風力渦輪機控制系統:從PID到增強學習

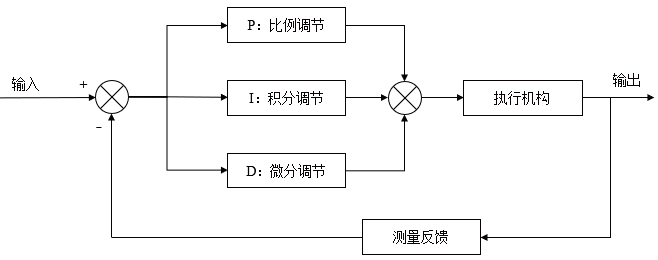
風力渦輪機控制系統在過去幾十年中經歷了顯著演變,從簡單的傳統控制器發展到基于人工智能的復雜策略。早期公用事業規模的渦輪機依賴比例積分導數(PID)控制器作為控制回路的骨干,因為PID的簡單性和可靠性。PID調節器在工業中仍被廣泛用于葉片螺距調整和發電機扭矩控制等任務,確保渦輪機以所需的轉速和功率輸出運行。然而,隨著渦輪機體積和結構的增加,PID控制在處理非線性氣動行為和多變量目標方面的局限性變得明顯。近年來,計算和機器學習的進步催生了強化學習(RL)技術的轉變,有望解決現代風能系統中高維控制挑戰。
現實生活基礎
在基于強化環境的控制系統中,渦輪(或風電場)控制器被實現為一個代理,觀察系統狀態(風速、旋翼轉速、功率輸出),并執行相應動作(如調整葉片的螺距角、發電機扭矩或偏航角)。獎勵函數被定義用于量化控制目標——例如,獎勵隨著電力輸出增加而減少,機械應力或極端負載則減少。強化學習代理探索不同的控制動作,并使用算法(如Q學習或策略梯度法)更新控制策略,以最大化長期回報。經過多次訓練迭代(通常在模擬中進行以保證安全),智能體學習出能夠應對各種條件的控制策略。現代深度強化學習使用神經網絡作為函數近似器,使智能體能夠處理連續的狀態空間和動作,這對于風的應用至關重要(如風速狀態和俯仰角等動作是連續變量)。
用于風力渦輪機控制的強化語言
強化學習在該領域的理論吸引力在于其能夠處理非線性、高維問題,這些問題在經典控制設計中難以解決。過去十年的研究表明,強化學習算法確實能夠應對風流和渦輪動力學的湍流和隨機特性。與為名義條件調校的PID不同,RL控制器原則上可以實時適應變化的風向——包括陣風、風向變化和不穩定的空氣動力學——因為它持續學習系統的響應。此外,強化學習自然地通過調整獎勵來支持多目標優化:例如,結合功率最大化、負載最小化甚至聲學噪聲降低等項。通過調整獎勵函數中的權重,工程師可以教強化學習代理在競爭目標之間找到理想的平衡。
關鍵是,強化學習并未完全消除領域知識的需求;而是以不同的方式利用了領域知識。設計良好的獎勵函數并向智能體提供正確的狀態觀測(特征)至關重要,并且需要理解風力渦輪機的物理。此外,安全約束必須通過獎勵(對不安全行為帶來嚴重懲罰)或通過集成某種監督邏輯來實現,因為在真實風機上純粹試錯可能存在危險。因此,許多用于風控的強化學習實現使用經過模擬訓練的智能體,并在任何現場部署前經過充分測試。高保真模擬器(如NREL的FAST/Farm或DTU的HAWC2)作為訓練場,可以運行數百萬小時的虛擬運行時間來訓練和評估強化學習控制器。近期甚至利用高性能計算集群運行大型并行仿真,加速了風力渦輪和發電場強化學習策略的訓練。
實際實現與案例研究
強化學習在風能領域的應用迅速擴展,尤其是在2020年代初,無論是學術界還是工業研究實驗室。最初的研究重點是將強化學習應用于單渦輪控制回路——例如,開發基于強化學習的俯仰控制器,以替代或增強傳統的PID。一個具有里程碑意義的例子展示了一個強化學習代理同時控制多個執行器,以最大化單輪機對風向變化的能量捕獲動作,從而有效學習PID無法實時調整的最優權衡。
除了單臺機器,風電場控制也是強化學習最引人注目的領域之一。在風電場中,上游渦輪機會產生氣動尾跡,降低下游風機的性能。傳統的農場控制算法(如偏航錯位后的尾流重定向或動態感應控制)依賴簡化的物理模型和啟發式,這些方法往往無法完全捕捉湍流相互作用。
為了支持該領域的開發,社區甚至構建了開源的強化學習基準測試環境。一個例子是WFCRL(帶強化學習的風電場控制),這是一套于2024年底推出的開放多智能體強化學習環境套件。WFCRL提供標準化場景(包括真實風電場布局),并與快速和高保真模擬器(如FLORIS用于穩態尾跡建模和FAST)接口。湍流流場)幫助研究人員和企業在風電場控制問題上測試強化學習算法。此類平臺的出現表明該領域正在成熟,能夠快速比較和迭代最佳實踐和算法。事實上,工業興趣正在增長:NREL計算科學中心明確將風電場控制列為強化學習研究目標,旨在利用強化學習解決“挑戰傳統方法論”的問題。大型渦輪制造商和能源公司也在謹慎地探索人工智能驅動控制,作為其數字創新項目的一部分,通常與大學和國家實驗室合作。
結論
對于能源專業人士來說,強化學習(RL)在風力渦輪控制中的出現意味著未來的風機能夠自主微調性能,從而提升能源產率、降低負荷并更智能地應對環境限制。不過,采用這些先進控制仍需精心設計——結合新舊優勢。這一轉變可能是漸進的:我們不會突然取代PID控制器,而是通過大量測試和驗證,逐步增強傳統控制的人工智能。




評論