基于OMAP的MPEG—4實時解碼器的實現(xiàn)

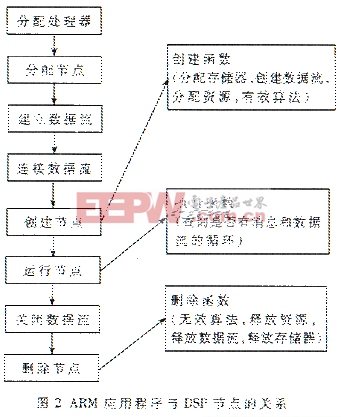 2.2 在OMAPl510上的程序結(jié)構(gòu) 在OMAP上開發(fā)程序通常分為兩部分,一部分是使用Embedded Visual C開發(fā)ARM端程序,另一部分是使用TI CCS開發(fā)DSP端程序。前者主要是為了使設計的算法與xDAIS(eXpressDSP TM算法標準)兼容,在ARM端程序中調(diào)用一些DSP/BIOS橋的API實現(xiàn)在DSP上初始化信號處理任務、與DSP任務交換消息、對來自DSP和從DSP發(fā)出的數(shù)據(jù)流進行緩沖、暫停、繼續(xù)、刪除DSP任務并進行資源狀態(tài)查詢等。而具體的功能實現(xiàn)則是在DSP端完成。圖2顯示了TI-enhanced ARM925應用程序與DSP節(jié)點之間的關系。 通過寫節(jié)點封裝器的創(chuàng)建、執(zhí)行及刪除函數(shù),將xDAIS算法封裝于DSP節(jié)點中。創(chuàng)建函數(shù)可分配節(jié)點處理和xDAIS算法所需的存儲器,還可分配節(jié)點的相關模塊。這些模塊是傳遞到執(zhí)行和刪除函數(shù)的一種結(jié)構(gòu)。創(chuàng)建函數(shù)還可給出xDAIS算法的實例,并可將其激活,還可初始化任何在任務執(zhí)行前必須初始化的數(shù)據(jù)或參數(shù)。執(zhí)行函數(shù)是主要的分派函數(shù),在此函數(shù)執(zhí)行階段中一般不分配存儲器及其它資源。執(zhí)行函數(shù)一般包括消息處理循環(huán),該循環(huán)可中斷函數(shù)并等待來自ARM925的消息或數(shù)據(jù)流,然后節(jié)點將這些消息或數(shù)據(jù)分派到合適的xDAIS控制或處理任務中去。同時執(zhí)行函數(shù)查詢DSP/BIOS橋所發(fā)送的指示函數(shù)退出循環(huán)的特殊消息,然后檢查定制消息或流數(shù)據(jù),并對這些消息或數(shù)據(jù)流進行適當處理。刪除函數(shù)清空創(chuàng)建函數(shù)所分配的資源,包括相關模塊和數(shù)據(jù)流。刪除函數(shù)還必須關閉算法、釋放存儲器以及分配給節(jié)點的其它資源。 2.3 程序的優(yōu)化考慮 (1)合理分配存儲位置。TMS320C55x的片內(nèi)存儲器容量小而存取速度快,片外存儲器容量大但存取速度慢。在分配存儲器的時候應考慮到這個特點合理地安排程序各部分。對于那些使用頻繁的變量應考慮放在片內(nèi),如VLC表、運動矢量、反量化、反DCT的系數(shù)以及其它中間變量都應放在片內(nèi),而對于那些執(zhí)行次數(shù)比較少或者比較大的變量如參考幀和當前解碼出的幀則應該放在片外。此外由于編譯和分配空間是以文件為單位的,所以應當把使用頻繁的函數(shù)盡量放在相同的幾個文件中,再將這幾個文件放入片內(nèi)存儲器以高效地利用有限的片內(nèi)資源。 (2)數(shù)據(jù)傳輸?shù)墓芾怼τ谝曨l解碼工作來說,TMS320C55x的片內(nèi)存儲器資源不是很多,必須合理利用。例如一幀4∶2∶0的QCIF(176x144)圖像,如果以緊湊的方式(2個字節(jié)存到一個16bit的字中)存放也需要18K字。因此不可能在解碼時把一整幀都放在片內(nèi),而應考慮使用DMA在需要時把圖像的一部分傳入片內(nèi)進行處理。此外,為了使CPU訪問和DMA傳輸同時無沖突地進行,將數(shù)據(jù)訪問設計成乒乓結(jié)構(gòu)。在解I幀時片內(nèi)準備兩個大小為一宏塊行的存儲區(qū)用于存放YUV數(shù)據(jù),CPU將解碼的一宏塊行數(shù)據(jù)放在其中一塊后,DMA把這一宏塊行的數(shù)據(jù)傳輸?shù)狡鈱奈恢茫瑫rCPU解下一宏塊行的數(shù)據(jù)并將結(jié)果放在另外一塊存儲區(qū),DMA再傳送此塊的數(shù)據(jù),如此反復執(zhí)行。選擇兩宏塊行大小的原因是不能使用片內(nèi)太多的存儲器資源,同時如果每次解碼傳輸?shù)臄?shù)據(jù)太少將過于頻繁地啟動DMA,導致效率下降,折衷考慮決定在片內(nèi)為解碼數(shù)據(jù)開辟兩宏塊行大小的緩存。而在解P幀的時候因為要先讀入?yún)⒖紟哪承?shù)據(jù)所以更為復雜。在片內(nèi)開辟兩塊緩存,用以存放對Inter宏塊進行運動補償所需的參考幀中對應搜索范圍內(nèi)的數(shù)據(jù),同時準備兩個宏塊大小的片內(nèi)空間用于存放當前宏塊解碼的結(jié)果(為描述方便稱為M1和M2)。此時需要使用兩個DMA通道,通道1負責將解當前宏塊進行運動補償時所需的參考幀部分數(shù)據(jù)讀到片內(nèi)緩存中,通道2負責將解碼的數(shù)據(jù)傳輸?shù)狡鈱目臻g。先啟動通道1讀所需參考幀數(shù)據(jù)到緩存1,CPU用這些數(shù)據(jù)和讀人的碼流對Inter宏塊進行運動補償解出當前宏塊的數(shù)據(jù)放入M1,同時通道1讀下一宏塊所需的參考幀數(shù)據(jù)到緩存2。之后CPU、通道1、通道2并行工作,CPU利用緩存2的數(shù)據(jù)解下一宏塊放入M2,通道1再讀數(shù)據(jù)到緩存1中,通道2將解碼的數(shù)據(jù)從M1傳輸?shù)狡鈱目臻g,如此循環(huán),P幀利用DMA解碼如圖3所示。
2.2 在OMAPl510上的程序結(jié)構(gòu) 在OMAP上開發(fā)程序通常分為兩部分,一部分是使用Embedded Visual C開發(fā)ARM端程序,另一部分是使用TI CCS開發(fā)DSP端程序。前者主要是為了使設計的算法與xDAIS(eXpressDSP TM算法標準)兼容,在ARM端程序中調(diào)用一些DSP/BIOS橋的API實現(xiàn)在DSP上初始化信號處理任務、與DSP任務交換消息、對來自DSP和從DSP發(fā)出的數(shù)據(jù)流進行緩沖、暫停、繼續(xù)、刪除DSP任務并進行資源狀態(tài)查詢等。而具體的功能實現(xiàn)則是在DSP端完成。圖2顯示了TI-enhanced ARM925應用程序與DSP節(jié)點之間的關系。 通過寫節(jié)點封裝器的創(chuàng)建、執(zhí)行及刪除函數(shù),將xDAIS算法封裝于DSP節(jié)點中。創(chuàng)建函數(shù)可分配節(jié)點處理和xDAIS算法所需的存儲器,還可分配節(jié)點的相關模塊。這些模塊是傳遞到執(zhí)行和刪除函數(shù)的一種結(jié)構(gòu)。創(chuàng)建函數(shù)還可給出xDAIS算法的實例,并可將其激活,還可初始化任何在任務執(zhí)行前必須初始化的數(shù)據(jù)或參數(shù)。執(zhí)行函數(shù)是主要的分派函數(shù),在此函數(shù)執(zhí)行階段中一般不分配存儲器及其它資源。執(zhí)行函數(shù)一般包括消息處理循環(huán),該循環(huán)可中斷函數(shù)并等待來自ARM925的消息或數(shù)據(jù)流,然后節(jié)點將這些消息或數(shù)據(jù)分派到合適的xDAIS控制或處理任務中去。同時執(zhí)行函數(shù)查詢DSP/BIOS橋所發(fā)送的指示函數(shù)退出循環(huán)的特殊消息,然后檢查定制消息或流數(shù)據(jù),并對這些消息或數(shù)據(jù)流進行適當處理。刪除函數(shù)清空創(chuàng)建函數(shù)所分配的資源,包括相關模塊和數(shù)據(jù)流。刪除函數(shù)還必須關閉算法、釋放存儲器以及分配給節(jié)點的其它資源。 2.3 程序的優(yōu)化考慮 (1)合理分配存儲位置。TMS320C55x的片內(nèi)存儲器容量小而存取速度快,片外存儲器容量大但存取速度慢。在分配存儲器的時候應考慮到這個特點合理地安排程序各部分。對于那些使用頻繁的變量應考慮放在片內(nèi),如VLC表、運動矢量、反量化、反DCT的系數(shù)以及其它中間變量都應放在片內(nèi),而對于那些執(zhí)行次數(shù)比較少或者比較大的變量如參考幀和當前解碼出的幀則應該放在片外。此外由于編譯和分配空間是以文件為單位的,所以應當把使用頻繁的函數(shù)盡量放在相同的幾個文件中,再將這幾個文件放入片內(nèi)存儲器以高效地利用有限的片內(nèi)資源。 (2)數(shù)據(jù)傳輸?shù)墓芾怼τ谝曨l解碼工作來說,TMS320C55x的片內(nèi)存儲器資源不是很多,必須合理利用。例如一幀4∶2∶0的QCIF(176x144)圖像,如果以緊湊的方式(2個字節(jié)存到一個16bit的字中)存放也需要18K字。因此不可能在解碼時把一整幀都放在片內(nèi),而應考慮使用DMA在需要時把圖像的一部分傳入片內(nèi)進行處理。此外,為了使CPU訪問和DMA傳輸同時無沖突地進行,將數(shù)據(jù)訪問設計成乒乓結(jié)構(gòu)。在解I幀時片內(nèi)準備兩個大小為一宏塊行的存儲區(qū)用于存放YUV數(shù)據(jù),CPU將解碼的一宏塊行數(shù)據(jù)放在其中一塊后,DMA把這一宏塊行的數(shù)據(jù)傳輸?shù)狡鈱奈恢茫瑫rCPU解下一宏塊行的數(shù)據(jù)并將結(jié)果放在另外一塊存儲區(qū),DMA再傳送此塊的數(shù)據(jù),如此反復執(zhí)行。選擇兩宏塊行大小的原因是不能使用片內(nèi)太多的存儲器資源,同時如果每次解碼傳輸?shù)臄?shù)據(jù)太少將過于頻繁地啟動DMA,導致效率下降,折衷考慮決定在片內(nèi)為解碼數(shù)據(jù)開辟兩宏塊行大小的緩存。而在解P幀的時候因為要先讀入?yún)⒖紟哪承?shù)據(jù)所以更為復雜。在片內(nèi)開辟兩塊緩存,用以存放對Inter宏塊進行運動補償所需的參考幀中對應搜索范圍內(nèi)的數(shù)據(jù),同時準備兩個宏塊大小的片內(nèi)空間用于存放當前宏塊解碼的結(jié)果(為描述方便稱為M1和M2)。此時需要使用兩個DMA通道,通道1負責將解當前宏塊進行運動補償時所需的參考幀部分數(shù)據(jù)讀到片內(nèi)緩存中,通道2負責將解碼的數(shù)據(jù)傳輸?shù)狡鈱目臻g。先啟動通道1讀所需參考幀數(shù)據(jù)到緩存1,CPU用這些數(shù)據(jù)和讀人的碼流對Inter宏塊進行運動補償解出當前宏塊的數(shù)據(jù)放入M1,同時通道1讀下一宏塊所需的參考幀數(shù)據(jù)到緩存2。之后CPU、通道1、通道2并行工作,CPU利用緩存2的數(shù)據(jù)解下一宏塊放入M2,通道1再讀數(shù)據(jù)到緩存1中,通道2將解碼的數(shù)據(jù)從M1傳輸?shù)狡鈱目臻g,如此循環(huán),P幀利用DMA解碼如圖3所示。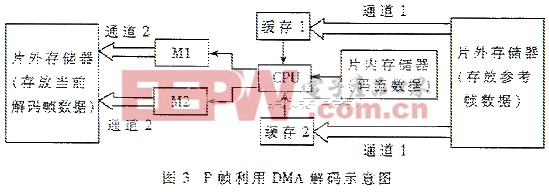 (3)使用TI提供的IMCLIB庫函數(shù)。IMCLIB是專門為圖像處理和視頻提供的庫,用來提高視頻處理速度。這些庫函數(shù)中有的是軟件庫函數(shù),是用匯編寫成的高效代碼例如反量化函數(shù)IMG_dequantiZe_8x8等;有的則是硬件庫函數(shù),它們利用OMAPl510芯片中一些專門為視頻編解碼的硬件加速模塊來處理數(shù)據(jù),如利用反DCT模塊的IMG_idct_8x8等,這些函數(shù)處理數(shù)據(jù)的速度更快,效率更高。在使用某些庫函數(shù)的時候需要按照其接口的要求調(diào)整。 (4)使用DSP內(nèi)部固定的intrinsics指令,這些指令主要執(zhí)行一些簡單的算術操作,由于它們是由優(yōu)化的匯編代碼寫成,因而使用它們可以提高代碼執(zhí)行的效率。 (5)其它一些優(yōu)化考慮和措施。為了使程序的效率更高,采用了一些代碼優(yōu)化的措施,例如將一些循環(huán)內(nèi)部展開,特別是對多重循環(huán)的控制,如果外層循環(huán)較少,可將內(nèi)層循環(huán)展開,把轉(zhuǎn)移條件結(jié)合起來,以減少內(nèi)層與外層之間的相互聯(lián)系,減少判斷轉(zhuǎn)移并實現(xiàn)并行操作。又如利用DMA來代替原有的復制函數(shù)、為方便將浮點數(shù)定點化、使用移位操作代替乘除法等。此外,在應用到多媒體通信中,采用支持數(shù)據(jù)分割的方法來有效控制無線通信中可能產(chǎn)生的誤碼。 3 測試結(jié)果 使用QCIF(176%26;#215;144)的兩測試碼流foreman和car-phone(各編碼100幀)在使用數(shù)據(jù)分割和沒使用數(shù)據(jù)分割的情況下得到的解碼速度(包括顯示部分)如表1所示。表1 測試結(jié)果 使用數(shù)據(jù)分割沒使用數(shù)據(jù)分割foreman25.2fps27.9fpscarphone27.4fps29.9fps從表1可以看出,本文提出的方法基本上能夠滿足MPEG—4實時解碼的需求,即使對比較復雜的使用數(shù)據(jù)分割的序列,仍能達到25幀/秒(fps)以上,圖像的質(zhì)量也比較好,因此適合在無線終端實現(xiàn)多媒體的應用。 OMAP平臺因其獨有的雙核結(jié)構(gòu)和為無線應用提供了一個強大的軟硬件基礎。本文結(jié)合其在MPEC—4解碼中應用的實例,具體闡述了OMAP1510的軟件優(yōu)化開發(fā)方法,并基本上實現(xiàn)了實時解碼,希望能對使用OMAP或準備使用的開發(fā)人員具有借鑒意義。
(3)使用TI提供的IMCLIB庫函數(shù)。IMCLIB是專門為圖像處理和視頻提供的庫,用來提高視頻處理速度。這些庫函數(shù)中有的是軟件庫函數(shù),是用匯編寫成的高效代碼例如反量化函數(shù)IMG_dequantiZe_8x8等;有的則是硬件庫函數(shù),它們利用OMAPl510芯片中一些專門為視頻編解碼的硬件加速模塊來處理數(shù)據(jù),如利用反DCT模塊的IMG_idct_8x8等,這些函數(shù)處理數(shù)據(jù)的速度更快,效率更高。在使用某些庫函數(shù)的時候需要按照其接口的要求調(diào)整。 (4)使用DSP內(nèi)部固定的intrinsics指令,這些指令主要執(zhí)行一些簡單的算術操作,由于它們是由優(yōu)化的匯編代碼寫成,因而使用它們可以提高代碼執(zhí)行的效率。 (5)其它一些優(yōu)化考慮和措施。為了使程序的效率更高,采用了一些代碼優(yōu)化的措施,例如將一些循環(huán)內(nèi)部展開,特別是對多重循環(huán)的控制,如果外層循環(huán)較少,可將內(nèi)層循環(huán)展開,把轉(zhuǎn)移條件結(jié)合起來,以減少內(nèi)層與外層之間的相互聯(lián)系,減少判斷轉(zhuǎn)移并實現(xiàn)并行操作。又如利用DMA來代替原有的復制函數(shù)、為方便將浮點數(shù)定點化、使用移位操作代替乘除法等。此外,在應用到多媒體通信中,采用支持數(shù)據(jù)分割的方法來有效控制無線通信中可能產(chǎn)生的誤碼。 3 測試結(jié)果 使用QCIF(176%26;#215;144)的兩測試碼流foreman和car-phone(各編碼100幀)在使用數(shù)據(jù)分割和沒使用數(shù)據(jù)分割的情況下得到的解碼速度(包括顯示部分)如表1所示。表1 測試結(jié)果 使用數(shù)據(jù)分割沒使用數(shù)據(jù)分割foreman25.2fps27.9fpscarphone27.4fps29.9fps從表1可以看出,本文提出的方法基本上能夠滿足MPEG—4實時解碼的需求,即使對比較復雜的使用數(shù)據(jù)分割的序列,仍能達到25幀/秒(fps)以上,圖像的質(zhì)量也比較好,因此適合在無線終端實現(xiàn)多媒體的應用。 OMAP平臺因其獨有的雙核結(jié)構(gòu)和為無線應用提供了一個強大的軟硬件基礎。本文結(jié)合其在MPEC—4解碼中應用的實例,具體闡述了OMAP1510的軟件優(yōu)化開發(fā)方法,并基本上實現(xiàn)了實時解碼,希望能對使用OMAP或準備使用的開發(fā)人員具有借鑒意義。











評論