語音識別技術的研究與發展

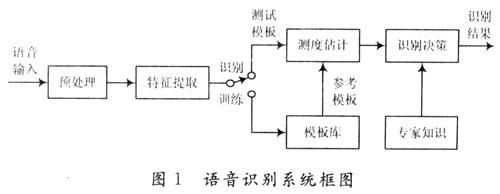
(2)特征提取模塊:負責計算語音的聲學參數,并進行特征的計算,以便提取出反映信號特征的關鍵特征參數用于后續處理。現在較常用的特征參數有線性預測(LPC)參數、線譜對(LSP)參數、LPCC、MFCC、ASCC、感覺加權的線性預測(PLP)參數、動態差分參數和高階信號譜類特征等[1]。其中,Mel頻率倒譜系數(MFCC)參數因其良好的抗噪性和魯棒性而應用廣泛。
(3)訓練階段:用戶輸入若干次訓練語音,經過預處理和特征提取后得到特征矢量參數,建立或修改訓練語音的參考模式庫。
(4)識別階段:將輸入的語音提取特征矢量參數后與參考模式庫中的模式進行相似性度量比較,并結合一定的判別規則和專家知識(如構詞規則,語法規則等)得出最終的識別結果。
4 語音識別的幾種基本方法
當今語音識別技術的主流算法,主要有基于動態時間規整(DTW)算法、基于非參數模型的矢量量化(VQ)方法、基于參數模型的隱馬爾可夫模型(HMM)的方法、基于人工神經網絡(ANN)和支持向量機等語音識別方法。
4.1 動態時間規整(DTW)
DTW是把時間規整和距離測度計算結合起來的一種非線性規整技術,是較早的一種模式匹配和模型訓練技術。該方法成功解決了語音信號特征參數序列比較時時長不等的難題,在孤立詞語音識別中獲得了良好性能。
4.2 矢量量化(VQ)
矢量量化是一種重要的信號壓縮方法,主要適用于小詞匯量、孤立詞的語音識別中。其過程是:將語音信號波形的k個樣點的每1幀,或有k個參數的每1參數幀,構成k維空間中的1個矢量,然后對矢量進行量化。量化時,將k維無限空間劃分為M個區域邊界,然后將輸入矢量與這些邊界進行比較,并被量化為“距離”最小的區域邊界的中心矢量值。矢量量化器的設計就是從大量信號樣本中訓練出好的碼書,從實際效果出發尋找到好的失真測度定義公式,設計出最佳的矢量量化系統,用最少的搜索和計算失真的運算量,實現最大可能的平均信噪比。
4.3 隱馬爾可夫模型(HMM)
隱馬爾可夫模型是20世紀70年代引入語音識別理論的,它的出現使得自然語音識別系統取得了實質性的突破。目前大多數大詞匯量、連續語音的非特定人語音識別系統都是基于HMM模型的。
HMM是對語音信號的時間序列結構建立統計模型,將其看作一個數學上的雙重隨機過程:一個是用具有有限狀態數的Markov鏈來模擬語音信號統計特性變化的隱含的隨機過程,另一個是與Markov鏈的每一個狀態相關聯的觀測序列的隨機過程。前者通過后者表現出來,但前者的具體參數是不可測的。人的言語過程實際上就是一個雙重隨機過程,語音信號本身是一個可觀測的時變序列,是由大腦根據語法知識和言語需要(不可觀測的狀態)發出的音素的參數流。HMM合理地模仿了這一過程,很好地描述了語音信號的整體非平穩性和局部平穩性,是較為理想的一種語音模型。
HMM模型可細分為離散隱馬爾可夫模型(DHMM)和連續隱馬爾可夫模型(CHMM)以及半連續隱馬爾可夫模型(SCHMM)等[3]。
4.4 人工神經元網絡(ANN)
人工神經元網絡在語音識別中的應用是目前研究的又一熱點。ANN實際上是一個超大規模非線性連續時間自適應信息處理系統,它模擬了人類神經元活動的原理,最主要的特征為連續時間非線性動力學、網絡的全局作用、大規模并行分布處理及高度的穩健性和學習聯想能力。這些能力是HMM模型不具備的。但ANN又不具有HMM模型的動態時間歸正性能。因此,人們嘗試研究基于HMM和ANN的混合模型,把兩者的優點有機結合起來,從而提高整個模型的魯棒性,這也是目前研究的一個熱點。



評論