摘要:研究了分形編碼過程中值域塊與定義域塊相似程度的分布特點,提出利用代間差分遺傳算法優化其編碼速度。實驗結果證明了該方法的有效性。關鍵詞:圖像壓縮 分形編碼 遺傳算法 分形圖像壓縮技術是利用數字圖像本身固有的自相似性,在分形理論的指導下,把圖像數據轉變為相關的分形參數,從而達到對數據進行壓縮的目的。在一些情況下分形壓縮可以達到非常高的壓縮比,因此這是一種極具發展潛力的圖像壓縮技術。 分形圖像壓縮的概念首先由Barnsley提出,但是Barnsely基于IFS的分形壓縮方法在實話時需要人機交互,無法實現自動化的壓縮過程。1990年,Janquin利用局部仿射變換代替全局仿射變換而提出了一種全自動的分形圖像壓縮方法,使這種圖像壓縮技術向實用化邁進一了步。Janquin方式雖然解決了Barnsley的子圖分割問題,但是搜索最佳匹配塊的計算量是十分可觀的。為了減小計算量,從90年代起又有許多改進方法被提出,例如分類搜索法、四叉樹搜索法等。這些方法雖然在一定程度上節約了搜索時間,但仍需進一步減小編碼所需要的時間。 遺傳算法是人類在自然進化的啟發下發展的一種隨機搜索算法,在大計算量面前具有快速自尋優的能力。目前人們已經開始利用遺傳算法對分形編碼的編碼速度進行優化。本文為了進一步提高分形壓縮的編碼速度,深入研究了每個值域塊、所有定義域塊與其相似程度的分布特點,推導了適用于分形編碼的代間差分遺傳算法;然后利用代間差分遺傳算法優化分形編碼。實驗表明代間差分遺傳算法較變通遺傳算法具有更快的收斂速度。 1 分形圖像壓縮的基本原理 分形理論是現代非線性科學中一門非常活躍且應用十分廣泛的學科,特別隨著計算機技術的發展,分形思想和方法在模式識別、自然圖像的模擬、信號處理等各個領域都取得了巨大的成功。 分形編碼的主要過程如下:首先將圖像I分割成互不相交的值域塊{Ri},對每個值域塊,在整個圖像范圍尋找其在壓縮、仿射變換下的最佳匹配定義域塊Di,記錄下該定義域塊和所采用的變換,完成了一個子塊的編碼;對于所有值域塊{Ri}重復上述過程分別尋找各自的最優匹配定義域塊,即完成整幅圖像的編碼。 在仿射變換下,定義域和值域的誤差可由下式確定: 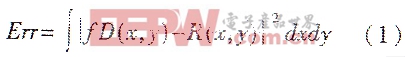 所謂某個值域塊Ri的最優匹配定義域就是:在f映射下,定義域塊和值域塊使(1)式最小。利用Janquin方法進行編碼,為了找到具有最小誤差Err的定義域塊,即最優匹配定義域塊,每一個值域塊Ri需要匹配的定義域塊數為(假設圖像、定義域塊以及值域塊都是正方形): Num=(圖像大小-定義域塊大小+1)2%26;#215;仿射變換種數 例如,對于一個大小為256%26;#215;256的圖像,如果選取值域塊為16%26;#215;16,定義塊為32%26;#215;32,則每個值域塊要搜索的定義域塊為50625。可見該匹配過程的計算量非常大。 2 代間差分遺傳算法的基本思想 遺傳算法是一種具有內在并行性的優化算法,本文試圖利用遺傳算法的優化能力改善編碼過程。同時針對分形編碼過程的特點,為了提高算法的收斂速度,對遺傳算法進行了改進,提出了帶有代間差分雜交算子的遺傳算法。 遺傳算法中的雜交算子是一類非常重要的算子,雜交算子的性以也直接影響整個算法的收斂速度。本文提出的代間差分霜交算子其思想為:遺傳算法是根據自然界中生物進化、適者生存的思想而發展的一種優化算法;隨著種群進化代數的增加,在選擇算子等的作用下,種群的平均適應值將以大概率增加。這樣有理由假定種群的適應值將隨著進化代數的增加而單調增加,從相鄰兩代種群中隨機選擇一個個體,則兩個個體的差以一定概率代表了種群適應值增加的方向,也就是所希望的進化方向。因此可以利用相鄰兩代種群中個體的差來構成新的雜交算子,以產生新的個體,該新個體將以更高的概率向量優解靠近。
所謂某個值域塊Ri的最優匹配定義域就是:在f映射下,定義域塊和值域塊使(1)式最小。利用Janquin方法進行編碼,為了找到具有最小誤差Err的定義域塊,即最優匹配定義域塊,每一個值域塊Ri需要匹配的定義域塊數為(假設圖像、定義域塊以及值域塊都是正方形): Num=(圖像大小-定義域塊大小+1)2%26;#215;仿射變換種數 例如,對于一個大小為256%26;#215;256的圖像,如果選取值域塊為16%26;#215;16,定義塊為32%26;#215;32,則每個值域塊要搜索的定義域塊為50625。可見該匹配過程的計算量非常大。 2 代間差分遺傳算法的基本思想 遺傳算法是一種具有內在并行性的優化算法,本文試圖利用遺傳算法的優化能力改善編碼過程。同時針對分形編碼過程的特點,為了提高算法的收斂速度,對遺傳算法進行了改進,提出了帶有代間差分雜交算子的遺傳算法。 遺傳算法中的雜交算子是一類非常重要的算子,雜交算子的性以也直接影響整個算法的收斂速度。本文提出的代間差分霜交算子其思想為:遺傳算法是根據自然界中生物進化、適者生存的思想而發展的一種優化算法;隨著種群進化代數的增加,在選擇算子等的作用下,種群的平均適應值將以大概率增加。這樣有理由假定種群的適應值將隨著進化代數的增加而單調增加,從相鄰兩代種群中隨機選擇一個個體,則兩個個體的差以一定概率代表了種群適應值增加的方向,也就是所希望的進化方向。因此可以利用相鄰兩代種群中個體的差來構成新的雜交算子,以產生新的個體,該新個體將以更高的概率向量優解靠近。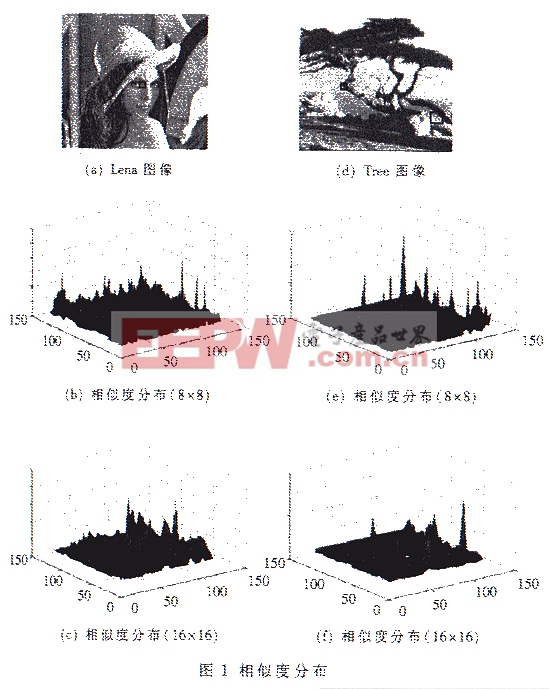 本文在不產生混淆的情況下,把采用代間差分雜交算子的遺傳算法稱為代間差分遺傳算法。 3 基于代間差分遺傳算法的快速分形壓縮算法 3.1 分形編碼中值域塊與定義域塊相似度分布特點 筆者經過大量的研究發現,在分形編碼的過程中某一值域塊與所有定義域塊的相似程度分布具有以下特點: (1) 該分布是一個多極值的函數,因此尋找某一值域塊的最佳匹配定義域塊的過程實際上是求解一個多極值函數的最大值問題; (2) 分布函數的取值在每一個極值附近連續變化,即在最大相似塊附近的定義域塊,(5) 其與值域塊的相似度是逐漸變化的。 圖1是Lena圖像和Tree圖像中某一值域塊與所有定義域塊相似度分布的情況,值域塊分8%26;#215;8和16%26;#215;16兩種情況隨機選取,相似度由(2)式確定: ada=1/Err (2) 其中,Err由(1)式確定。 相似度的分布由圖1(b)、(c)和圖1(e)、(f)給出,可以看到,相似度的分布符合上述兩個特點。 3.2 構造代間差分雜算子 由于分形編碼中值域塊與定義域塊相似度分布具有以上特點,使得代間差分遺傳算法的思想在這里適用,因此可以利用代間差分遺傳算法優化分形編碼過程。下面構造可用于分形編碼過程的代間差分雜交算子。 本文要進行搜索的空間由圖像定義域塊的全體構成,對于每個定義塊可以用左上角像素點的坐標表示,則對應的遺傳算法中的一個個體可以表示為:x=(x,y)。種群中個體的適應度由(3)式確定。 代間差分雜交算子可以表示為:
本文在不產生混淆的情況下,把采用代間差分雜交算子的遺傳算法稱為代間差分遺傳算法。 3 基于代間差分遺傳算法的快速分形壓縮算法 3.1 分形編碼中值域塊與定義域塊相似度分布特點 筆者經過大量的研究發現,在分形編碼的過程中某一值域塊與所有定義域塊的相似程度分布具有以下特點: (1) 該分布是一個多極值的函數,因此尋找某一值域塊的最佳匹配定義域塊的過程實際上是求解一個多極值函數的最大值問題; (2) 分布函數的取值在每一個極值附近連續變化,即在最大相似塊附近的定義域塊,(5) 其與值域塊的相似度是逐漸變化的。 圖1是Lena圖像和Tree圖像中某一值域塊與所有定義域塊相似度分布的情況,值域塊分8%26;#215;8和16%26;#215;16兩種情況隨機選取,相似度由(2)式確定: ada=1/Err (2) 其中,Err由(1)式確定。 相似度的分布由圖1(b)、(c)和圖1(e)、(f)給出,可以看到,相似度的分布符合上述兩個特點。 3.2 構造代間差分雜算子 由于分形編碼中值域塊與定義域塊相似度分布具有以上特點,使得代間差分遺傳算法的思想在這里適用,因此可以利用代間差分遺傳算法優化分形編碼過程。下面構造可用于分形編碼過程的代間差分雜交算子。 本文要進行搜索的空間由圖像定義域塊的全體構成,對于每個定義塊可以用左上角像素點的坐標表示,則對應的遺傳算法中的一個個體可以表示為:x=(x,y)。種群中個體的適應度由(3)式確定。 代間差分雜交算子可以表示為:  其中[%26;#183;]表示取整函數,α、β、λ為小于1的正常數。xnbest、xn-1best分別是第n代和n-1代中適應度最好的個體。又按下式計算個體x:
其中[%26;#183;]表示取整函數,α、β、λ為小于1的正常數。xnbest、xn-1best分別是第n代和n-1代中適應度最好的個體。又按下式計算個體x:  即在新種群產生后,又進行如下操作:從新種群中隨機選擇一個個體,如果該個體適應度比x好,則保持不變,否則用x代替該個體。(4)式中α、λ的取值可以與(3)式相同也可以不同,本文中取值相同。 3.3 式間差分遺傳算法的實現 設種群的規模為N,則代間差分遺傳算法的基本結構為: { 分配三代進化種群的內存匹配,其內存指針分別用pt-1,p+1表示; t=1;隨機初始化種群pt-1,pt,pt+1; 計算pt-1,pt中個體的適應值;] while(不滿足終止條件)do { 根據個體的適應值及選擇策略,計算丙代種群pt-1,pt內個體的選擇概率pi; 復制pt中適應值最好的個體到pt+1中; while(pt+1中的個體全部被更新)do { 從pt-1,pt中隨機選擇一個個體,按雜交概率用代間差分雜交算子產生新個體; 按變異概率用變異算子作用新個體; } 計算pt+1中個體的適應值; 按(3)式計算xi并計算xi的適應值,從Pi+1中隨機選擇x(t+1)l; 如果xi的適應值比x(t+1)l好,則把xi復制到x(t+1)l在Pt+1中的位置;否則保持不變; pTmp=pt-1; pt-1=pt; pt=pTmp; t=t+1; } }
即在新種群產生后,又進行如下操作:從新種群中隨機選擇一個個體,如果該個體適應度比x好,則保持不變,否則用x代替該個體。(4)式中α、λ的取值可以與(3)式相同也可以不同,本文中取值相同。 3.3 式間差分遺傳算法的實現 設種群的規模為N,則代間差分遺傳算法的基本結構為: { 分配三代進化種群的內存匹配,其內存指針分別用pt-1,p+1表示; t=1;隨機初始化種群pt-1,pt,pt+1; 計算pt-1,pt中個體的適應值;] while(不滿足終止條件)do { 根據個體的適應值及選擇策略,計算丙代種群pt-1,pt內個體的選擇概率pi; 復制pt中適應值最好的個體到pt+1中; while(pt+1中的個體全部被更新)do { 從pt-1,pt中隨機選擇一個個體,按雜交概率用代間差分雜交算子產生新個體; 按變異概率用變異算子作用新個體; } 計算pt+1中個體的適應值; 按(3)式計算xi并計算xi的適應值,從Pi+1中隨機選擇x(t+1)l; 如果xi的適應值比x(t+1)l好,則把xi復制到x(t+1)l在Pt+1中的位置;否則保持不變; pTmp=pt-1; pt-1=pt; pt=pTmp; t=t+1; } } 4 實驗結果 為了驗證代間差分遺傳算法在分形編碼中的有效性,利用常規遺傳算法和代間差分遺傳算法同時對Janquin編碼方法進行優化,并比較優化結果。 需要特別指出的是,本文僅僅對anquin編碼方法的優化進行了說明。實際上,代間差分遺傳算法同樣適用于其他改進的分形編碼算法,例如四叉樹搜索法等。 本文中兩種算法采用的參數如下:種群數目為50,雜交概率為0.8,遺傳概率為0.1,變異概率為0.1。 代間差分雜交算子的參數為: 用于其他改進的分形編碼算法,例如四叉樹搜索法等。 本文中兩種算法采用的參數如下:種群數目為50,雜交概率為0.8,遺傳概率為0.1,變異概率為0.1。 代間差分雜交算子的參數為: α=1, β=0.2, λ=0.8。 以256%26;#215;256的灰度Lena圖像為例進行實驗,值域塊為8%26;#215;8,定義域塊為16%26;#215;16。分別利用遺傳算法和代間差分遺傳算法對編碼過程進行優化,然后利用相同的解碼算法迭法10次進行解碼,圖2中給出了部分解碼的結果。 其中(a)是Lena原圖,(b)是直接利用Janquin編碼方法得到結果。 在進行實驗時,觀察在相同的進化代數的條件下,解碼圖像的PSNR的變化情況。由于 遺傳算法是一種隨機優化算法,所以在同一個進化代數利用兩種優化算法分別進行10計算,并計算解碼圖像的平均PSNR,如表1所示。其中最后一欄表示利用anquin方法解碼圖像的PSNR。 表1 實驗結果 4 6 12 16 20 J GA 22 23.5 25.4 26.1 26.4 28.2 IDGA 22.4 24 26.5 27 27.8 對表1進行分析可以知道,由于代間差分遺傳算法充分利用了值域塊相似度的分布特點,在相同的進化代數下,代間差分遺傳算法得到的PSNR比常規遺傳算法的PSNR大,說明對分形編碼進行優化計算時,前者比后者具有更高的收斂速度。
4 實驗結果 為了驗證代間差分遺傳算法在分形編碼中的有效性,利用常規遺傳算法和代間差分遺傳算法同時對Janquin編碼方法進行優化,并比較優化結果。 需要特別指出的是,本文僅僅對anquin編碼方法的優化進行了說明。實際上,代間差分遺傳算法同樣適用于其他改進的分形編碼算法,例如四叉樹搜索法等。 本文中兩種算法采用的參數如下:種群數目為50,雜交概率為0.8,遺傳概率為0.1,變異概率為0.1。 代間差分雜交算子的參數為: 用于其他改進的分形編碼算法,例如四叉樹搜索法等。 本文中兩種算法采用的參數如下:種群數目為50,雜交概率為0.8,遺傳概率為0.1,變異概率為0.1。 代間差分雜交算子的參數為: α=1, β=0.2, λ=0.8。 以256%26;#215;256的灰度Lena圖像為例進行實驗,值域塊為8%26;#215;8,定義域塊為16%26;#215;16。分別利用遺傳算法和代間差分遺傳算法對編碼過程進行優化,然后利用相同的解碼算法迭法10次進行解碼,圖2中給出了部分解碼的結果。 其中(a)是Lena原圖,(b)是直接利用Janquin編碼方法得到結果。 在進行實驗時,觀察在相同的進化代數的條件下,解碼圖像的PSNR的變化情況。由于 遺傳算法是一種隨機優化算法,所以在同一個進化代數利用兩種優化算法分別進行10計算,并計算解碼圖像的平均PSNR,如表1所示。其中最后一欄表示利用anquin方法解碼圖像的PSNR。 表1 實驗結果 4 6 12 16 20 J GA 22 23.5 25.4 26.1 26.4 28.2 IDGA 22.4 24 26.5 27 27.8 對表1進行分析可以知道,由于代間差分遺傳算法充分利用了值域塊相似度的分布特點,在相同的進化代數下,代間差分遺傳算法得到的PSNR比常規遺傳算法的PSNR大,說明對分形編碼進行優化計算時,前者比后者具有更高的收斂速度。







評論