deepseek-v3 文章 最新資訊
深度求索上下文窗口擴(kuò)大十倍,智譜同步發(fā)布新模型,中國AI競賽加速
- 中國的AI大模型競賽正在加速升溫。據(jù)《南華早報(bào)》報(bào)道,中國AI初創(chuàng)公司深度求索(DeepSeek)已對(duì)其旗艦?zāi)P瓦M(jìn)行重大升級(jí),顯著擴(kuò)展了上下文窗口并更新了知識(shí)庫,引發(fā)市場對(duì)其下一代重磅模型發(fā)布的高度期待。報(bào)道稱,此次升級(jí)將模型的上下文窗口從12.8萬token大幅擴(kuò)展至超過100萬token——接近十倍的增長,有望顯著增強(qiáng)其處理和回應(yīng)復(fù)雜提示的能力。同時(shí),模型的知識(shí)截止時(shí)間也從2024年7月延長至2025年5月,新增近一年的信息,使用戶能夠獲取更近期的數(shù)據(jù)。不過,據(jù)鳳凰網(wǎng)科技指出,此次升級(jí)并未引入多模態(tài)視
- 關(guān)鍵字: deepseek AI
深度求索有望獲準(zhǔn)采購英偉達(dá)H200芯片,中國 reportedly 給出有條件放行信號(hào)
- 路透社報(bào)道,在市場傳聞深度求索(DeepSeek)計(jì)劃于農(nóng)歷新年假期期間發(fā)布其下一代AI大模型之際,中國已向這家頭部初創(chuàng)公司發(fā)出有條件批準(zhǔn),允許其采購英偉達(dá)(NVIDIA)的H200 AI芯片,但具體監(jiān)管條款仍在最終敲定中。深度求索可能并非唯一獲準(zhǔn)的企業(yè)。路透社此前曾報(bào)道,包括字節(jié)跳動(dòng)、阿里巴巴和騰訊在內(nèi)的其他中國科技巨頭也已獲得授權(quán),合計(jì)可采購超過40萬顆H200芯片。報(bào)道稱,中國工業(yè)和信息化主管部門已對(duì)這四家公司發(fā)放了采購許可,但均附帶條件,相關(guān)細(xì)則尚在完善。據(jù)一位消息人士透露,這些具體條款正由中國的
- 關(guān)鍵字: Deepseek 英偉達(dá) H200
字節(jié)跳動(dòng)、阿里、深度求索據(jù)傳將于2月集中發(fā)布新模型,助推中國AI競賽白熱化
- 據(jù)傳,中國多家科技公司計(jì)劃在2026年農(nóng)歷新年假期期間(2月)密集推出新一代人工智能大模型。根據(jù)自媒體“ijiwei”報(bào)道,消息人士透露,字節(jié)跳動(dòng)和阿里巴巴正籌備在此期間發(fā)布全新旗艦AI模型。此前,《EE Times China》曾指出,深度求索(DeepSeek)近期在其GitHub代碼庫中更新了名為“MODEL1”的新架構(gòu)標(biāo)識(shí),被廣泛視為其下一代旗艦?zāi)P?nbsp;DeepSeek V4 的技術(shù)基礎(chǔ)。有消息稱,該模型最早可能于2026年2月中旬發(fā)布,將進(jìn)一步加劇行業(yè)競爭。字節(jié)跳動(dòng)加碼AI:三
- 關(guān)鍵字: 字節(jié)跳動(dòng) 阿里 Deepseek
周年回顧|DeepSeek如何改變開源AI

- 在DeepSeek R1發(fā)布一周年之際,讓我們一起來回顧DeepSeek究竟是如何改變了開源AI —— R1并不是當(dāng)時(shí)最強(qiáng)的模型,真正意義而在于它如何降低了三重壁壘。i. 技術(shù)壁壘:通過公開分享其推理路徑和后訓(xùn)練方法,R1將曾經(jīng)封閉在API背后的高級(jí)推理能力,轉(zhuǎn)變?yōu)榭上螺d、可蒸餾、可微調(diào)的工程資產(chǎn),推理開始表現(xiàn)得像一個(gè)可復(fù)用的模塊,在不同的系統(tǒng)中反復(fù)應(yīng)用。這也推動(dòng)行業(yè)重新思考模型能力與計(jì)算成本之間的關(guān)系,這種轉(zhuǎn)變在中國這樣算力受限的環(huán)境中尤為有意義。ii. 采用壁壘:R1以MIT許可證發(fā)布,使其使用、修改
- 關(guān)鍵字: DeepSeek 開源 AI
DeepSeek新模型曝光:MODEL1代碼預(yù)示新架構(gòu),最快有望2月發(fā)布
- 1 月 21 日消息,The Information 月初爆料稱,DeepSeek 將在今年 2 月中旬農(nóng)歷新年期間推出新一代旗艦 AI 模型 ——DeepSeek V4,將具備更強(qiáng)的寫代碼能力。1 月 20 日,正值 DeepSeek-R1 發(fā)布一周年之際,有開發(fā)者發(fā)現(xiàn) DeepSeek 在 GitHub 中更新了一系列 FlashMLA 代碼,橫跨 114 個(gè)文件中有 28 處都提到了未知的“MODEL1”大模型標(biāo)識(shí)符。該標(biāo)識(shí)符與已知的現(xiàn)有模型“V32”(即 DeepSeek-V3.2)被并列或區(qū)別提
- 關(guān)鍵字: DeepSeek MODEL1 代碼 新架構(gòu) DeepSeek V4
中國開源AI模型崛起,Llama徹底出局

- AGI雖在實(shí)際應(yīng)用中仍存局限性,但曙光現(xiàn)已成為今年行業(yè)的共識(shí)。在一系列技術(shù)任務(wù)中,從ChatGPT到Gemini,許多世界領(lǐng)先的AI模型正超越人類基準(zhǔn)線:據(jù)斯坦福大學(xué)《2025年AI指數(shù)報(bào)告》,AI已在7項(xiàng)測試中超越人類基準(zhǔn)線,這些測試衡量的任務(wù)包括:圖像分類、視覺推理、中等閱讀理解、英語語言理解、多任務(wù)語言理解、競賽級(jí)數(shù)學(xué)、博士級(jí)科學(xué)問題。
- 關(guān)鍵字: 開源 AI 模型 Llama DeepSeek
中國開源AI模型下載量首超美國,DeepSeek再出手

- 近日,一份來自麻省理工學(xué)院(MIT)與開源社區(qū)Hugging Face的聯(lián)合報(bào)告顯示:在剛剛過去的一年里,中國研發(fā)的開源人工智能模型在全球下載量中的占比達(dá)到了17.1%,歷史上首次超越了美國的15.8%。圖(來源:Financial Times) | 每周開發(fā)者下載份額,紅色及粉色區(qū)域?yàn)橹袊鳤I模型這項(xiàng)研究表明,在開放模型這一關(guān)鍵領(lǐng)域,中國企業(yè)正以其開源策略對(duì)美國公司過去主要依賴閉源模型所建立的競爭優(yōu)勢,已經(jīng)構(gòu)成了不可忽視的挑戰(zhàn)。DeepSeek和阿里巴巴的Qwen等中國模型,正憑借其獨(dú)特的開發(fā)與推廣模式
- 關(guān)鍵字: 開源 AI 大模型 DeepSeek
趁硅谷過節(jié)“開大”!DeepSeek上線“奧數(shù)金牌”模型!填平谷歌OpenAI護(hù)城河
- 專挑節(jié)假日搞大新聞”的DeepSeek又出手了。就在大洋彼岸的工程師們準(zhǔn)備切火雞慶祝節(jié)日時(shí),DeepSeek保持了極客傳統(tǒng),悄然上線了DeepSeekMath-V2。開源權(quán)重、IMO金牌水平、超越GPT-5。 這套熟悉的“三連擊”,再次鞏固了DeepSeek作為“開源燈塔”的地位。 在算力受限的背景下,DeepSeek 再次證明了自己:不需要龐大的 GPU 集群,也能用算法奇跡在最硬核的數(shù)學(xué)賽道上,教閉源巨頭們“做人”。它“不搞虛的”,直接拿數(shù)學(xué)競賽界的“終極試金石”,包括2025國際
- 關(guān)鍵字: 硅谷過節(jié) DeepSeek 奧數(shù)金牌 谷歌 OpenAI
Arm Neoverse CSS V3驅(qū)動(dòng)Microsoft Azure Cobalt 200
- 微軟最新發(fā)布的?Cobalt 200 CPU?處理器基于?Arm Neoverse CSS V3?打造,為云與?AI?基礎(chǔ)設(shè)施的設(shè)計(jì)方式帶來突破性變革。在人工智能?(AI)?時(shí)代,行業(yè)已從通用型現(xiàn)成系統(tǒng)向定制化基礎(chǔ)設(shè)施發(fā)生顯著轉(zhuǎn)型。從傳統(tǒng)網(wǎng)絡(luò)服務(wù)到可擴(kuò)展數(shù)據(jù)分析,再到大規(guī)模模型推理,各類工作負(fù)載如今均已融入?AI?驅(qū)動(dòng)的智能處理鏈路中。現(xiàn)代數(shù)據(jù)中心的架構(gòu)設(shè)計(jì)已經(jīng)不再是獨(dú)立計(jì)算資源的堆砌,而是需要構(gòu)建成能夠高
- 關(guān)鍵字: Neoverse CSS V3 Azure Cobalt 200
DeepSeek低調(diào)發(fā)布3.2版本:曾經(jīng)的頂流大模型,如今熱度減退了?
- 前不久,DeepSeek 悄悄更新了全新的V3.1 版本,這次更新全無公告,只在微信群里做了通知,既沒有官方預(yù)告,也未同步發(fā)布基準(zhǔn)測試榜單,僅以“v3.1+”這樣保守的命名悄然上線。不得不說,DeepSeek 的低調(diào)更新方式,使其在大模型領(lǐng)域也就此一家了。與之形成鮮明對(duì)比的是,R1 在大多數(shù)人的心目中排名前五,與開啟時(shí)代的GPT4 等模型并列,其在全球范圍內(nèi)的影響力不容小覷。DeepSeek的低調(diào)更新,或許是一種策略,避免過度曝光帶來的負(fù)面影響,但同時(shí)也導(dǎo)致了部分網(wǎng)友的“過山車式”的誤解。年初DeepSe
- 關(guān)鍵字: 202509 DeepSeek 大模型
英特爾Gaudi 2E AI加速器為DeepSeek-V3.1提供加速支持
- 英特爾? Gaudi 2E AI加速器現(xiàn)已為DeepSeek-V3.1提供深度優(yōu)化支持。憑借出色的性能和成本效益,英特爾Gaudi 2E以更低的投入、更高的效率,實(shí)現(xiàn)從模型訓(xùn)練的深度突破到推理部署的實(shí)時(shí)響應(yīng),為大模型的加速落地提供新選擇。英特爾Gaudi 2E配備96 GB大容量內(nèi)存,搭載先進(jìn)的HBM控制器,針對(duì)隨機(jī)訪問、線性訪問場景進(jìn)行深度優(yōu)化,有效避免了AI訓(xùn)練或推理任務(wù)的延遲,從而保障了計(jì)算流程的流暢性。英特爾Gaudi 2E擁有卓越的可擴(kuò)展能力,支持多卡互聯(lián),為用戶提供了靈活的、可定制化的解決方案
- 關(guān)鍵字: 英特爾 AI加速器 DeepSeek
金融時(shí)報(bào):DeepSeek 因華為芯片問題推遲新人工智能模型
- 英國《金融時(shí)報(bào)》周四援引三位知情人士的話報(bào)道稱,由于使用華為芯片的訓(xùn)練工作失敗,DeepSeek推遲了其新人工智能模型的發(fā)布。據(jù)英國《金融時(shí)報(bào)》報(bào)道,這家中國人工智能初創(chuàng)公司在使用華為的昇騰芯片訓(xùn)練其 R2 模型時(shí)遇到了持續(xù)存在的技術(shù)問題,促使其使用 Nvidia 芯片進(jìn)行訓(xùn)練,使用 Ascend 進(jìn)行推理。報(bào)告稱,這些問題是 Deepseek 備受期待的 R2 車型發(fā)布從 5 月推遲的主要原因。英國《金融時(shí)報(bào)》的報(bào)道強(qiáng)調(diào)了中國人工智能開發(fā)商在減少對(duì)美國技術(shù)(特別是英偉達(dá)人工智能芯片)的依賴方面
- 關(guān)鍵字: 金融時(shí)報(bào) DeepSeek 華為 芯片 人工智能模型
OpenAI再度回歸“開放”賽道,一場精心布局的陽謀

- 8月6日凌晨(美東時(shí)間8月5日),OpenAI發(fā)布了兩款免費(fèi)試用的開放權(quán)重語言模型gpt-oss-120b和gpt-oss-20b,同時(shí)放出的34頁技術(shù)報(bào)告顯示模型采用了最先進(jìn)的預(yù)訓(xùn)練和后訓(xùn)練技術(shù),但沒有提供用于訓(xùn)練模型的數(shù)據(jù)。OpenAI聯(lián)合創(chuàng)始人兼首席執(zhí)行官山姆·奧特曼(Sam Altman)在社交媒體表示:“gpt-oss是一個(gè)重大突破,這是最先進(jìn)的開放權(quán)重推理模型,具有與o4-mini相當(dāng)?shù)膹?qiáng)大現(xiàn)實(shí)世界性能,可以在你自己的電腦(或手機(jī)的較小版本)上本地運(yùn)行。我們相信這是世界上最好、最實(shí)用的開放模型
- 關(guān)鍵字: OpenAI 開源 大模型 DeepSeek
DeepSeek又被“拉黑”

- 近日,德國聯(lián)邦數(shù)據(jù)保護(hù)專員邁克·坎普(Meike?Kamp)正式向蘋果(Apple)與谷歌(Google)提出請求,要求將中國人工智能初創(chuàng)企業(yè)深度求索(DeepSeek)的應(yīng)用程序,從德國區(qū)App?Store和Google?Play下架。2025年6月27日,相應(yīng)的報(bào)告已發(fā)送給蘋果和谷歌,兩家公司現(xiàn)在必須立即審查該報(bào)告并決定是否實(shí)施封殺DeepSeek。指控“非法轉(zhuǎn)移數(shù)據(jù)”根據(jù)德國當(dāng)局調(diào)查表示,DeepSeek的隱私政策顯示,用戶的對(duì)話內(nèi)容、上傳文件、IP地址、設(shè)備信息、敲擊鍵盤的節(jié)奏等數(shù)據(jù)都存儲(chǔ)在中國的
- 關(guān)鍵字: DeepSeek ChatGPT AI GPT-4o
AI 顛覆者 DeepSeek 的下一代模型因 Nvidia GPU 對(duì)中國出口限制而延遲——AI GPU 短缺阻礙開發(fā)
- (圖片來源:英偉達(dá))DeepSeek 憑借其今年的 R1 AI 模型吸引了大量關(guān)注,但似乎下一代 R2 模型的開發(fā)因中國 Nvidia H20 處理器的短缺而停滯,據(jù) 信息報(bào)道 。DeepSeek 本身尚未評(píng)論其 R2 模型的發(fā)布時(shí)間。DeepSeek 使用由其投資者 High-Flyer Capital Management 獲得的包含 50,000 個(gè) Hopper GPU 的集群——其中包括 30,000 個(gè) H20、10,000 個(gè) H800 和 10,000 個(gè) H100——
- 關(guān)鍵字: DeepSeek AI 大語言模型 GPU 英偉達(dá)
deepseek-v3介紹
您好,目前還沒有人創(chuàng)建詞條deepseek-v3!
歡迎您創(chuàng)建該詞條,闡述對(duì)deepseek-v3的理解,并與今后在此搜索deepseek-v3的朋友們分享。 創(chuàng)建詞條
歡迎您創(chuàng)建該詞條,闡述對(duì)deepseek-v3的理解,并與今后在此搜索deepseek-v3的朋友們分享。 創(chuàng)建詞條
deepseek-v3電路


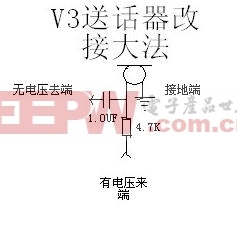
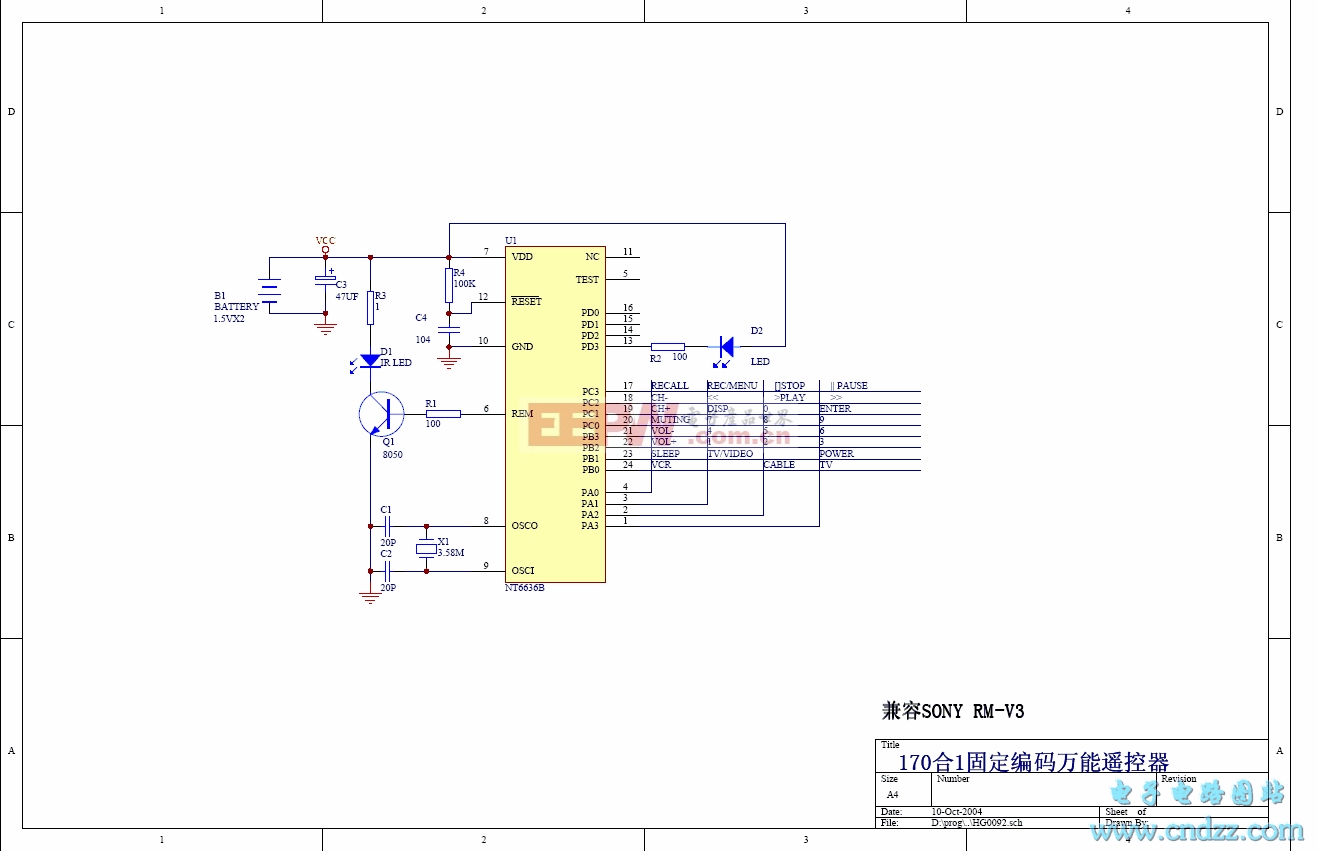
deepseek-v3相關(guān)帖子
deepseek-v3資料下載
deepseek-v3專欄文章
關(guān)于我們 -
廣告服務(wù) -
企業(yè)會(huì)員服務(wù) -
網(wǎng)站地圖 -
聯(lián)系我們 -
征稿 -
友情鏈接 -
手機(jī)EEPW
Copyright ?2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《電子產(chǎn)品世界》雜志社 版權(quán)所有 北京東曉國際技術(shù)信息咨詢有限公司
 京ICP備12027778號(hào)-2 北京市公安局備案:1101082052 京公網(wǎng)安備11010802012473
京ICP備12027778號(hào)-2 北京市公安局備案:1101082052 京公網(wǎng)安備11010802012473
Copyright ?2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《電子產(chǎn)品世界》雜志社 版權(quán)所有 北京東曉國際技術(shù)信息咨詢有限公司