基于DSP嵌入式說話人識別系統的設計

0 引 言
本文引用地址:http://cqxgywz.com/article/257627.htm說話人身份識別屬于生物認證技術的一種,是一項根據語音中反映說話人生理和行為特征的語音參數來自動識別說話人身份的技術。近年來,說話人身份識別以其獨特的方便性、經濟性和準確性等優勢受到矚目,在信息安全等領域的應用逐漸增大,并成為人們日常生活和工作中重要且普及的安全驗證方式。目前,說話人身份識別在理論上和實驗室條件下已經達到了比較高的識別精度,并開始走向實際應用階段。ATT、歐洲電信聯盟、ITT、Keyware、T-NETIX,Motorola和Vi-sa等公司相繼開展了相關實用化研究,國內這方面研究主要在中科聲學所,中科院自動化所,清華大學等研究所和大學中進行。
基于嵌入式的說話人身份識別系統具有高精度,適時性好,低功耗,低費用,體積小等優勢,逐漸成為說話人身份識別面向實際應用的新熱點。而隨著DSP新技術的發展,DSP芯片無論在處理速度、精度、功耗或者體積等方面都取得了突破性的進展。DSP也越來越多的應用于說話人身份識別。但目前這方面研究主要局限于小數據量、與PC機配套使用上,沒有太大的實用價值。在此介紹一種基于TMS320C6713 DSP芯片設計的嵌入式,10個人范圍的說話人身份識別系統。該系統可以自舉運行,并可靈活的選擇訓練、識別或者更換訓練者、識別者,識別率達98%以上。
1 系統的架構及硬件構成
系統總體實現流程如圖1所示。系統主要分為訓練和識別兩部分,系統初始化后由操作者控制訓練或識別。訓練目的是提取說話人模型參數并將其存儲在FLASH ROM中。識別目的是讀取待識別者語音信息并將獲得的模型參數與訓練的模型參數比較,從而獲得識別結果。
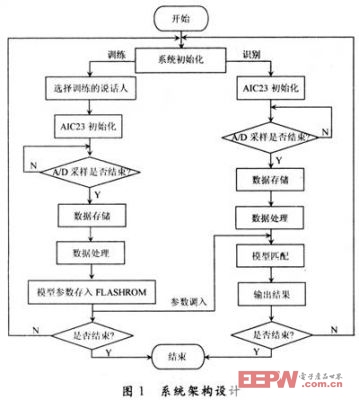
1.1 系統的主要硬件構成
系統硬件構成如圖2所示,主要包含語音采集模塊、數據處理模塊(DSP)、程序數據存儲及自舉FLASH模塊、數據存儲器RAM模塊、系統時序邏輯控制CPLD模塊、JTAG接口模塊。
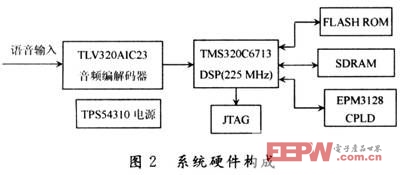
語音采集模塊主要由TLV320AIC23音頻編解碼器來完成,該芯片是TI公司的一款高性能的立體聲音頻Codec芯片,內置放大器,輸入/輸出增益可編程設置。模數,數/模轉換集成在一塊芯片中。采樣率8~96 kHz可編程實現。另外還具有低功耗,連接電路簡單,性價比高的特點。
語音處理DSP采用TI公司的TMS320C6713芯片,該芯片實現浮點運算,最高時鐘頻率225 MHz,使用該芯片外部存儲器接口可實現對外部存儲器(SDRAM)數據傳輸和程序存儲器(FLASH ROM)進行程序讀寫;依靠JTAG接口電路通過仿真器進行仿真調試,實現與主機數據交換;通過片內外設McBSP完成串行數據的接收和發送,實現對音頻處理模塊的控制等工作。
FLASH ROM最大可提供512 KB空間,通常為前256 KB可用。SDRAM最大容量為16 MB,為該系統提供較大的數據存儲空間。CPLD為存儲器的擴展實現邏輯編碼。電源為TPS54310芯片,可為系統提供3.3 V和1.26 V兩種電壓。







評論