基于FPGA的M2M異構虛擬化系統(二)

exe_mem_reg
本文引用地址:http://cqxgywz.com/article/201808/388222.htm本模塊完成EXE和MEM兩個階段之間的信號流水。本模塊的時序圖如下。
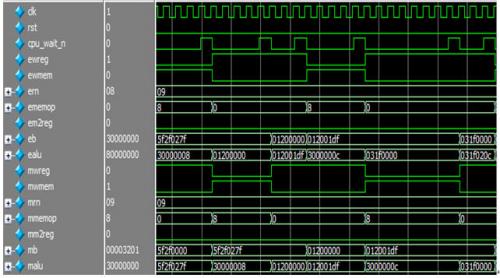
圖 22 exe_mem_reg時序圖
mem_stage
本模塊完成對數據Cache的讀寫。模塊的對外接口符合Wishbone總線標準。本模塊的主要時序如下圖。
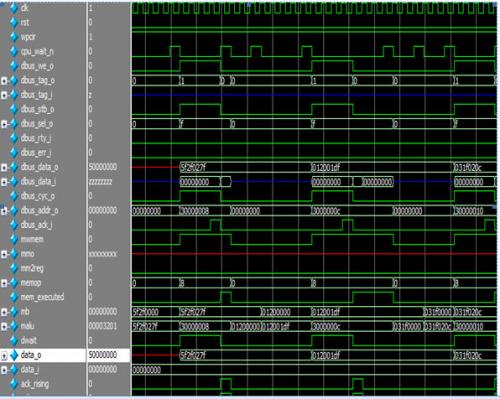
圖 23 mem_stage時序圖
mem_wb_reg
本模塊完成MEM和WB兩個階段之間的信號流水。本模塊的時序圖如下。

圖 24 mem_wb_reg時序圖
wb_stage
本模塊完成寫回指令的寄存器堆修改操作。本模塊的時序圖如下。

圖 25 wb_stage時序圖
except
本模塊完成流水線中的中斷及異常處理。為了完成精確中斷,即產生異常的指令前已經在流水線中的指令完成執行,而在異常指令后的指令不允許完成執行(不修改CPU狀態),才能響應異常。因此,在實現精確中斷時,需要對流水線中的指令進行跟蹤,所有的異常或中斷信號將延遲到流水線的特定階段(Writeback)進行響應,并且對不同類型的異常信號,中斷程序的返回地址不同。本模塊的主要時序圖如下。
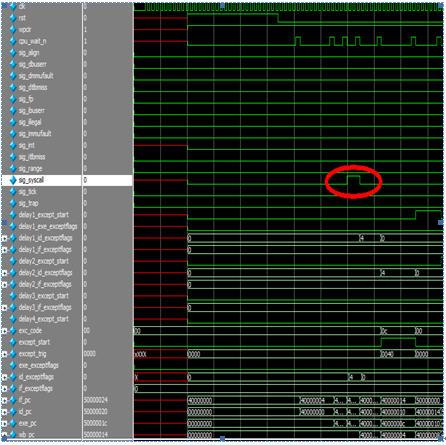
圖 26 except時序圖
4.1.2.2Cache模塊詳細設計方案
功能描述
本模塊實現指令Cache和數據Cache。其中,指令Cache和數據Cache的映射策略都采用直接映射方式。指令Cache只讀,數據Cache的寫策略為寫通過(主存和Cache里的數據時鐘保持一致)。
- 子模塊列表
Instruction Cache top | |
Data Cache top |
詳細設計
ic_top
本模塊的時序圖如下。
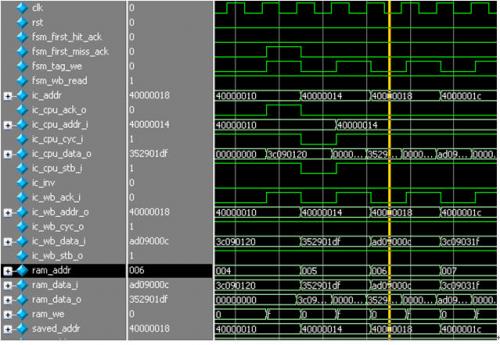
圖 27 ic_top時序圖
4.1.2.3動態翻譯硬件模塊詳細設計方案
功能描述
為了提高動態翻譯效率,我們在CPU中增加了硬件加速模塊。動態翻譯硬件加速包括以下部分:
在QS-I CPU的ALU模塊中增加x86 flag寄存器(MIPS架構中沒有flag標志寄存器),軟件可通過mtc0,mfc0兩條指令來訪問flag寄存器。這樣x86的算術邏輯或比較指令(如add, sub, cmp等),以及條件跳轉指令(如ja, jb, jg等)有效地得到了硬件支持,使得軟件的翻譯效率大大提高。
在QS-I CPU外增加了JLUT(Jump address Lookup Table),即跳轉地址查表。通過CAM(Content Address Memory)的硬件支持,跳轉指令的翻譯效率將比完全基于軟件的翻譯方式提高一個數量級。在QS-I中將新增4條用戶指令campi, ramri, camwi, camwi用于軟件對JLUT的訪問。
- 子模塊列表
JLUT top | ||
SPC is stored in CAMs, and it will take less than two clock cycles to get address of the CAMs content specified. | ||
TPC is stored in ubiquitous RAMs. |
詳細設計
如下方的JLUT詳細設計圖所示,JLUT模塊與QS-I CPU之間通過campi, camwi, ramwi, ramwi四條指令進行交互。
campi用于CAM的查表,camwi用于CAM的寫操作,ramwi用于RAM的寫操作,RAMRI用于RAM的讀操作。
4條指令的格式如下。
Instruction | Format | Usage |
campi | opcode, rs, 5’h0, rd, 5’h0, func | campi rd, rs |
camwi | opcode, rs, rt, 5’h0, 5’h0, func | camwi rt, rs |
ramwi | opcode, rs, rt, 5’h0, 5’h0, func | ramwi rt, rs |
ramri | opcode, rs, 5’h0, rd, 5’h0, func | ramri rd, rs |
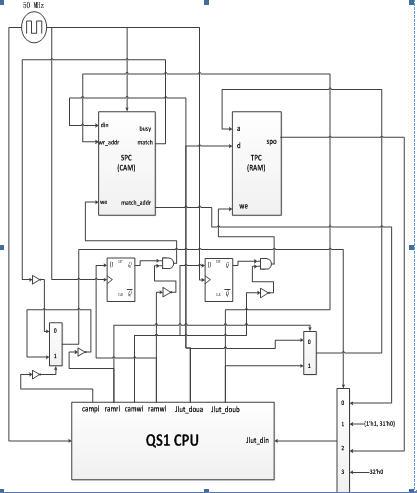
圖 28 JLUT詳細設計圖
4.2.動態翻譯詳細設計方案
二進制翻譯技術能夠把一種體系結構的二進制程序翻譯成另一種體系結構的二進制程序,以在新的體系結構下運行。二進制翻譯主要有三類:解釋執行、靜態翻譯及動態翻譯。
在系統總體框架圖中,二進制翻譯層可運行不同的翻譯程序,以在不同的體系之間進行轉換,如x86到MIPS、ARM到MIPS、x86到ARM等。本部分挑選了8086到MIPS的動態翻譯作為實現原型。
4.2.1.二進制翻譯介紹
二進制翻譯可以分為三大類:解釋執行、靜態翻譯和動態翻譯。
解釋執行的流程是:取指、解析、執行。它對源機器代碼進行實時解釋并執行,然后繼續下一條指令。系統不對已解釋的指令進行保存或緩存。在這個框架下,不能對代碼進行優化。這種翻譯技術能取得高度兼容性,但執行效率很低。
靜態翻譯是先將源可執行文件轉換成目標機器可執行文件,然后運行在目標機器上。這是離線翻譯,因此有充足的時間對代碼進行優化,以提高代碼的執行效率。但靜態翻譯很難做到正確性,如代碼的自修改問題,執行過程中有些跳轉值只能在運行時才能獲知等問題。
解釋執行是實時翻譯,靜態翻譯是離線翻譯,動態翻譯就像是兩者的折中。它不像解釋執行那樣對每條指令進行翻譯并馬上執行,也不像靜態翻譯那樣將指令完全翻譯好之后才執行。它每次對一個基本塊進行翻譯并執行,然后取另一個塊。一個基本塊一般包含多條算術類型指令,最后是一條控制流(Control Flow)類型指令。已翻譯的塊可進行緩存或保存。動態翻譯只對將要執行的代碼進行翻譯,且能很好地解決代碼自修改問題。
4.2.2.二進制翻譯策略選擇
本項目采取的是軟硬協同動態翻譯策略,將源二進制代碼進行翻譯,當遇到控制流類型指令,如跳轉指令,系統調用等,翻譯過程掛起,將已翻譯的指令序列作為一個基本塊,然后運行基本塊。當基本塊執行完以后,會跳到下一處執行。若下一處已翻譯過,則繼續執行,否則暫停執行以進行翻譯,如此過程循環。完整的流程如下圖所示。
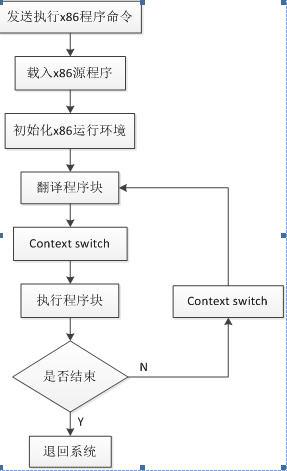
圖 29 x86程序翻譯執行流程
基本塊執行時有硬件模塊輔助,如圖 12所示。硬件模塊管理跳轉緩存,緩存的基本項為對。程序執行到跳轉指令時,程序向跳轉緩存發送SPC,得到相應的TPC,再跳至TPC繼續執行生成塊。簡單的示例如圖 30所示。源程序從塊A開始執行,到末尾時,需要跳轉到塊C。翻譯后執行,執行完塊A’后將要跳轉,此時的跳轉地址是SMEM中地址,即SPC,要轉換成相應的TPC,該TPC就由跳轉緩存中尋找。
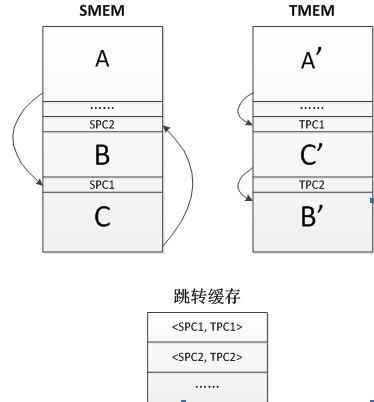
圖 30 SMEM與TMEM的映射
4.2.3.8086程序的載入
首先,由系統向服務器發送命令,命令格式為x86 *.com,它包含在自定義傳輸協議中,類型碼為86,要求.com文件僅使用一個段,大小限制為64KB。服務器找到所指定的文件,并將其傳送給系統,系統將其存放在內存中。至此,完成8086可執行程序的載入。
4.2.4.標志寄存器處理
8086中有個標志寄存器FLAGS,而MIPS中沒有與之相對應的標志寄存器,解決辦法有二,軟件模擬實現或硬件提供支持。
軟件模擬指的是,當一條8086指令執行后,會影響哪些標志位,然后用軟件方法將其模擬出來,使兩者的結果一致。如執行add ax, bx對溢出位的影響。模擬時,將ax移到MIPS的$t0寄存器的低16位,將bx移到MIPS的$t1寄存器的低16位,然后對$t0和$t1做加法,結果放到$t0,相對應的指令為add $t0, $t0, $t1。結果是否溢出則要查看$t0的第16位。最后,還要將溢出位存放至標志寄存器的對應位。這中間還要涉及移位運算、位運算等,所需代價很大,但有個好處是無需對硬件平臺做改動,使硬件平臺更為純粹。
若采用提供硬件支持,那么硬件平臺需稍做修改,增加一個類FLAGS寄存器。仍以上面的add ax, bx為例。將ax、bx分別放到$t0、$t1的高16位,然后進行相加,是否溢出的結果會自動保存到新添加的類FLAGS寄存器里,因而軟件層面無需再做處理。此種做法,增加了硬件工作,但大大簡化了軟件的操作。8086的FLAGS有多個標志位,若要完全實現,那么對本身的硬件平臺改動會比較大,因此,我們只選擇了其中幾個進行實現,如Z、O、C、S等。
4.2.5.寄存器映射
MIPS有32個通用寄存器,從0號到31號,每個寄存器為32位。8086的通用寄存器有8個:AX、CX、DX、BX、SP、BP、SI和DI。這8個通用寄存器都是16位,AX、CX、DX和BX還可以分成兩個8位寄存器,高8位和低8位,如AX可分為AH和AL。此外,段寄存器有CS、DS、ES和SS,都是16位。還有IP寄存器和FLAGS寄存器,也都是16位。
因為MIPS的寄存器數量比8086的寄存器多,可以采用直接映射,一個8086寄存器對應一個MIPS寄存器,而不需要對寄存器進行置換,簡化了寄存器的管理。






評論