手撕大模型|KVCache 原理及代碼解析

一、為什么需要 KV Cache?
需要 重新計算所有之前 token 的 K 和 V,并與當前 token 進行注意力計算。
計算復雜度是 O(n2)(對于長度為 n 的序列)。
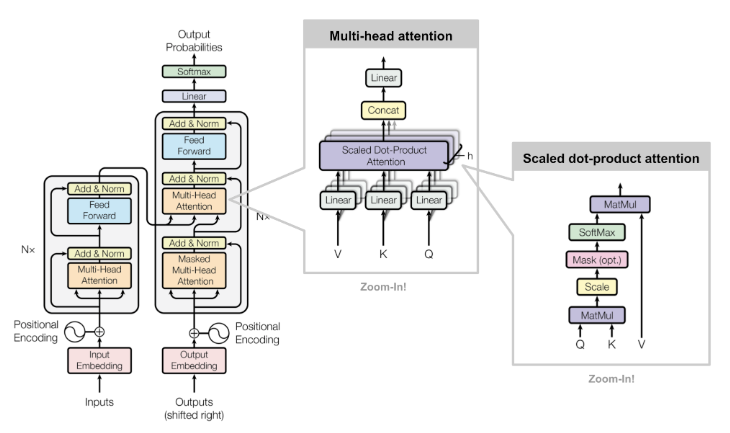
只需計算 新 token 的 K 和 V,然后將其與緩存的值結合使用。
計算復雜度下降到 O(n)(每個 token 只與之前緩存的 token 計算注意力)。
二、KV Cache 的工作原理
初始輸入: [t0, t1, t2] 首次計算: K=[K0,K1,K2], V=[V0,V1,V2] → 生成t3 緩存狀態: K=[K0,K1,K2], V=[V0,V1,V2] 第二次計算: 新Q=Q3 注意力計算: Attention(Q3, [K0,K1,K2]) → 生成t4 更新緩存: K=[K0,K1,K2,K3], V=[V0,V1,V2,V3] 第三次計算: 新Q=Q4 注意力計算: Attention(Q4, [K0,K1,K2,K3]) → 生成t5 更新緩存: K=[K0,K1,K2,K3,K4], V=[V0,V1,V2,V3,V4] ...
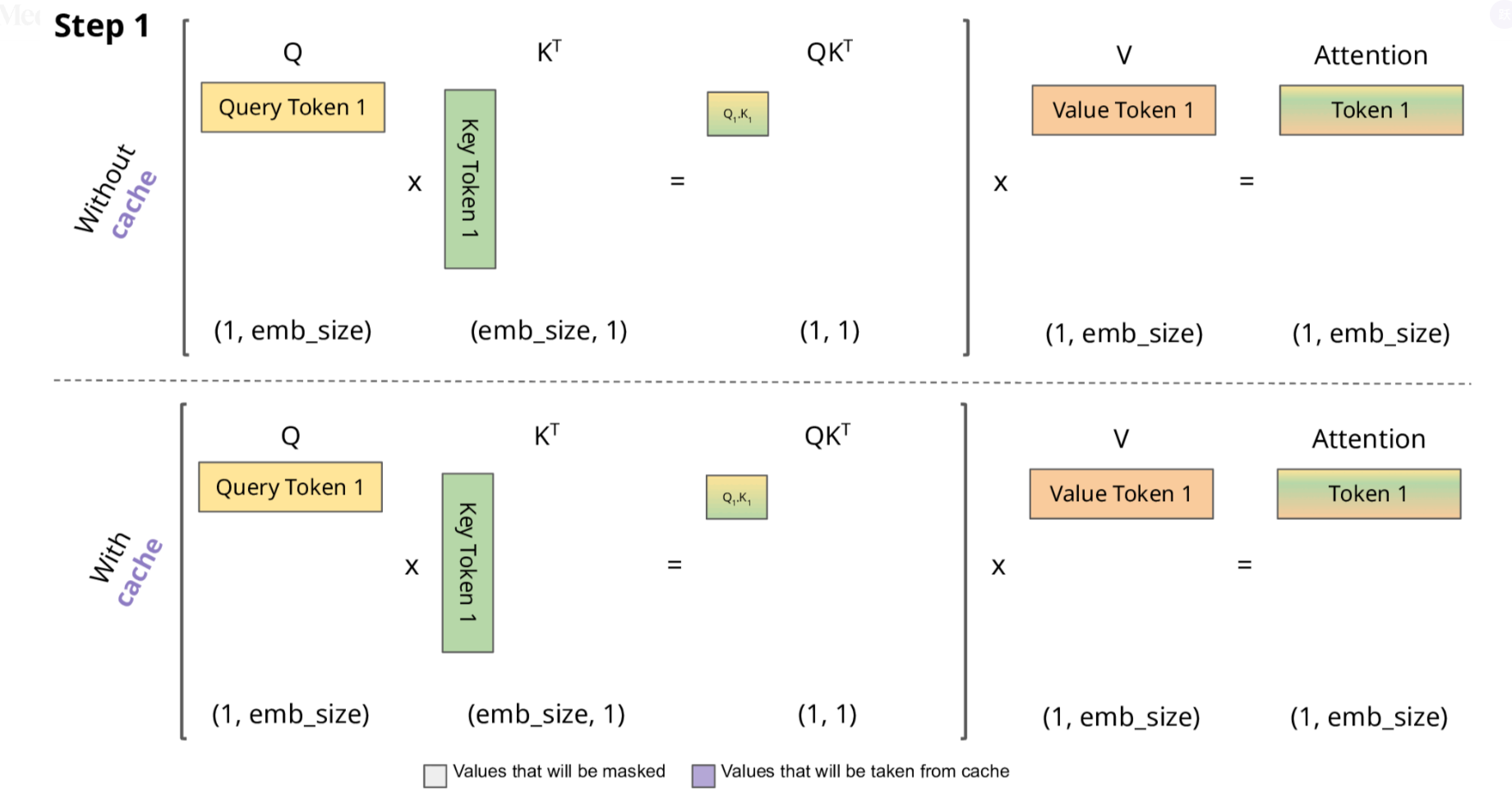
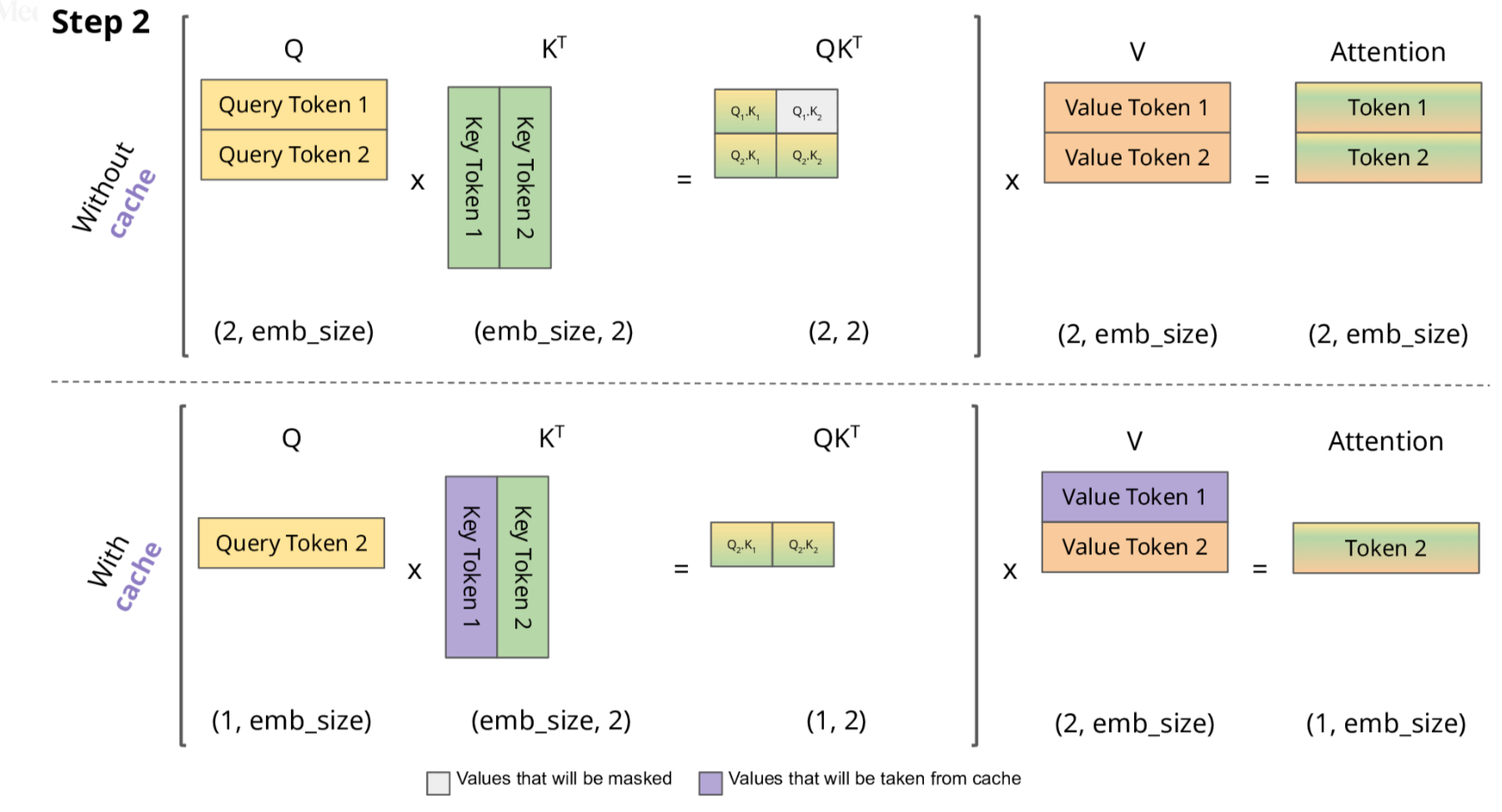
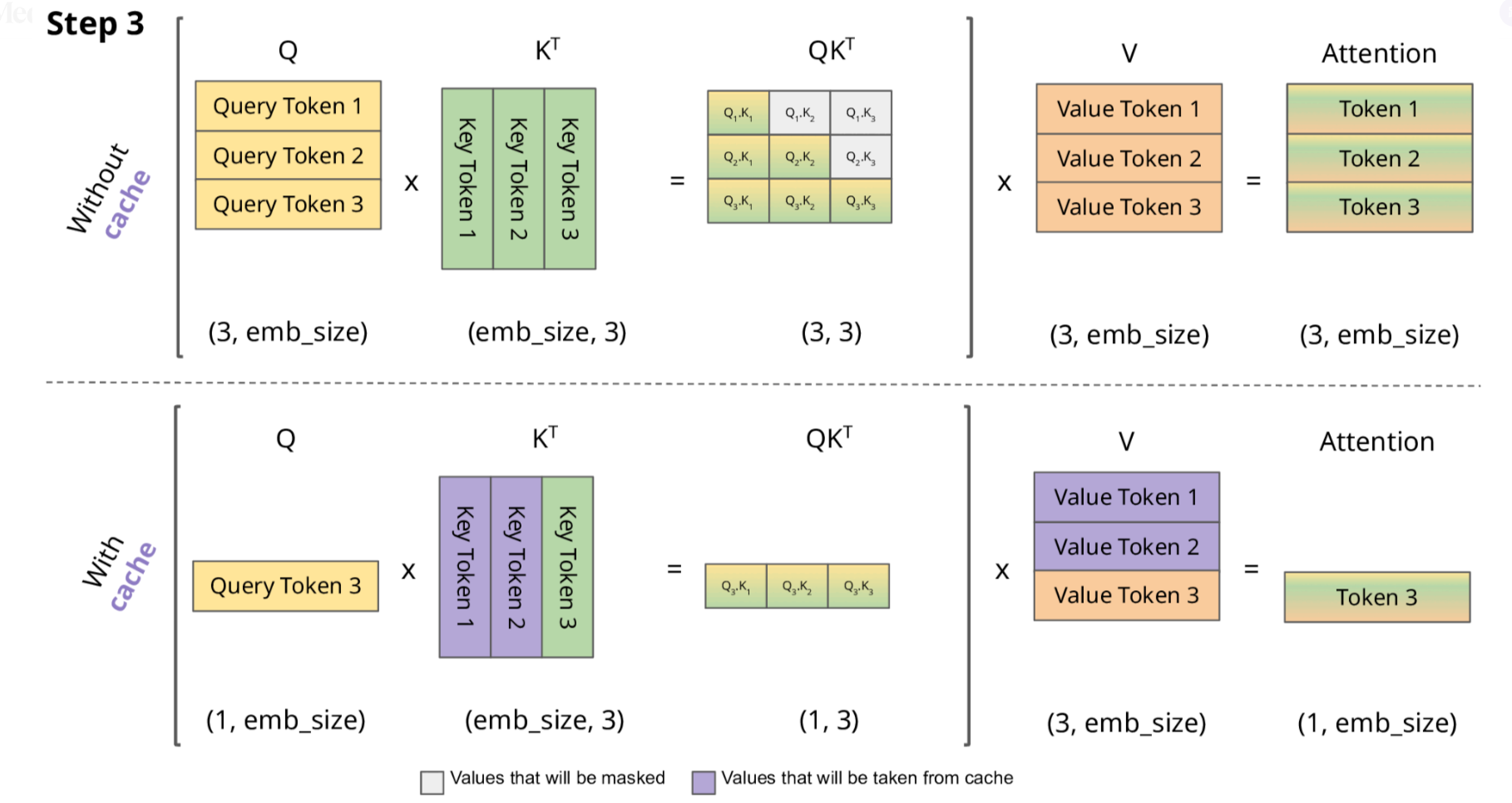
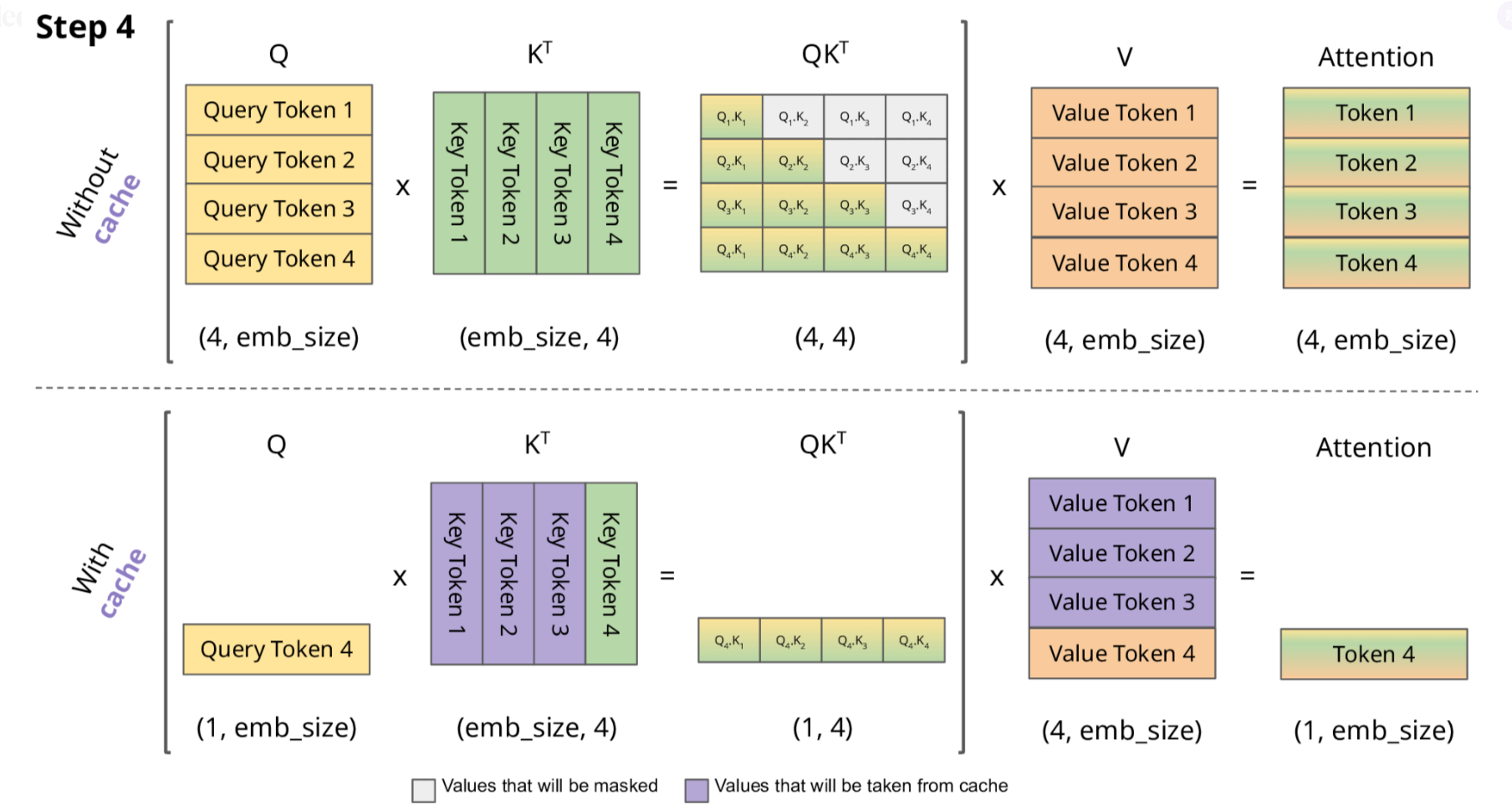
2.1 KV Cache 的技術細節
四、代碼實現解析
import torch import torch.nn as nn import torch.nn.functional as F class SelfAttention(nn.Module): def __init__(self, embed_dim, num_heads): super().__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim // num_heads # 定義Q、K、V投影矩陣 self.q_proj = nn.Linear(embed_dim, embed_dim) self.k_proj = nn.Linear(embed_dim, embed_dim) self.v_proj = nn.Linear(embed_dim, embed_dim) self.out_proj = nn.Linear(embed_dim, embed_dim) def forward(self, x): batch_size, seq_len, embed_dim = x.shape # 計算Q、K、V q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) # 計算注意力分數 attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) attn_probs = F.softmax(attn_scores, dim=-1) # 應用注意力權重 output = attn_probs @ v output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim) return self.out_proj(output)
class CachedSelfAttention(nn.Module): def __init__(self, embed_dim, num_heads): super().__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim // num_heads # 定義投影矩陣 self.q_proj = nn.Linear(embed_dim, embed_dim) self.k_proj = nn.Linear(embed_dim, embed_dim) self.v_proj = nn.Linear(embed_dim, embed_dim) self.out_proj = nn.Linear(embed_dim, embed_dim) # 初始化緩存 self.cache_k = None self.cache_v = None def forward(self, x, use_cache=False): batch_size, seq_len, embed_dim = x.shape # 計算Q、K、V q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) # 如果使用緩存且緩存存在,則拼接歷史KV if use_cache and self.cache_k is not None: k = torch.cat([self.cache_k, k], dim=-2) v = torch.cat([self.cache_v, v], dim=-2) # 如果使用緩存,更新緩存 if use_cache: self.cache_k = k self.cache_v = v # 計算注意力分數(注意這里的k是包含歷史緩存的) attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) attn_probs = F.softmax(attn_scores, dim=-1) # 應用注意力權重 output = attn_probs @ v output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim) return self.out_proj(output) def reset_cache(self): """重置緩存,用于新序列的生成""" self.cache_k = None self.cache_v = None
def generate_text(model, input_ids, max_length=50): # 初始化模型緩存 model.reset_cache() # 處理初始輸入 output = model(input_ids, use_cache=True) next_token = torch.argmax(output[:, -1, :], dim=-1, keepdim=True) generated = [next_token] # 生成后續token for _ in range(max_length - 1): # 只輸入新生成的token output = model(next_token, use_cache=True) next_token = torch.argmax(output[:, -1, :], dim=-1, keepdim=True) generated.append(next_token) # 如果生成結束符則停止 if next_token.item() == 102: # 假設102是[SEP]的id break return torch.cat(generated, dim=1)
五、KV Cache 的優化策略
六、總結
七、參考鏈接
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。





