【地平線 征程 6 工具鏈進階教程】算子優化方案集錦

在將算法模型部署至 征程 6 芯片平臺的實際應用中,由于算法設計與硬件架構特性存在差異,可能會出現部分算子適配度有待提升、運行效率有待優化以及量化精度可進一步優化等情況。解決好這些問題有助于模型更快更好的運行,充分發揮硬件性能。
本文聚焦于算法模型在 征程 6 芯片上部署時的算子支持問題,包括算子不支持、算子運行效率低、算子量化精度差問題的解決和優化建議。重點闡述解決上述問題的優化思路給出優化案例,使模型在 征程 6 芯片平臺實現更快速、更穩定的運行,為算法高效落地提供實用的技術路徑。
1.算子替換算子替換主要解決模型中存在 BPU 不支持的算子問題。當遇到無法支持的算子時,為提升執行性能需要使用 BPU 支持的算子對不支持的算子做替換,使盡可能多的運行在 BPU 中。
1.1 Scatternd 的產生和消除ScatterND 算子由 op 做了 slice 操作 之后 又進行 inplace 產生,因此會引入 CPU 算子。若導出的 onnx 中均存在大量 ScatterND,希望從算法側進行移除, 等價替換相關操作即可。以下給出幾種使用場景:
場景 1:
# dummy code to generate ScatterND import torch from torch import nn class DummyModel(nn.Module): def __init__(self): super().__init__() def forward(self, x):
將模型導出后會發現存在 scatternd 算子:
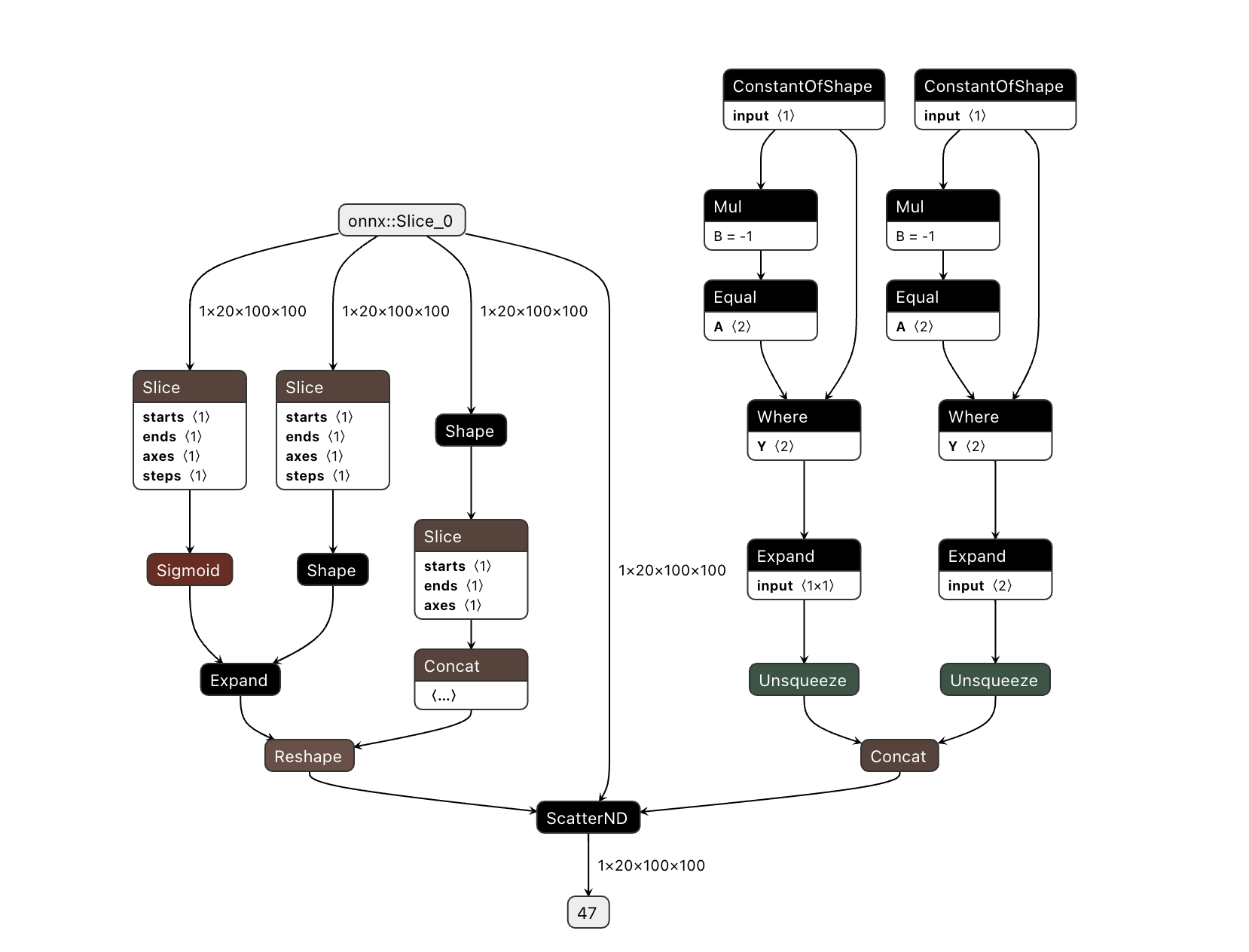
修改后不帶 ScatterND 的代碼與模型結構
import torch from torch import nn class DummyModel(nn.Module): def __init__(self): super().__init__() def forward(self, x): tmp1 = x[:, :2] tmp2 = x[:, 2:]
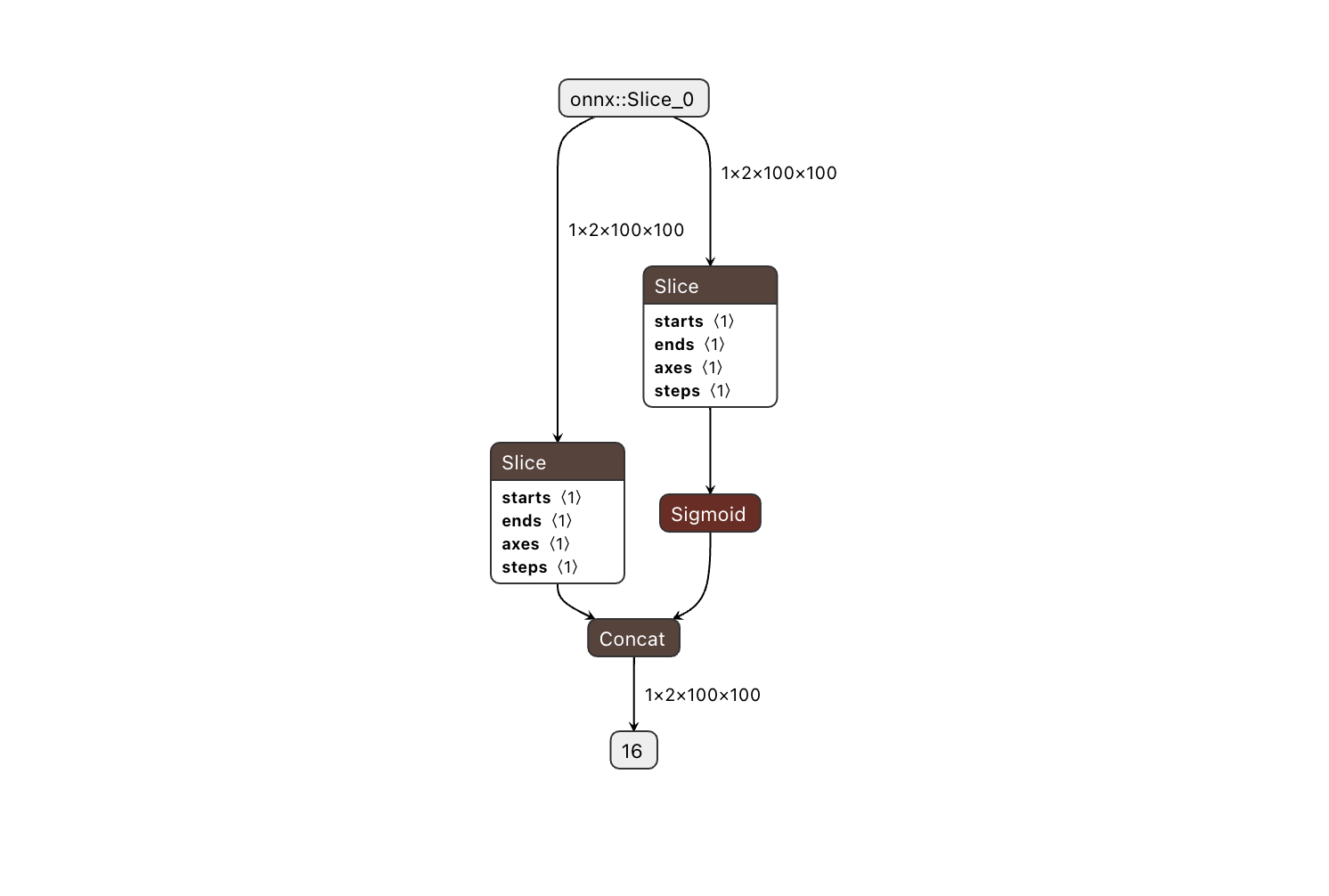 查看 onnx,scatternd 算子不存在,已被替換。
查看 onnx,scatternd 算子不存在,已被替換。
場景 2:
修改前 onnx 中帶有 ScatterND 算子的代碼示例
###### 修改前onnx中帶有ScatterND算子的代碼 ###### block_warp_offset = torch.clone( offset[ :, pad_u : self.height - pad_b, pad_l : self.width - pad_r, :, ] ) block_warp_offset[:, :, :, 0] += pad_l
修改后 onnx 中不帶 ScatterND 算子的代碼示例
###### 修改后onnx中不帶ScatterND算子的代碼 ###### block_warp_offset = torch.clone( offset[ :, pad_u : self.height - pad_b, pad_l : self.width - pad_r, :, ] ) a = block_warp_offset[:, :, :, :1] + pad_l
場景 3:
如下代碼會引入 scatterND
# intri_mat shape為(1,4,4,4), intrinsic shape為(1,4,3,3) intri_mat = torch.eye(4).unsqueeze(0).repeat(1, 4, 1, 1) intri_mat[:, :, :3, :3] = intrinsic
修改與驗證代碼如下:
import torch from torch import nn class DummyModel(nn.Module): def __init__(self): super().__init__() def forward(self, intri_mat,intrinsic): ## ============方案1 ============= # tmp1 = intri_mat[:, :, :3, :3]
方案 1 與方案 2 思想一樣
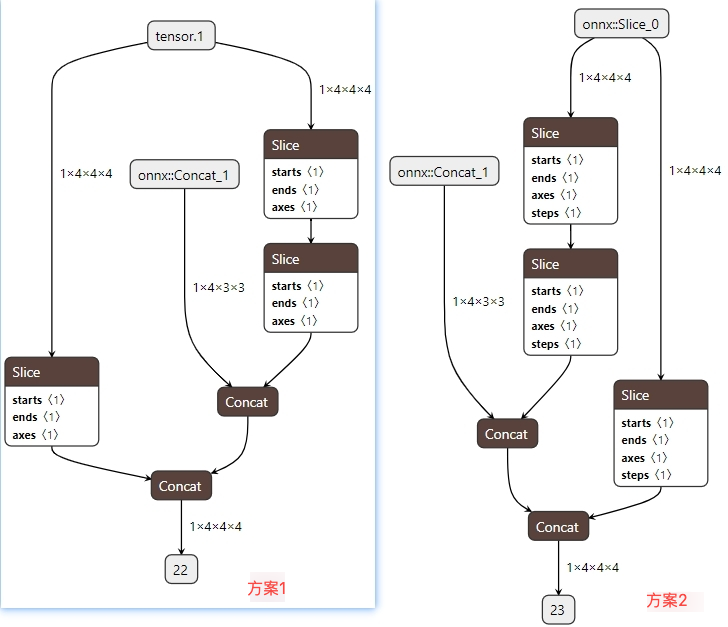
場景 4:
原包含 scatternd 算子的代碼:
key_points = self.scale_mul.mul(scale, self.exp.exp(anchor[1][..., None, 0:3]) rotation_mat[:, :, 0, 0] = anchor[2][:, :, 1] # cos rotation_mat[:, :, 0, 1] = -anchor[2][:, :, 0] # sin rotation_mat[:, :, 1, 0] = anchor[2][:, :, 0] rotation mat[:. :, 1, 1] = anchor[2][:, :,1]
修改之后:
key_points = self.scale_mul.mul(scale, self.exp.exp(anchor[1][..., None, 0:3])) temp_cos = anchor[2][:, :, 1] temp_sin = anchor[2][:, :, 0] temp_zeros = self.rotation_quant(temp_cos.new_zeros([bs, num_anchor])) temp_ones = self.rotation_quant(temp_cos.new_ones([bs, num_anchor])) temp1 = self.stack1.stack([temp_cos, -temp_sin, temp_zeros], dim=-1) temp2 = self.stack2.stack([temp_sin, temp_cos, temp_zeros], dim=-1) temp3 = self.stack3.stack([temp_zeros, temp_zeros, temp_ones], dim=-1) rotation_mat = self.stack4.stack([temp1, temp2, temp3], dim=-2)
場景 5:
Swin Transformer 中為滑動注意力窗口計算對應的掩碼值,不同區域做標識符區分
原代碼為:
# calculate attention mask for SW-MSA # +-----------+-----------+-----------+ # | Region 0 | Region 1 | Region 2 | # +-----------+-----------+-----------+ # | Region 3 | Region 4 | Region 5 | # +-----------+-----------+-----------+ # | Region 6 | Region 7 | Region 8 | # +-----------+-----------+-----------+ img_mask = torch.zeros((1, H_pad, W_pad, 1), device=query.device) h_slices = (
修改之后:
主要思路,把對原 tensor 劃區域的賦值方式修改為劃區域的拼接,先對 w 維度進行拼接,再對 h 維度拼接
cnt = 0 img_mask_patches = [] for h in [ H_pad - self.window_size, self.window_size - self.shift_size, self.shift_size, ]: img_mask_patches.append([]) for w in [ W_pad - self.window_size,1.2 Bool 賦值和 Mask 替換
對于 PNC 以及靜態目標檢測模型,模型中較多邏輯判斷涉及到 bool 數據類型的賦值和 mask 操作,這一類操作可以考慮替換為 torch.where 算子,可以消除潛在的 cpu 算子并提升模型性能,例如
tfl_mask[valid == 0] = float("-65504")該操作在 E/M 會引入 cast 和 equal 算子 cpu,如下
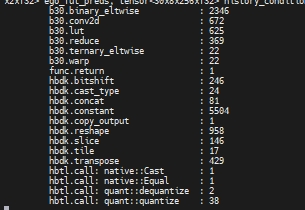
可以修改為:
x = torch.where(valid_mask == 0, torch.tensor(float("-65504"), device=x.device), x)此外,此處 -65504 的極大值會影響模型中該算子輸入的數據分布,影響量化參數統計從而影響量化精度,相同場景還有 attn 結構中對 attn_mask 的填充:attn = torch.where(attn_mask, float("-inf"), attn)。因此考慮到量化精度的話,這里建議進一步將填充值換為量化友好的數值:
x = torch.where(valid_mask == 0, torch.tensor(-100, device=x.device), x)1.3 Nonzero 等效替換
目前 征程 6 芯片不支持 BPU Nonezero 算子,需要對其做替換使算子跑在 BPU 中:
# 修改前 key_mask=agent_mask.clone() key_mask = key_mask.reshape(-1, self.T) index=torch.nonzero(key_mask[:, -1] key_mask[index,:] = 0 # 修改后 key_mask=agent_mask.clone() key_mask = key_mask.reshape(-1, self.T) mask_filter = ~key_mask[:, -1] key_mask = mask.logical_and(mask_filter.unsqueeze(1))1.4 Enisum 等效替換
目前 征程 6 芯片不支持 torch.einsum 算子,可以使用以下兩種方式替換:
import torch
A = torch.randn(2, 3, 4, 5, 6) # 形狀為 (a=2, b=3, c=4, i=5, j=6)
B = torch.randn(6, 7, 2, 3) # 形狀為 (j=6, k=7, a=2, b=3)
# 使用einsum進行操作
result = torch.einsum('abcij, jkab -> abcik', A, B)
# 直接等價實現
# 擴展張量A和B以對齊維度
A = A.unsqueeze(-1) # 擴展為 (a, b, c, i, j, 1)
B = B.unsqueeze(0).unsqueeze(-1).permute(3, 4, 5, 0, 1, 2) # 擴展為 (a, b, 1, 1, j, k)
# 逐元素相乘并對j維度進行求和
import torch
A = torch.randn(2, 3, 4, 5, 6) # 形狀為 (a=2, b=3, c=4, i=5, j=6)
B = torch.randn(6, 7, 2, 3, 4) # 形狀為 (j=6, k=7, a=2, b=3, c=4)
# 使用einsum進行操作
result = torch.einsum('abcij, jkabc -> abcik', A, B)
# 替代實現
B = B.permute(2, 3, 4, 0, 1) # tanspose為 (a, b, c, j, k)
result_alt = torch.matmul(A, B)
# 結果比較
compare = torch.allclose(result, result_alt, rtol=0.00001, atol=0.00001)2.算子優化算子優化分為執行效率的優化和精度的優化。在部署時可能出現算子引入的其他開銷,或者算子的執行效率支持的不夠好的情況,同時在部署時我們還需要考慮算子的量化精度友好性。本章節將分別針對算子的效率優化和精度優化,給出部署建議和優化方案,幫助模型更快、更好的運行。
2.1 效率優化2.1.1 Topk 算子征程 6E/M 在工具鏈 OE3.2.0 已支持 topk 算子在 SPU 上運行(征程 6B 在 OE3.5.0 版本支持),在 convert 時配置 enable_spu=True 后算子將會被指定在 SPU 上運行。若 topk 算子后接的 gather、index 算子出現 CPU 的 cast 算子時,建議將 OE 版本升級到 OE-3.5.0(或者將 hbdk 升級到 4.5.5 及以上版本)。
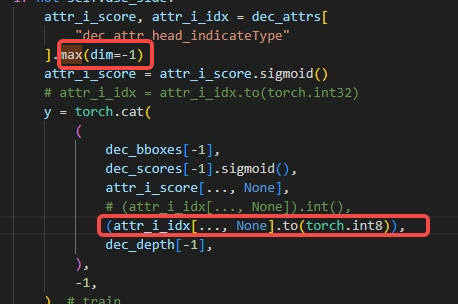
2.1.2 Argmax 后 cast 消除pytorch 的 argmax 輸出的 idx 為 int64 類型,若不做改動會導致引入 CPU 算子,可以將 idx 的類型轉為 int8/int16(視數值范圍而定避免溢出)避免引入的開銷,參考下圖:
當多個大尺寸的 op 做 add 時,若一次性 add 可能會引入帶寬問題。若存在帶寬問題,即 load&store 的時間大于計算時間,建議拆為逐個 add 相加,
使用示例以下提供兩個常見的對多個 eltwise 計算的使用示例,方式 1 為多次相加;方式 2 為一次相加。
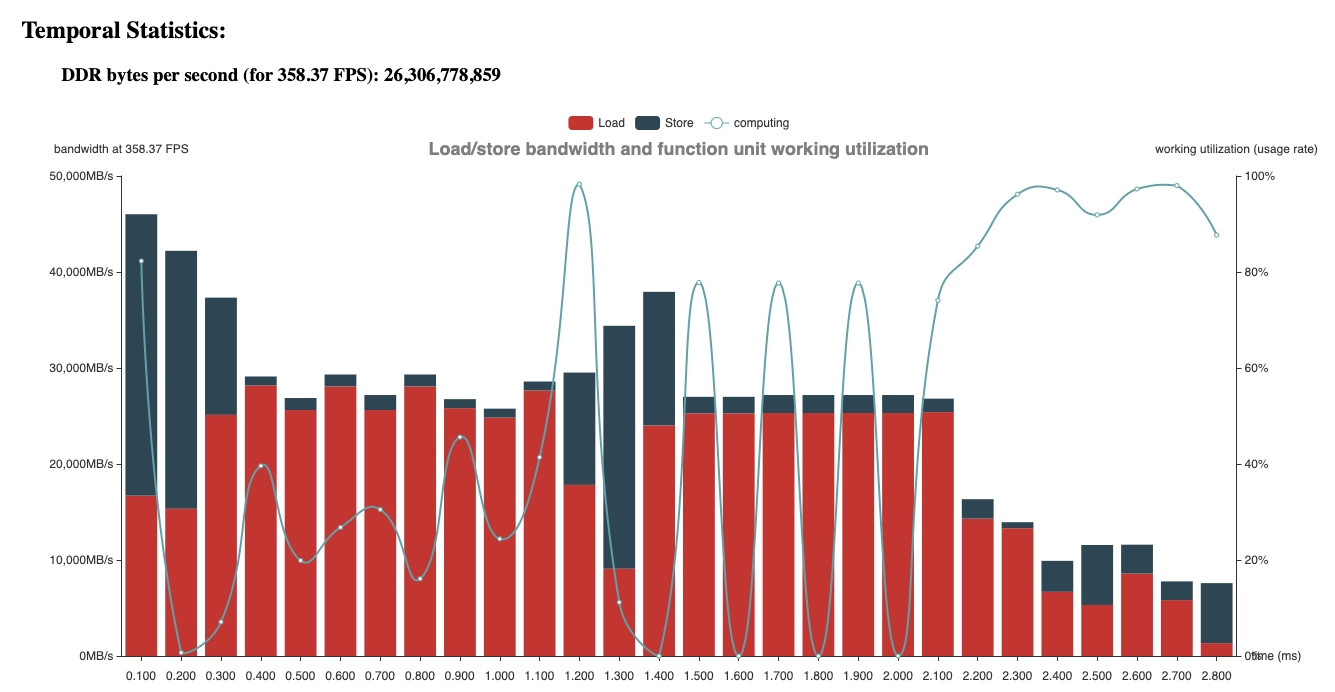
方式 1:
homo_feats = [] for i in range(12): homo_feat = self.grid_sample( feat, fpoints[i * B : (i + 1) * B], ) homo_dfeat = self.dgrid_sample( dfeat, dpoints[i * B : (i + 1) * B],
方式 2:
for i in range(12): homo_feat = self.grid_sample( feat, fpoints[i * B : (i + 1) * B], ) homo_dfeat = self.dgrid_sample( dfeat, dpoints[i * B : (i + 1) * B], )性能表現
以如下輸入大小來測試性能差異:
input = {
"feat": torch.randn(size=(1, 80, 238, 60)).to(torch.device("cuda:0")),
"dfeat": torch.randn(size=(1, 1, 1260, 2040)).to(torch.device("cuda:0")),
"fpoints": torch.randn(size=(12, 64, 256, 2)).to(torch.device("cuda:0")),
"dpoints": torch.randn(size=(12, 64, 256, 2)).to(torch.device("cuda:0")),
}Temporal Statistics:
方式 1:latency 為 3.267 ms
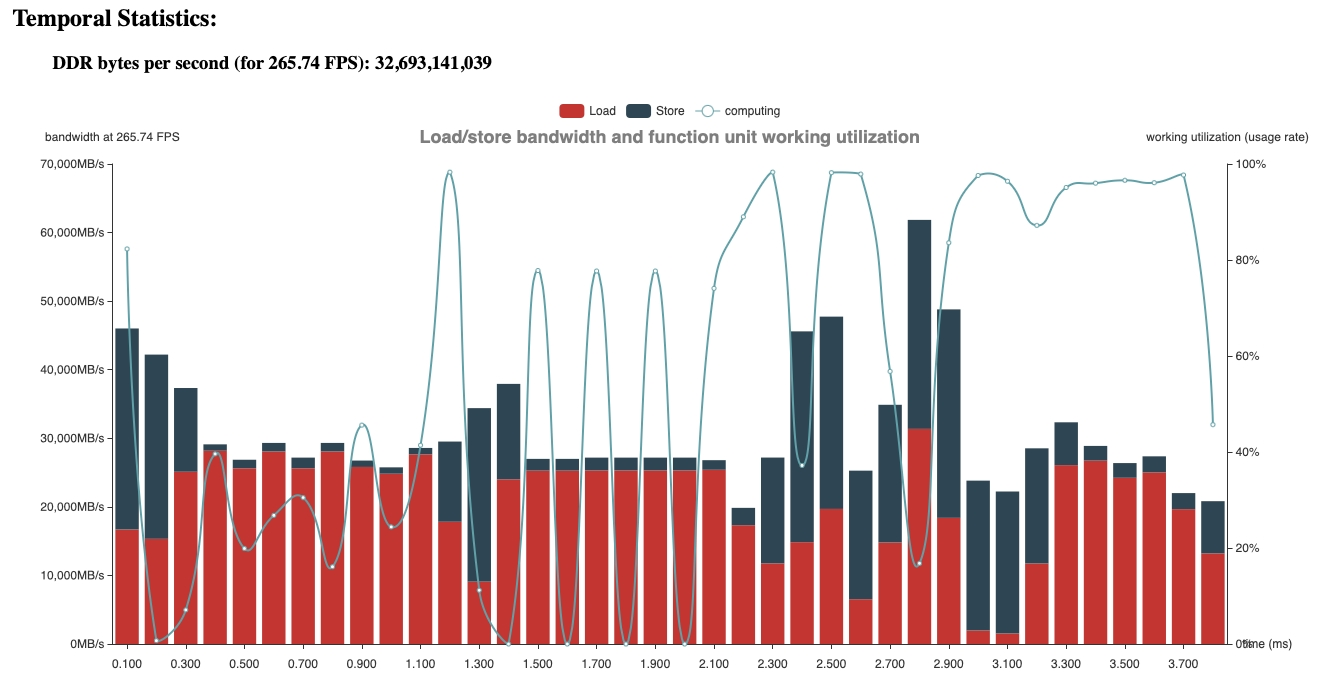
方式 2: latency 為 2.321 ms
https://cloud.tencent.com/developer/article/2509912
論文:https://arxiv.org/abs/2503.10622
Dynamic Tanh(DyT)是由何愷明、Yarnn LeCun 等研究者提出的新結構,用于替代 Transformer 中的歸一化層(如 LayerNorm),原理簡單,在于歸一化層的 input-output mapping 曲線近似 tanh 函數,可以直接使用 tanh 函數來擬合線性歸一化層的效果。其設計簡單高效,僅需 9 行代碼即可實現,展現出優于或持平傳統歸一化層的性能,不僅部署性能明顯優于 ln,訓練速度也會有明顯提升:
class DyT(nn.Module): def __init__(self, num_features, alpha_init=0.5): super().__init__() self.alpha = nn.Parameter(torch.ones(1)*alpha_init) self.weight = nn.Parameter(torch.ones(num_features)) self.bias = nn.Parameter(torch.zeros(num_features)) def forward(self, x): x = torch.tanh(self.alpha * x) return x * self.weight + self.bias
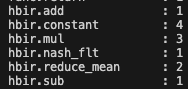
對于 transformer 模型的 征程 6 部署,替換為 dyt 也是一個很高效的選擇,layernorm 會被拆分為 8 個算子,而 dyt 只有 4 個算子,且避免了 reducemean 的計算(相對來說不是那么高效,且量化不友好),部署性能以及量化友好度都有提升。
論文:https://arxiv.org/pdf/2206.08898
SimA 針對傳統 Transformer Self-Attention 存在的主要問題,例如長序列任務的計算復雜度高;softmax 指數運算導致的梯度爆炸或消失等,完全移除 Softmax,采用線性相似度計算降低計算復雜度,同時保持模型近似表達能力,在主流的 ViT/NLP 模型中取得相當或更好的模型精度同時,有效降低了部署推理的延時,同時減少了訓練時間
import torch import torch.nn as nn import torch.nn.functional as F # SimA實現 class SimAttention(nn.Module): """ SimA attention block """ def __init__(self, embed_dim, num_heads=8, qkv_bias=False, proj_drop=0.):
值得注意的是,實際使用中,在多層 attention 的 encoder 結構中,如果使用 SimA 做替換優化,往往保留最后一層為傳統 softmax attention 做數值修正來保證模型整體精度效果,避免每層線性歸一化帶來的累計數值誤差從而對 encoder 輸出產生影響
2.1.6 Norm 優化從計算效率從高到低排序:batchnorm > dyt > layernorm/instancenorm > groupnorm
但在實際算法場景中例如 transformer 類的模型,替換 batchnorm 后浮點精度可能無法訓回來,因此 layernorm 更常用,此外還有 groupnorm 和 instancenorm
對于 group norm 而言,groups=1 就是 layernorm,groups=channels 就是 instancenorm,所以對于 group norm 的實現:
plugin 導出時通過 transpose+reshape 將 gn 轉成 ln
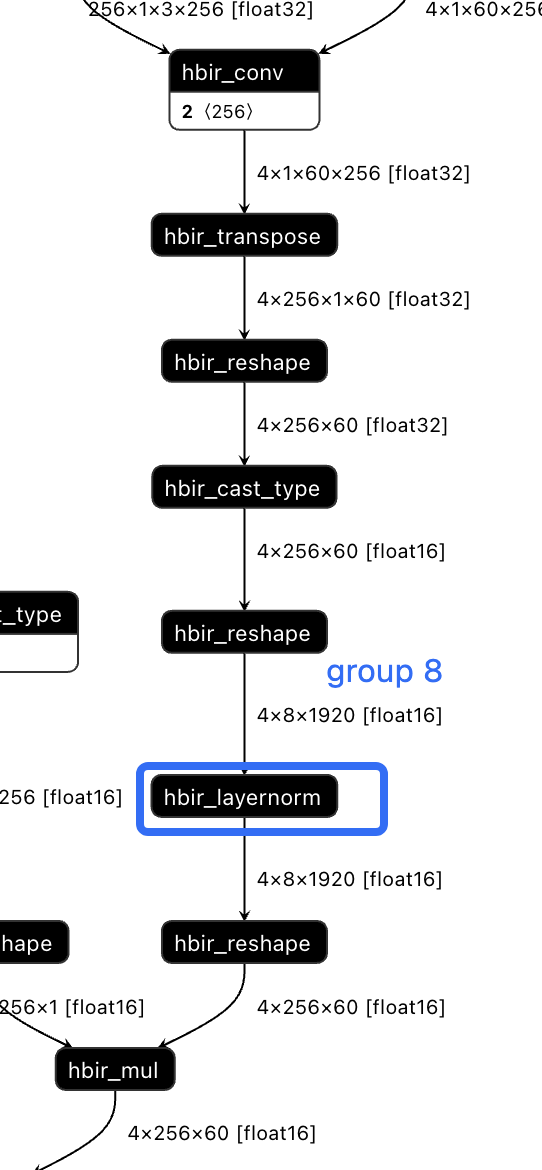
經實驗 layernorm 比 group norm 要快(因為可以避免前后 reshape),但是用戶手動將 group norm 替換 layernorm1d,需要手動在前后加 permute(因為 ln 從最后一維開始 norm),替換比較麻煩。使用下面的方式對 channel 維度做 norm,同時避免引入前后的 permute:
from horizon_plugin_pytorch.nn.layer_norm import SplitLayerNorm SplitLayerNorm(normalized_shape=[c, 1], dim=1)2.1.7 nn.Embedding 優化
torch.nn.Embedding 要求輸入 tensor 為 LongTensor,也就是 int32/int64,對于 E/M 而言會引入 bpu 不支持的 cast 算子從而跑在 cpu 上影響性能,常規的做法是。to(torch.int16).to(torch.int64),但是只對初始權重的模型有效(scale=1)可以融合。但對于真實權重的模型而言,會引入 dequantize+cast:
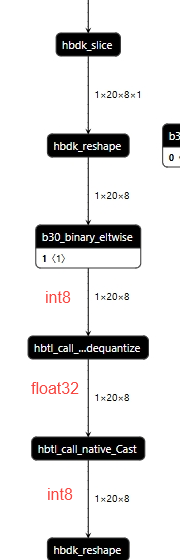
例如下面結構,讓 embedding 的一路維持定點類型可優化
data = {
# 定點輸入
"sdnavi_link_tbt_info": torch.ones((2, 20, 8, 7), dtype=torch.int16),
# 浮點輸入
"sdnavi_link_info": torch.ones((2, 20, 8, 256), dtype=torch.float32),
}
class Encoder(nn.Module):
def __init__(self,
...對定點數 tensor 的 quant 需要給 scale=1 的 fix_scale 配置,參考如下
module_name_qconfig = {
"quant": QConfig(
output=FakeQuantize.with_args(
observer=FixedScaleObserver,
dtype=qint8,
scale=1,
)
),
}優化后可實現 BPU 全一段。
2.2 精度優化2.2.1 Inverse_sigmoid 部署方案Inverse sigmoid 容易出現 bc 導出掉點問題,若遇到此問題:
方式一:將 segmentlut 的參數從"curvature"改為"evenly"。
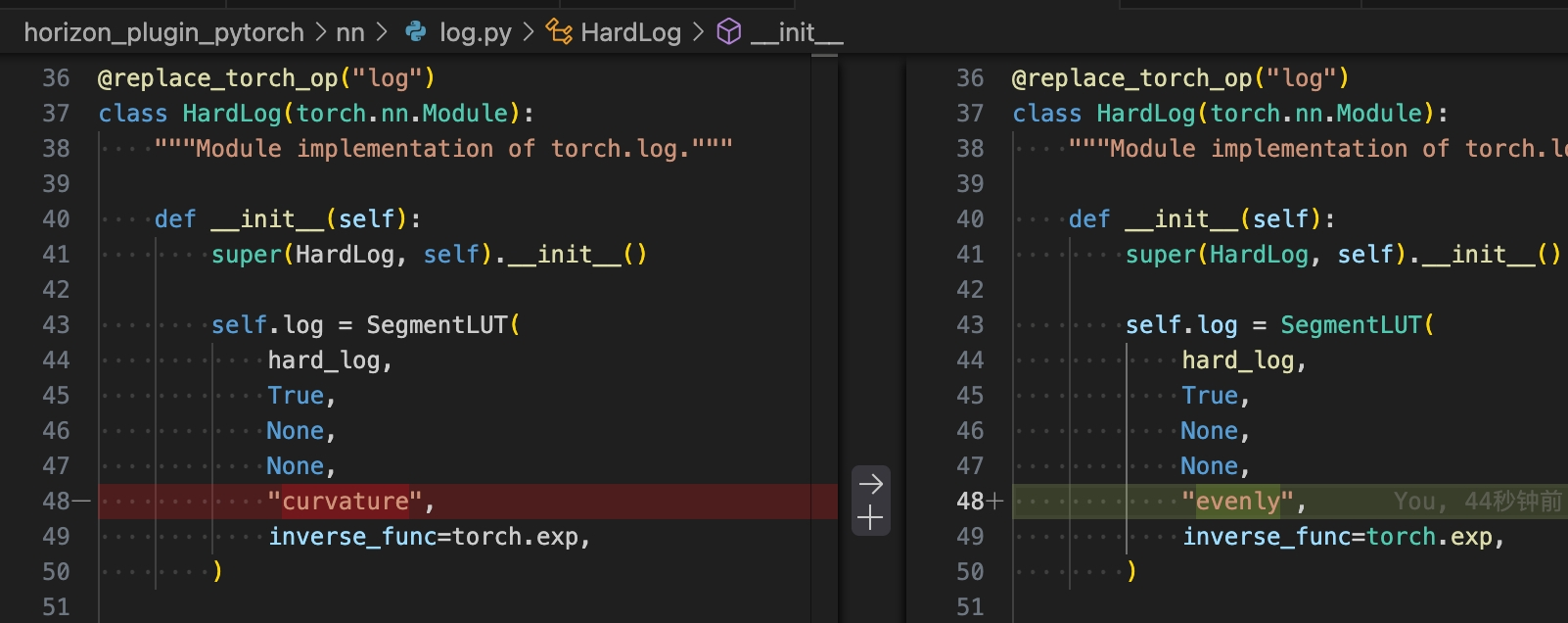
方式二:算法上去除 Inverse sigmoid 算子,對 sigmoid 的輸入做 clamp(需重訓,此方案需要驗證對浮點的影響。)
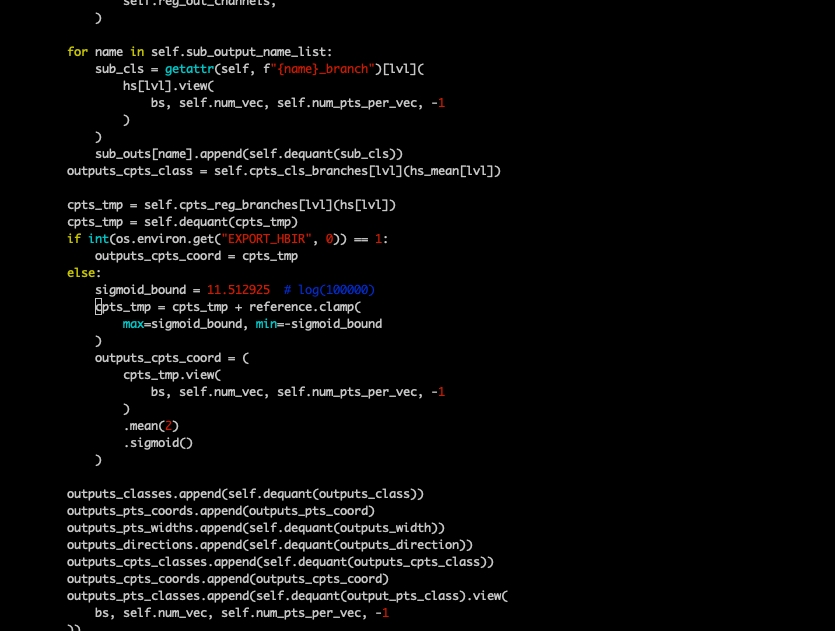
2.2.2 Gridsample 拆分注意:此示例中為提高 torch qat 精度,將+reference sigmoid 放在了 cpu,若 torch qat 并不存在精度問題可以放在 bpu 中。
11.5219 為 inverse_sigmoid 的輸出上限
由于 BPU 采用定點數值計算,grid_sample 算子在處理較大的 W 維度時,受限于硬件位寬精度,量化后的數值無法精確表示原始網格坐標,導致 nearest (最近鄰)和 bilinear (雙線性插值)兩種采樣方式均引入一定的精度誤差。
示例:
class OriGridSample(nn.Module): def __init__(self): super(OriGridSample, self).__init__() self.unitconv = nn.Conv2d(1, 1, (1, 1)) nn.init.constant_(self.unitconv.weight, 1) nn.init.constant_(self.unitconv.bias, 0) self.gridsample = hnn.GridSample( mode='bilinear', padding_mode='zeros', align_corners=True,
拆分后:
class SplitGridSample(nn.Module): def __init__(self): super(SplitGridSample, self).__init__() self.unitconv = nn.Conv2d(1, 1, (1, 1)) nn.init.constant_(self.unitconv.weight, 1) nn.init.constant_(self.unitconv.bias, 0) self.gridsample1 = hnn.GridSample( mode='bilinear', padding_mode='zeros', align_corners=True,2.2.3 Sin/Cos 算子去周期
export 時如果發現敏感度排在前面的是 sin/cos 算子,且輸入范圍較大(超出-pi~pi 一個周期),可以將 sin/cos 替換為 plugin 的自定義算子,并配置 single_period=True,注意需要重新做量化
import horizon_plugin_pytorch.nn as hnn class modelnet(nn.module): def __init__(self,): ... self.sin=hnn.Sin(single_period=True) self.cos=hnn.Cos(single_period=True)
也可以自行處理 sin/cos 輸入,按照周期性將輸入處理到[-pi, pi)之間,注意需要重新做量化
x = x - 2 * torch.floor(x * ( 0.5 / torch.pi) + 0.5) * torch.pi2.2.4 Conv/Linear weight 高低位拆分
該方案為保障 conv 的高精度計算,對 weight 對高低位的拆分。在用戶不重訓浮點的情況下,量化訓練前需要對用戶的浮點 ckpt 部分 linear weight 進行高低位拆分:
方式 1:通過修改 plugin 源碼方式,需要將紅框后面的減法去掉
方式 2:對 model 做拆分:
#=============== 用戶原 model ============= self.enc_bbox_head = MLP(hd, hd, 4, num_layers=3) class MLP(nn.Module): """Very simple multi-layer perceptron (also called FFN)""" def __init__(self, input_dim, hidden_dim, output_dim, num_layers): super().__init__() self.num_layers = num_layers h = [hidden_dim] * (num_layers - 1) self.layers = nn.ModuleList(
Ckpt weight 拆分:
def update_state_dict_task(state_dict, input_sequence_length=None):
state_dict_new = copy.deepcopy(state_dict)
state_dict_new["sparse_dynamic_vehicle_head.head.sparse_dynamic_head.transformer.decoder.norm1_1.weight"] = copy.deepcopy(state_dict["sparse_dynamic_vehicle_head.head.sparse_dynamic_head.transformer.decoder.norm1.weight"])
state_dict_new["sparse_dynamic_vehicle_head.head.sparse_dynamic_head.transformer.decoder.norm1_1.bias"] = copy.deepcopy(state_dict["sparse_dynamic_vehicle_head.head.sparse_dynamic_head.transformer.decoder.norm1.bias"])
for k, v in state_dict.items():
if "sparse_tl2d_head." in k:
params = copy.deepcopy(v)
new_key = k.replace("sparse_tl2d_head", "traffic_light_head")2.2.5 Matmul 高低位拆分OE 3.5.0 已經支持 matmul 雙 int16 的量化,如需要雙 int16 輸入則配置兩個輸入為 int16 量化即可。若使用時存在 CPU 的 bitshift,可以開啟 VPU 使其運行到 VPU 中,若不需要 VPU 或雙 int16 存在性能問題時則需要用戶在前端手動的對矩陣做拆分,用雙 int8 模擬 int15,達到高精度的效果。
拆分思路:A*(B+C)=AB+AC,B 為原 scale 能表示的 int8 的最大部分,C 為剩余部分。
self.mod = MAX(T_mat) / 128 # MAX-max absolute value T_mat_high = torch.trunc(torch.div(T_mat, self.mod)) * self.mod T_mat_low = torch.fmod(T_mat, self.mod) T_mat_high = self.quant_high(T_mat_high) # int8, fixed-scale with scale==self.mod T_mat_low = self.quant_low(T_mat_low) # int8, no need fixed-scale sample_points_pv = torch.matmul(sample_points, T_mat_high) + torch.matmul(sample_points, T_mat_low)
該方案 matmul 為 int15 計算,工具為 int16。實際使用時可根據性能和精度做平衡。
也可以通過修改 plugin 源碼方式自動做拆分,需要將紅框后面的減法去掉:
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。
相關推薦
為什么可擴展高性能 SoC 是自動駕駛汽車的未來
加密算法之MD5算法
[轉帖]us/os就緒表的維護算法分析
無線傳感器網絡低功耗分簇路由算法設計
自動駕駛的現狀與未來(節選)
攜手ADI贏得未來
求FSK信號的解調算法,主要是鐵路上的移頻信號!
采用Mean-Shift和Camshift算法相結合的火焰視頻圖像跟蹤設計
ZF與SiliconAuto推出用于自動駕駛的實時I/O芯片
PID算法
自動駕駛的時代,呼喚線控底盤
基于LPC2138的血壓測量算法開發平臺電路圖
計算機科學與技術反思錄(2)
vxwokrs下靜態圖像壓縮算法(上)
數字PID控制算法之一
加快實現自動駕駛(完整小組討論)
數字PID控制及其改進算法的應用
物理人工智能如何在自動駕駛和電動汽車中應用?
有關指紋算法
采埃孚與SiliconAuto推出自動駕駛實時I/O接口芯片
目標跟蹤算法在紅外熱成像跟蹤技術上的應用
英偉達 “全天候” 芯片實現毫秒級人臉檢測
76-81GHz自動駕駛CMOS RADAR
賦能自動駕駛和機器人感知,讀懂二維可尋址VCSEL | 硬科技有點意思
簡單實用的單片機CRC 快速算法
ADI:傳感技術助力未來自動駕駛的發展
日產聯手優步與 Wayve,計劃在東京推出自動駕駛出租車服務
地平線HSD引領智能駕駛普惠新時代
英偉達宣布與比亞迪、吉利展開自動駕駛業務合作
CRC算法原理及C語言實現