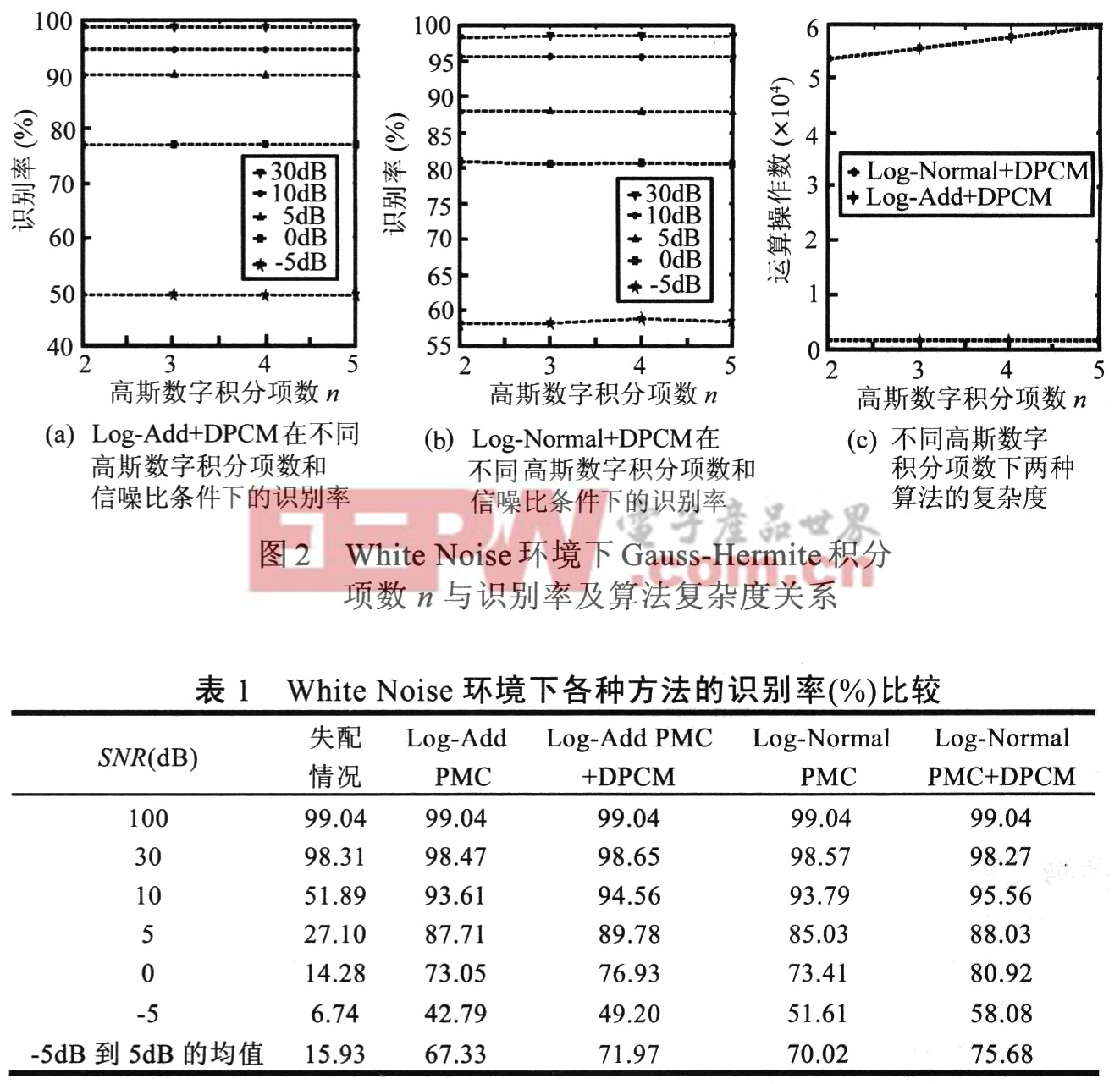
圖2給出了White Noise環境下Gauss―Hermite積分項數n與識別率及算法復雜度關系。從圖中可以看出隨著積分項n的增加,兩種方法的識別率都沒有明顯的變化。但是算法的復雜度卻隨著n的增加而增加。結果說明n=2的Gauss―Hermite積分可以提供足夠的計算精度。因此在DPCM 中采用n=2, 即





評論