最小化ARM Cortex-M CPU功耗的方法與技巧

舉個例子,即使在廣受歡迎的ARM Cortex-M類的MCU中指令緩沖的運行方法也有不同。采用簡單指令緩沖的MCU,例如來自Silicon Labs的EFM32產品,可以存儲128x32(512 bytes)的目前大多數當前執行指令(通過邏輯判斷請求的指令地址是否在緩沖中)。EFM32參考手冊指出典型應用在這個緩沖中將有超過70%的命中率,這意味著極少的Flash存取、更快的代碼執行速度和更低的整體功耗。相比之下,采用64x128位分支緩沖器的ARM MCU能夠存儲最初的幾條指令(取決于16位或32位指令混合,每個分支最多為8條指令,最少為4條指令)。因此,分支緩沖實現能夠在1個時鐘周期內為命中緩沖的任何分支或跳轉填充流水線,從而消除了任何CPU時鐘周期延遲或浪費。兩種緩沖技術與同類型沒有緩沖特性的CPU相比,都提供了相當大的性能改善和功耗減少。
本文引用地址:http://cqxgywz.com/article/273202.htm4 M0+內核探究
對功耗敏感型應用來說每個nano-watt都很重要,Cortex-M0+內核是一個極好的選擇。M0+基于Von-Neumann架構(而Cortex-M3和Cortex-M4內核是Harvard結構),這意味著它具有更少的門電路數量實現更低的整體功耗,并且僅僅損失極小的性能(Cortex-M0+的0.93DMIPS/MHz對比Cortex-M3/M4的1.25DMIPS/MHz)。它也使用Thumb-2指令集的更小子集(如圖3所示)。幾乎所有的指令都有16位的操作碼(52x16位操作碼和7x32位操作碼;數據操作都是32位的),這使得它可以實現一些令人感興趣的功能選項以降低CPU功耗。

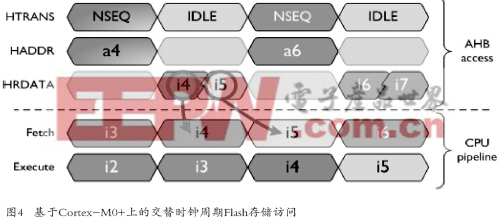
節能性功能選項首要措施就是減少Flash存儲訪問次數。一個主要的16位指令集意味著你可以交替時鐘周期訪問Flash存儲器(如圖4所示),并且可以在每一次Flash存儲訪問中為流水線獲取兩條指令。假設你在存儲器中有兩條指令并對齊成一個32位字;在指令沒有對齊的情況下,Cortex-M0+將禁止剩余的一半總線以節省每一點能耗。

存儲器相關文章:存儲器原理




評論