部署邊緣檢測AI與卡爾曼濾波,實現自鎖與打嗝模式

1 濾波
卡爾曼濾波是一種利用線性系統狀態方程,通過系統輸入輸出觀測數據,對系統狀態進行最優估計的算法。它在信號處理、控制理論、導航等領域有著廣泛應用。
1.1 核心思想與基本假設
核心思想:通過融合系統的動態模型(預測)和實際觀測數據(校正),以遞歸方式估計系統狀態,最小化估計誤差的方差。
基本假設:系統是線性的(或可近似線性化)。噪聲符合高斯分布(過程噪聲和觀測噪聲均為白噪聲)。初始狀態的估計誤差已知。
1.2 數學模型與遞歸過程
卡爾曼濾波基于兩個關鍵方程:預測方程和校正方程,通過迭代更新實現最優估計。
1>狀態空間模型
狀態方程(系統動態模型):(x_k = A_kx_{k-1}+B_ku_k+w_k)其中:
(x_k)為k時刻的狀態向量;
(A_k)為狀態轉移矩陣;
(u_k)為控制輸入向量,(B_k)為控制矩陣;
(w_k)為過程噪聲,服從高斯分布(w_k sim N(0,Q_k))。
觀測方程(測量模型):(z_k = H_kx_k + v_k)其中:
(z_k)為觀測向量;
(H_k)為觀測矩陣;
(v_k)為觀測噪聲,服從高斯分布(v_k sim N(0,R_k))。
2> 遞歸過程(兩個階段)
階段1:預測(時間更新)
狀態預測:(hat{x}_{k|k-1} = A_khat{x}_{k-1|k-1} +B_ku_k)(基于前一時刻的最優估計預測當前狀態)。
誤差協方差預測:(P_{k|k-1} = A_kP_{k-1|k-1}A_k^T + Q_k)(預測當前狀態估計的不確定性)。
階段2:校正(測量更新)
卡爾曼增益計算:(K_k = P_{k|k-1}H_k^T(H_kP_{k|k-1}H_k^T + R_k)^{-1})(確定觀測數據對狀態估計的權重,平衡預測與觀測的不確定性)。
狀態更新:(hat{x}_{k|k} = hat{x}_{k|k-1} + K_k(z_k -H_khat{x}_{k|k-1}))(結合觀測數據修正預測狀態,得到最優估計)。誤差協方差更新:(P_{k|k} = (I - K_kH_k)P_{k|k-1})(更新當前狀態估計的不確定性,為下一時刻做準備)。
1.3 優勢
1> 無需存儲歷史數據,僅需當前觀測和前一時刻的估計,計算效率高,適合實時應用。
2> 可處理噪聲統計特性已知的系統,通過調整噪聲協方差矩陣(Q、R)適應不同場景。
1.4 使用
1> 添加程序,這里我放在了SOFTWARE 目錄下,將其添加到路徑下,與屏幕驅動引入相同,頭文件引入等,這里不贅述。
2> 變量聲明,首先需要聲明變量,每個數據源設置一個變量,若使用一個,各個數據會相互影響,


3>初始化,將我們上一步聲明的變量取地址,后面跟參數,

4>濾波,調用函數

代碼如下




![]()
這個函數以用于多種單片機中,可自行移植嘗試。
2 串口發送
這里和串口接收分開寫,前期還用不到接收,就不寫明。如果使用官方板卡建立工程,那么可以跳過第一步的cubemx 配置。
2.1 cubemx配置

使能串口2,設置為異步模式,其他保持默認,而后更新代碼。
2.2 重映射到printf函數


2.3 濾波后發送到串口
將下列放置在while中,cureer為浮點數,請確保已經打開浮點數pritf。

3 VOFA簡單配置
此時可以打開VOfa+進行數據收集選擇當前對應端口號,串口,波特率115 200。


其他默認即可,按左上角按鈕開啟串口:

查看有無數據進入:

左側選擇第四項控件,第一個就是示波器。

拖動到右側tab欄,右擊全部填充。

再右擊,如圖將數據引入Y軸。

可以通過修改輸入傳入是否濾波,觀察對比濾波前后的樣子。

4 模型訓練
完成上兩部分準備工作后,我們就可以進行模型的訓練了新建項目需要通過串口進行數據采集,簡單介紹一下Nanoedge AI Studio是用于STM32部署邊緣AI的軟件,Studio可生成四種類型的庫:異常檢測、單分類、多分類、預測。
它支持所有類型的傳感器,所生成的庫不需要任何云連接,可以直接在本地學習與部署,支持STM32所有MCU系列。

意味著你可以將模型部署在任意的MCU,大小限制可以自行選擇。
其他廠商的MCU不確定能否支持這里的模型。
正式開始前請先關閉VOfa+的串口連接。
4.1 新建模型訓練工程
打開NanoEdge AI Studio,點擊NEW PROJECT:

選擇第一項,大意是使用設備學習檢測信號中的異常使用模型識別數據中的異常模式。
該模型可以在學習階段適應并逐步收集知識,以預測潛在的異常行為。
我們需要用到檢測,選擇這個即可:

設置工程名稱,選擇MCU或板卡等,數據類型選第二項Current電流:

4.2 信號采集
進入這個界面,上面是正常信號,下面是異常信號,配置方式相同。

以正常信號為例。

串行USB信號,文件導入和采集器。
我們剛剛使用串口發送電流信號,因此選擇串行USB信號。

其他默認,如果你只想采集需要的數據條數,勾選最多數據限制。
確保你的電機正常運轉,點擊START開始。

采集完成導入數據。
完成后再進行異常信號采集。
需要注意一點,請將電機在故障狀態下運行,例如負載過大限制轉速等。
其他步驟與上述正常采集相同,這里不在贅述。
4.3 模型訓練
選擇左上角添加,打開如下界面,勾選正常與異常數據后開始訓練。

整個過程相對較慢。

運行時主要使用CPU,設置中也沒有GPU 的相關選項,此過程大概不需要顯卡(截至2025 年5 月23 日5.02 版本)。筆者的配置如下:
13th Gen Intel(R) Core(TM)i9-13900H 加32G 內存
105 條正常信號,229 條異常信號。
總共用時兩2 小時12 分25 秒。

先看一下跑完的樣子,這是整個模型的參數,質量指數99.3 分,質量高還是很高的,準確率99.8%,占用RAM 0.1 kB,占用flash 1.9 kB。

這個是演變圖,藍色是質量指數,綠色是精準度,藍色是RAM,紅色是flash。
這里能實時且直觀的展示整個模型訓練的狀態。

訓練軌跡:

歷史迭代:

還有其他圖像這里就不展示了,如果你訓練過yolo模型會發現這個過程的演變和迭代是很相似的。
4.4 模型測試與繼續訓練

這個過程可以繼續對模型進行訓練,也可以進行測試,模型訓練結果我比較滿意,就不繼續訓練了。
測試
點擊本地運行:

先是對正常信號進行采集學習,確保電機正常工作后,點擊開始:

采集足夠的信號后,點擊進行GO TO DETECTION轉到檢測:

整個過程很準確,效果如下:

4.5 獲取模型與部署
按照如下勾選,我們是單模型,需要程序接口,數據類型是浮點數。
而后點擊部署庫:

將得到的壓縮包解壓后得到如下文件,主要用到這兩個文件,一個是庫,另一個是調用的API接口。


5 工程構建
5.1 文件配置
如圖所示。這樣放置是個人習慣,你也可以將它放置在任意順眼的地方。

添加路徑到源文件。

包含:

庫路徑。

庫名稱,命名為neai。

5.2 添加必要程序
參考生成偽代碼:



引用頭文件后和定義后,添加必要參數,寫入緩存。

學習,這里我用OLED顯示進行的過程,由于學習速度太快,我這里用了延時。

更新事件:

串口回傳數據:
printf(“%d,%.2f,%.2f,%.2frn”,similarity,current,busVoltage,power);
整個工程框架構建完成。
詳細過程請參考附件的工程。
6 加入中斷接收
回到cubeMX,找到串口,使能串口中斷。

重新生成后在while前添加開啟中斷。

重新定義中斷回傳函數,先判斷是不是我們的串口2發送過來的,然后在里面寫入我們的需求。



其中回傳末尾重新開啟中斷:

![]()

![]()
串口結束與清除位數:


中斷接收完成。
7 自鎖模式與打嗝模式
以下是自鎖模式與打嗝模式,請分別注釋后使用。


其中switch_clocks 是全局變量,會根據中斷接收到的字符進行更新,從而實現自鎖或打嗝。
繼電器函數定義


定義的繼電器GPIO。
(本文來源于《EEPW》202508)

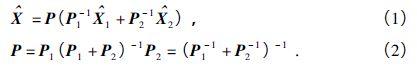
評論