在【LLM】LLM 中 token 簡介與 bert 實操解讀一文中對 LLM 基礎定義進行了介紹,本文會對 LLM 中增量解碼與模型推理進行解讀。
一、LLM 中增量解碼定義
增量解碼(Incremental Decoding)是指在自回歸文本生成過程中,模型每次只計算并生成一個新的 token,并且會利用之前計算得到的中間結果,而不需要重新計算整個序列的表示,以此來提高生成效率和減少計算資源消耗。
在 GPT 系列模型生成對話回復、文章續寫等場景中廣泛應用了增量解碼。
二、增量解碼工作過程
初始輸入:在生成文本時,首先輸入一個初始的文本序列(比如一個問題或者提示詞 ),模型通過 Prefill 階段計算這個初始序列的隱藏狀態,同時生成并緩存與注意力機制相關的鍵(Key)和值(Value)矩陣,即 KV 緩存(KV Cache) 。
逐個生成 token:接下來進入解碼階段,模型會基于上一步生成的 token 和緩存的 KV 矩陣,計算當前位置的隱藏狀態,然后預測下一個 token。例如,在生成第一個 token 后,將其與之前緩存的 KV 矩陣結合,計算得到第二個 token 的隱藏狀態,進而預測第二個 token 。每生成一個新的 token,模型就更新相關的計算狀態,但不需要重新計算整個輸入序列的隱藏狀態,只是在之前計算結果的基礎上增量式地進行計算。
循環直至結束:重復上述步驟,直到達到預設的結束條件,比如生成了特定的結束標記、達到了最大文本長度限制或者滿足了其他停止生成的條件 。 總之,增量解碼通過復用計算結果和 KV 緩存,可以有效提升自回歸模型文本生成的效率和性能。
注意:當 KV cache 的長度超出閾值(例如 1024KB)會進行清理,清理策略取決于大模型的處理策略,有滑動窗口(清理最早的)和全部清理等。
三、新 token 選擇
模型在生成新 token 時,從可能的下一個詞表(token)中選擇一個特定的詞。詞表中有多個詞,詞的個數可以理解為 vocab size,其中每個位置的大小表示選取這個 token 的概率,如何基于這個信息選擇合適的 token 作為本次生成的 token。
貪婪采樣(Greedy Sampling) 在每一步,模型選擇概率最高的詞作為下一個詞。這種方法快速且計算成本低,但它可能導致重復。
隨機采樣(Random Sampling) 模型根據概率分布隨機選擇下一個詞。這種方法能夠引入隨機性,從而生成更多樣化的文本。但是,隨機性也可能導致文本質量下降,因為模型可能選擇低概率但不相關的詞。
Top-k 采樣(Top-k Sampling) 這種方法首先選擇 k 個最可能的詞,然后從這個子集中隨機選擇下一個詞。這種方法旨在平衡貪婪采樣的確定性和隨機采樣的多樣性。
四、Prompt(提示詞)
Prompt 是用戶與 LLM 交互的入口,Prompt 進入 Prefill 階段處理,并成為生成后續內容的“上下文語境”。其核心作用是引導模型生成特定類型、風格或內容的輸出。簡單來說,Prompt 就是你告訴模型 “要做什么” 的一段話。
在大模型推理中,Prompt 是用戶與模型交互的起點,它在 Prefill 階段被模型處理,作為生成后續內容的基礎。例如:
設計優質 Prompt 是激發 LLM 能力的關鍵,需要明確任務、約束條件和期望輸出,例如:明確任務指令/給出格式規范/提供上下文例子
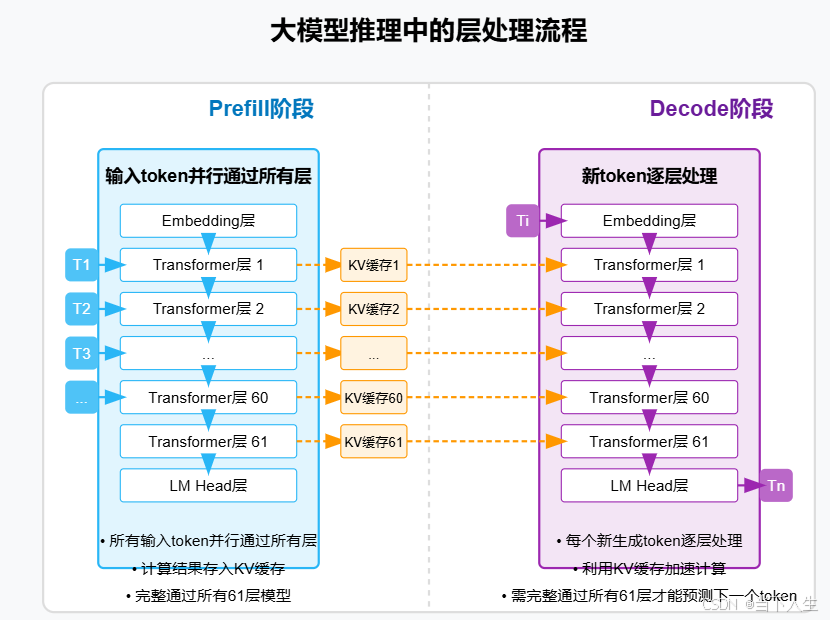
五、模型推理:Prefill 與 Decode
參考鏈接:https://blog.csdn.net/firehadoop/article/details/146341556
通過 KV Cache,避免了重復計算,提高生成效率。
prefill 與 decode 的關系類似于接力賽:Prefill 階段跑完第一棒,然后 Decode 階段接過接力棒,一個接一個地完成余下的路程。
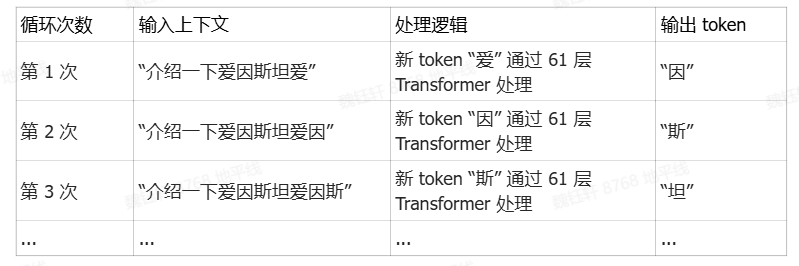
以查詢 “介紹一下愛因斯坦” 為例,其核心流程如下:
5.1 初始化階段(Prefill)
5.2 循環迭代解碼階段(Deocde)
5.3 小結
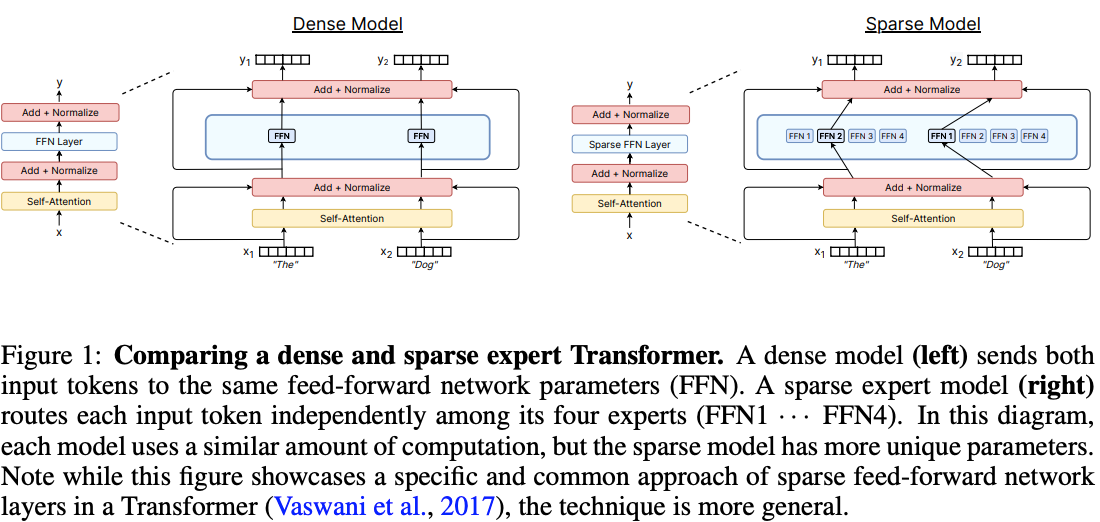
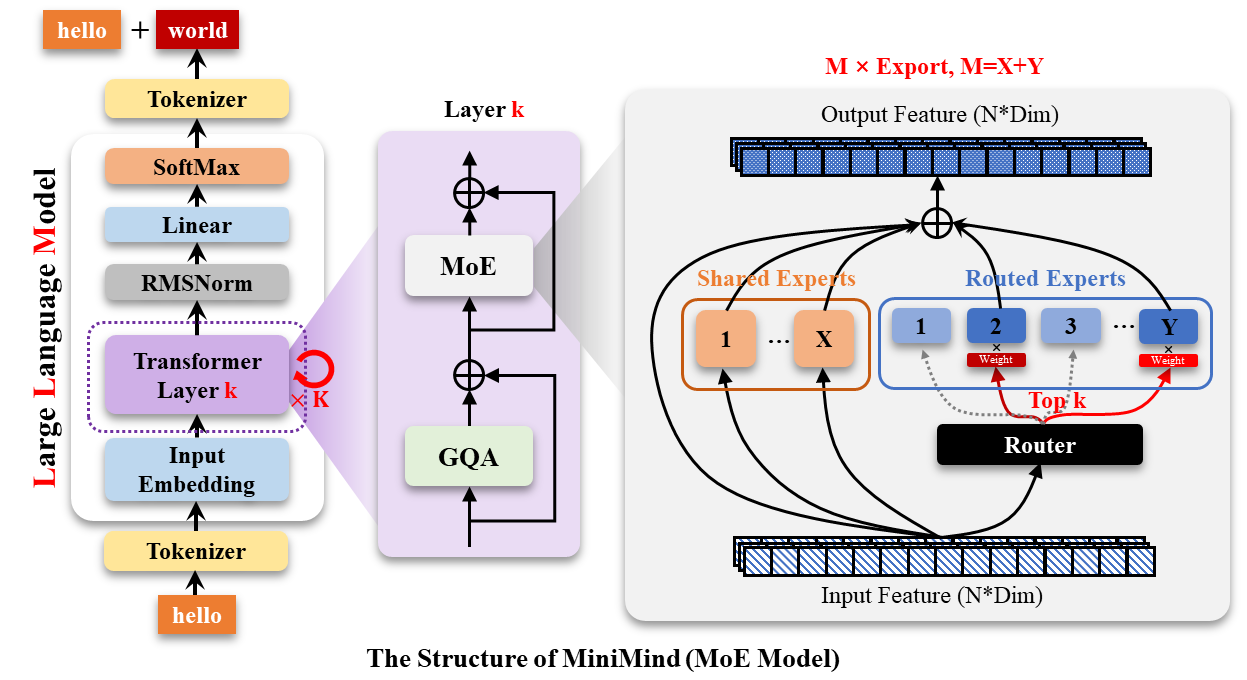
六、MoE 簡介
一般來說,一個 MoE layer 包含 N 個 Experts(FFN 網絡)和一個 Gating Network。其中 Gating Network 可以將一個 token routing(Token 路由)到少數的專家進行計算。可參考下圖:
總結:Token routing 就是給不同重要性、不同功能的 Token,規劃調用不同專家模型,讓大模型更聰明分配算力、協同專家能力,最終實現 “又快又準又省資源” 的推理。
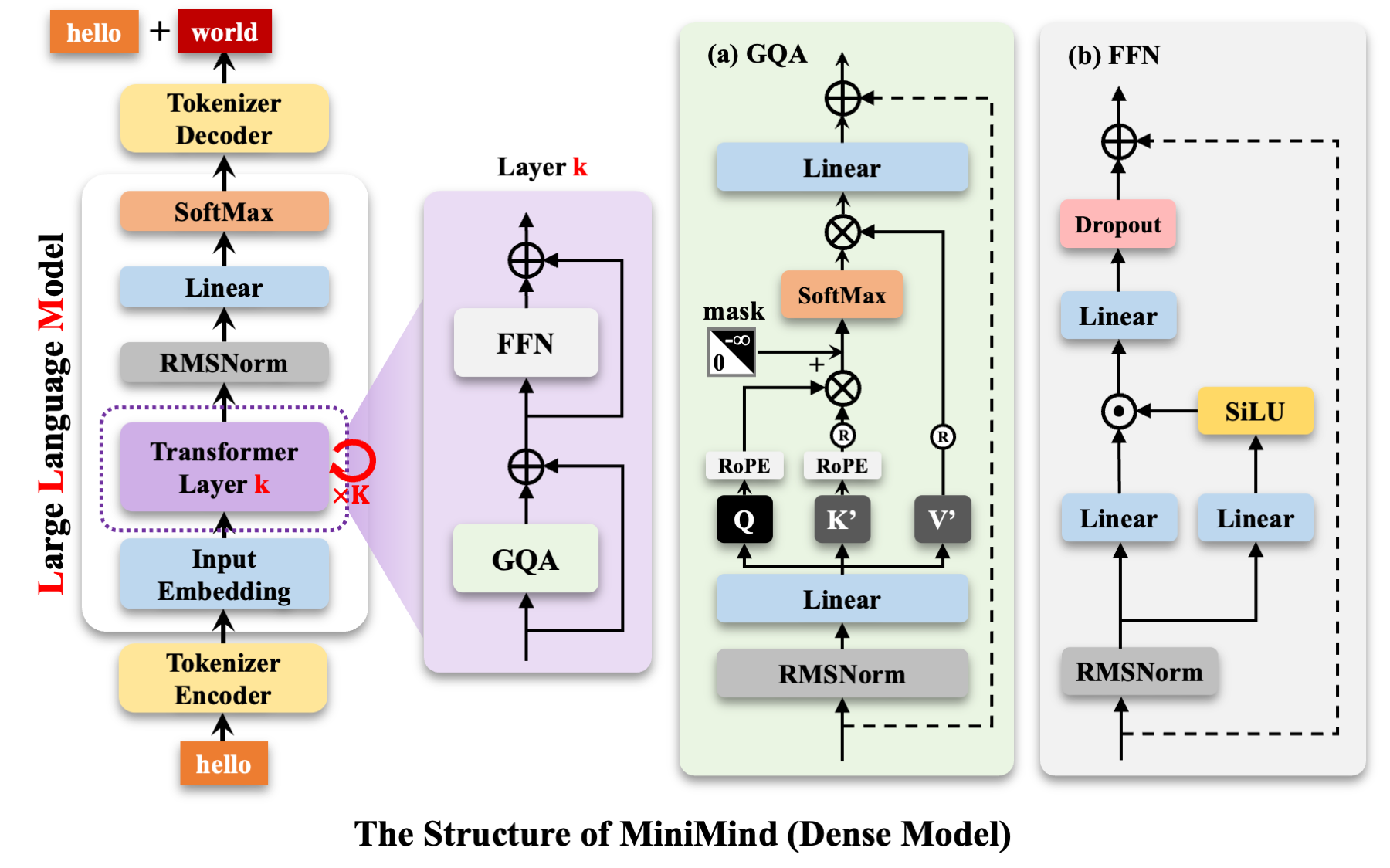
從整體看,MoE 在 LLM 模型的什么位置呢?如下圖:
參考 https://github.com/jingyaogong/minimind?tab=readme-ov-file