存儲還要繼續瘋!英偉達ICMSP讓閃存漲停,黃仁勛要一統存儲處理器

英偉達推出全新推理上下文(Inference Context)內存存儲平臺(ICMSP),通過將推理上下文卸載(Offload)至NVMe SSD的流程標準化,解決KV緩存容量日益緊張的問題。該平臺于 2026 年國際消費電子展(CES 2026)正式發布,致力于將GPU的KV緩存(Key-Value Cache)擴展至基于 NVMe 的存儲設備,并獲得英偉達 NVMe 存儲合作伙伴的支持。
此消息一出,引爆的是本就漲到高不可攀的存儲廠商股價,多家存儲廠商和閃存控制器廠商股價直接漲停,閃存極有可能步DRAM后塵成為AI基建帶動下第二波緊俏存儲器,存儲價格特別是閃存價格在2026年可能成為存儲產品整體價格繼續飆漲的第二輪推動力。從某個角度考慮,ICMSP的推出,讓GPU芯片可以降低對大容量HBM產品的嚴重依賴,同時也讓AMD同步發布的Helios機架平臺變得有些“過時”,因為英偉達已經邁向了存算結合的新階段。
不過相比這些,黃仁勛在解答分析師問題時更是直言“我們現在是全球最大的網絡公司。我預計我們還將成為全球最大的存儲處理器公司”,通過不斷收購存儲技術,英偉達致力于在AI算力體系架構中,擁有更多的話語權。從這點來看,ICMSP將成為英偉達在AI走向千行百業的工程化過程中主導的技術之一。
認識一下ICMSP
在大型語言模型推理過程中,KV緩存用于存儲上下文數據 —— 即模型處理輸入時,表征令牌間關系的鍵(keys)和值(values)。隨著推理推進,新令牌參數不斷生成,上下文數據量持續增長,往往會超出 GPU 的可用內存。當早期緩存條目被淘汰后又需重新調用時,必須重新計算,這會增加延遲。智能體 AI(Agentic AI)和長上下文工作負載進一步加劇了這一問題,因為它們需要保留更多上下文數據。而 ICMSP 通過將 NVMe 存儲上的 KV 緩存納入上下文內存地址空間,并支持跨推理任務持久化存儲,有效緩解了這一困境。
英偉達創始人兼CEO黃仁勛表示:“人工智能正在徹底變革整個計算架構 —— 如今,這場變革已延伸至存儲領域。人工智能不再局限于一次性交互的聊天機器人,而是能理解物理世界、進行長周期推理、立足事實、借助工具完成實際工作,并具備短期和長期記憶的智能協作伙伴。借助BlueField-4,英偉達與軟硬件合作伙伴正為人工智能的下一個前沿領域重塑存儲架構。” 他在CES演講中提到,通過BlueField-4,機柜中可直接部署KV緩存上下文內存存儲。
隨著 AI 模型規模擴展至萬億參數級別,且支持多步驟推理,其生成的上下文數據量極為龐大,同時運行的此類模型數量也在不斷增加。KV 緩存軟件(即 ICMSP)需適配GPU、GPU 服務器及 GPU 機柜集群,這些設備可能同時處理多種不同的推理工作負載。每個模型 / 智能體工作負載的參數集都需妥善管理,并能精準對接運行在特定 GPU 上的目標AI模型或智能體 —— 且這種對應關系可能隨任務調度動態變化。這意味著需要專門的 KV 緩存上下文元數據管理機制。
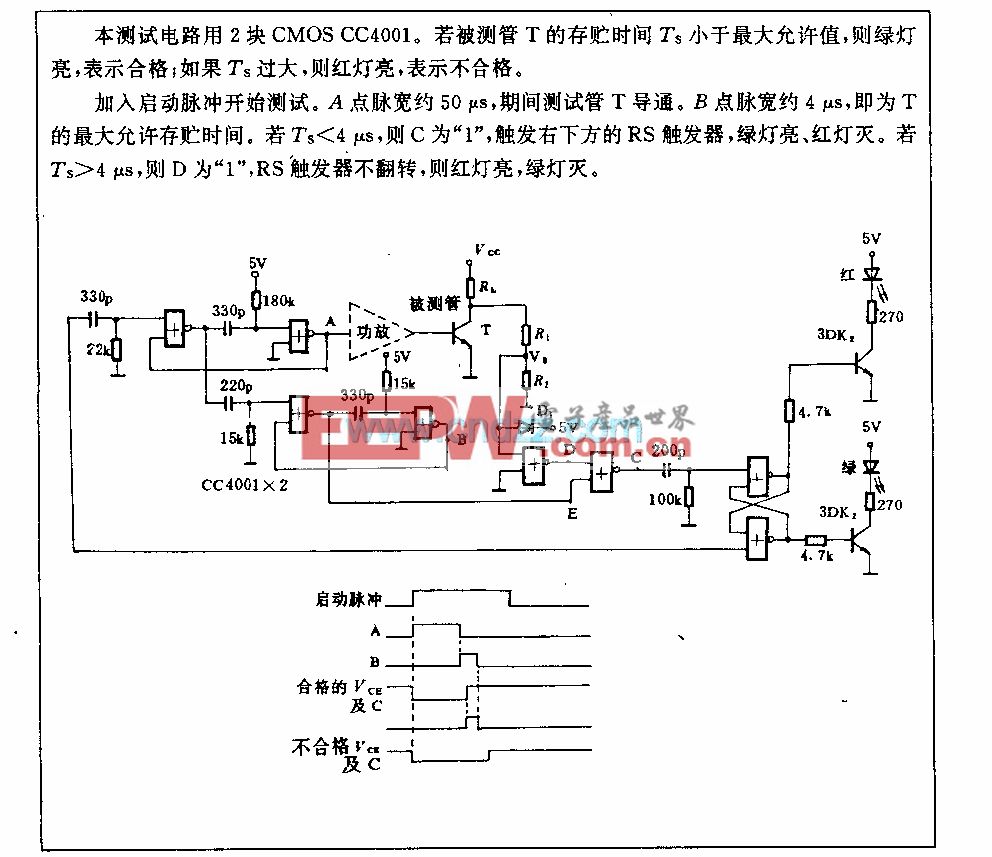
基于NVMe的KV緩存存儲需實現跨層級兼容,涵蓋 GPU、GPU 服務器、GPU 機柜乃至多機柜集群。英偉達表示,ICMSP 不僅提升了 KV 緩存容量,還加速了機柜級 AI 系統集群間的上下文共享。多輪交互 AI 智能體的持久化上下文特性,提高了響應速度,提升了 AI 工廠的吞吐量,并支持長上下文、多智能體推理的高效擴展。

圖1 基于 NVMe 的 KV 緩存存儲需實現跨層級兼容,覆蓋GPU、GPU 服務器、GPU機柜乃至GPU機柜集群
ICMSP 依賴Rubin GPU集群級緩存容量,以及英偉達即將推出的BlueField-4數據處理器(DPU)—— 該處理器集成Grace CPU,吞吐量高達 800 Gbps。BlueField-4 將提供硬件加速的緩存部署管理功能,消除元數據開銷,減少數據遷移,并確保GPU節點的安全隔離訪問。英偉達的軟件產品(包括DOCA框架、Dynamo KV緩存卸載引擎及其內置的 NIXL(英偉達推理傳輸庫)軟件實現了 AI 節點間 KV 緩存的智能加速共享。
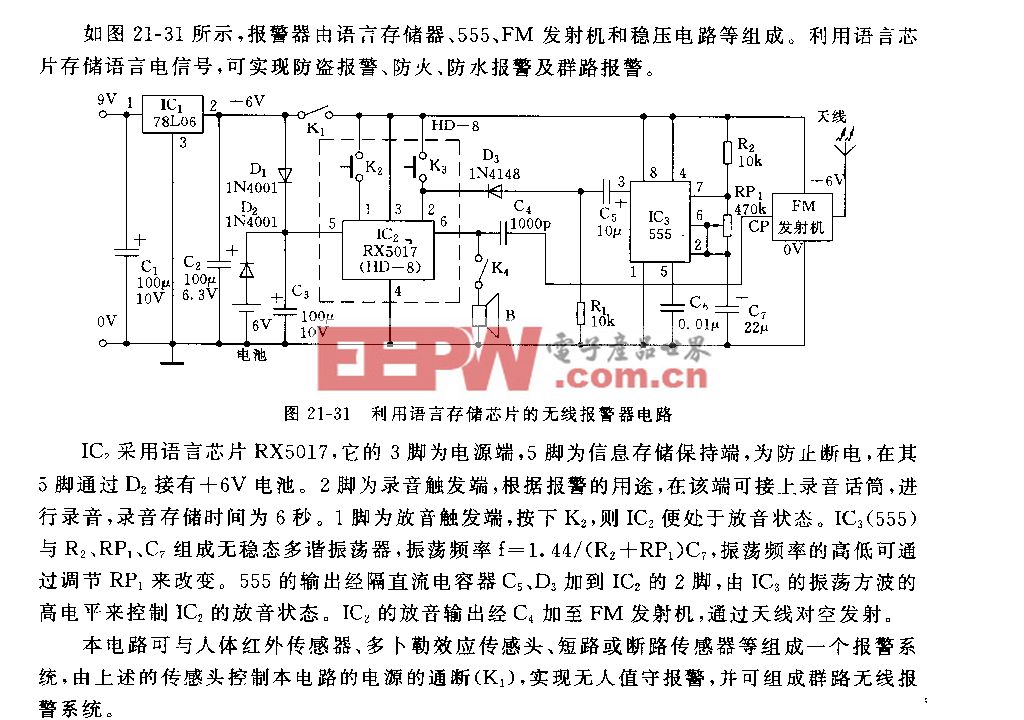
存儲架構必須重構,在這個過程中,上下文成為新瓶頸,主要體現在模型規模持續擴大、上下文(Context)長度不斷增加、多輪對話導致上下文(Context)累積以及并發用戶與會話數量增多等方面。

圖2 黃仁勛在 CES 2026 展示的上下文瓶頸幻燈片
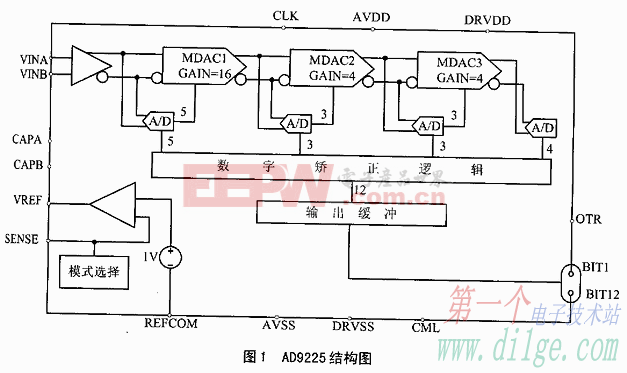
Dynamo支持跨內存和存儲層級的協同工作,覆蓋GPU的高帶寬內存(HBM)、GPU 服務器 CPU 的動態隨機存取存儲器(DRAM)、直連 NVMe SSD 及網絡附加存儲。此外,還需搭配英偉達Spectrum-X以太網,為基于RDMA的AI原生KV緩存訪問提供高性能網絡架構。英偉達稱,ICMSP的能效將比傳統存儲提升5倍,令牌每秒處理量最高可提升5倍。

圖3 黃仁勛在 CES 2026 展示的推理上下文內存存儲平臺幻燈片
行業反饋
鑒于英偉達在AI算力架構方面擁有絕對的話語權,ICMSP的推出必定會得到一眾合作伙伴的鼎力支持,以免錯失商機。英偉達列出了眾多將通過BlueField-4支持ICMSP的存儲合作伙伴,BlueField-4 將于 2026 年下半年正式上市。首批合作伙伴包括 AIC、Cloudian、DDN、戴爾科技、HPE、日立數據系統、IBM、Nutanix、Pure Storage、超微(Supermicro)、VAST Data 和 WEKA。預計 NetApp、聯想(Lenovo)和 Hammerspace 也將后續加入。
將KV緩存卸載或擴展至NVMe SSD的架構理念,其實已有廠商率先實踐 —— 例如 Hammerspace的零級存儲技術(Tier zero tech)、VAST Data的開源軟件VAST Undivided Attention(VUA),以及WEKA的增強內存網格(Augmented Memory Grid)。戴爾也通過在PowerScale、ObjectScale和閃電計劃(Project Lightning,私人預覽版)存儲產品中集成LMCache和NIXL等技術,實現了KV緩存卸載功能。
這些均為基于BlueField-3的解決方案。如今,英偉達旨在為所有存儲合作伙伴提供標準化的KV緩存內存擴展框架。戴爾、IBM、VAST Data和WEKA已明確表示將支持 ICMSP。WEKA在題為《上下文時代已然來臨》的博客中,詳細闡述了支持該平臺的實施方案及核心原因,指出ICMSP是 “一類新型 AI 原生基礎設施,將推理上下文視為一級平臺資源。這一架構方向與WEKA的增強內存網格高度契合,后者通過擴展 GPU 內存,實現了大規模、無限量、高速、高效且可復用的上下文存儲。”
WEKA產品營銷副總裁Jim Sherhart表示:“為上下文數據套用為長期存儲數據設計的重量級持久性、復制和元數據服務,會產生不必要的開銷 —— 導致延遲增加、功耗上升,同時降低推理經濟性。”“推理上下文固然需要適當的管控,但它的特性與企業級數據不同,不應強行套用企業級存儲語義。傳統協議和數據服務帶來的開銷(如元數據路徑、小 I/O 放大、默認的持久性 / 復制機制、在錯誤層級施加的多租戶控制),可能將‘高速上下文’降級為‘低速存儲’。當上下文對性能至關重要且需頻繁復用的情況下,這種開銷會直接體現為尾部延遲增加、吞吐量下降和效率降低。”
VAST Data 表示,其存儲/AI操作系統將運行在BlueField-4處理器上,“打破傳統存儲層級界限,提供機柜級共享KV緩存,為長上下文、多輪對話和多智能體推理提供確定性訪問性能。”VAST 全球技術合作副總裁John Mao稱:“推理正逐漸成為一個內存系統,而非單純的計算任務。未來的贏家不會是擁有最多原始計算資源的集群,而是那些能以線速遷移、共享和管控上下文的集群。連續性已成為新的性能前沿。如果上下文無法按需獲取,GPU 將陷入閑置,整個系統的經濟性將徹底崩塌。通過在英偉達 BlueField-4 上運行 VAST AI 操作系統,我們正將上下文轉化為共享基礎設施 —— 默認高速、按需提供策略驅動管控,并能隨著智能體 AI 的規模擴展保持性能穩定性。”
關于ICSMP,黃仁勛在CES 2026后答分析師會議上做了更多詳細的說明,其中最驚人的是黃仁勛表態希望未來英偉達成為最大的存儲處理器公司,從而掌握更大數據話語權。
Aaron Rakers- 富國銀行證券有限責任公司研究部:目前供應鏈面臨著諸多動態變化,比如 DRAM 價格、供應可用性等問題。我想了解你們對供應鏈的看法。
黃仁勛(Jen-Hsun Huang:我們的供應鏈涵蓋了上游和下游。我們的優勢在于,由于我們的規模已經非常龐大,而且在如此大的規模下仍然保持快速增長,我們很早就開始為合作伙伴準備應對這種大規模的產能擴張。
過去兩年,大家一直在和我討論供應鏈問題 —— 這是因為我們的供應鏈規模巨大,而且增長速度驚人。每個季度,我們的增長規模都相當于一家完整的公司,這還只是增量部分。我們每季度都在新增一家大型上市公司的規模。因此,我們在 MGX(機架級產品)方面所做的所有供應鏈優化工作 ——
我們之所以如此注重組件標準化、避免生態系統和供應鏈資源浪費、并為合作伙伴提供大量投資(包括預付款支持),就是為了幫助他們擴大產能。我們談論的不是數百億美元,而是數千億美元的投入,以幫助供應鏈做好準備。因此,我認為我們目前的供應鏈狀況非常良好,這得益于我們與合作伙伴長期穩定的合作關系。而且,大家應該知道,我們是全球唯一一家直接采購 DRAM 的芯片公司。
仔細想想,我們是全球唯一一家直接采購DRAM的芯片公司。有人問我們為什么要這么做?因為事實證明,將DRAM整合為CoWoS(晶圓級系統集成)并打造超級計算機的難度極大。而建立這樣的供應鏈體系,給了我們巨大的競爭優勢。
現在市場環境雖然嚴峻,但我們很幸運擁有這樣的技術能力。說到功耗,看看我們的上游合作伙伴 —— 系統制造商、內存供應商、多層陶瓷電容器(MLCC)供應商、印刷電路板(PCB)供應商等,我們與他們都保持著緊密的合作。
James Schneider- 高盛集團研究部:我想了解一下你們今天宣布的上下文(Context)內存存儲控制技術。它在各類應用場景中的重要性如何?您是否認為它會成為某些特定客戶問題的性能瓶頸?我們是否可以期待你們在這個方向上繼續創新,就像你們過去在網絡領域所做的那樣?
黃仁勛(Jen-Hsun Huang):我們現在是全球最大的網絡公司。我預計我們還將成為全球最大的存儲處理器公司,而且很可能我們的高端 CPU 出貨量也將超過其他任何公司。原因在于,Vera 和 Grace(以及 Vera 相關產品)已經應用于每個節點的智能網絡接口卡(SmartNIC)中。
我們現在是 AI 工廠的智能網絡接口卡提供商。當然,很多云服務提供商都有自己的智能網絡接口卡(如亞馬遜的 Nitro),他們會繼續使用。但在外部市場,BlueField 系列產品取得了巨大的成功,而且 BlueField-4 將會表現更加出色。BlueField-4 的采用率(不僅僅是早期采用)正在快速增長。其上層的軟件層名為 DOCA(發音與 CUDA 相近),現在已經被廣泛采用。因此,在高性能網絡的東西向流量(east-west traffic)方面,我們是市場領導者。
在網絡隔離的南北向流量(north-south networking)方面,我非常有信心我們也將成為市場領導者之一。而存儲領域目前是一個完全未被充分服務的市場。傳統的存儲基于 SQL 結構化數據,結構化數據庫相對輕量化。而 AI 數據庫的鍵值緩存(KV caches)則極其龐大,你不可能將其掛在南北向網絡上 —— 這會造成網絡流量的巨大浪費。你需要將其直接集成到計算架構中,這就是我們推出這一新層級存儲技術的原因。
這是一個全新的市場,很可能會成為全球最大的存儲市場 —— 它將承載全球 AI 的工作內存。這種存儲的規模將是巨大的,而且需要極高的性能。我非常高興的是,目前人們進行的推理工作負載已經超出了全球現有基礎設施的計算能力。因此,我們現在處理的上下文(Context)內存、令牌內存和鍵值緩存的規模已經非常龐大,傳統的存儲系統已經無法滿足需求。當市場出現這種拐點,而你又有遠見能夠預見它的到來時,這就是進入一個新市場的最佳時機。而 BlueField-4 在這一領域具有絕對的競爭優勢,沒有任何產品能與之匹敵。
Ken Chui- Robocap:我的問題同時涉及利潤率和技術。你們目前已經擁有 CPX 技術,通過收購 Grok,你們還獲得了可用于推理的 SRAM 技術。此外,你們的團隊一個月前發表了一篇論文,討論如何在 GPU 中使用 CPX 技術,從而減少對 HBM 的依賴 —— 因為可以用 GDDR7 替代 HBM。我們都知道 HBM 的成本非常高。因此,未來通過結合 Grok 的技術和你們內部的 CPX 技術,你們對 HBM 的使用會有何變化?這是否能更好地控制 HBM 的使用成本,從而對利潤率產生積極影響?
黃仁勛(Jen-Hsun Huang):當然。我可以先描述一下這些技術各自的優勢,然后再談談面臨的挑戰。例如,CPX 在每美元預填充性能(prefill per dollar)方面比普通的 Rubin 更有優勢 ——Rubin CPX 的每美元預填充性能高于普通版 Rubin。如果將所有數據都存儲在 SRAM 中,那么當然不需要 HBM 內存。但問題是,SRAM 能夠支持的模型規模比 HBM 小 100 倍左右。
不過,對于某些工作負載來說,SRAM 的速度要比 HBM 快得多,因此性能會極其出色。因此,我認為它在預填充(prefill)和解碼(decode)等場景中會有明顯優勢。但問題在于,工作負載的形態一直在變化 —— 有時是混合專家模型(MOE),有時是多模態模型,有時是擴散模型(diffusion models),有時是自回歸模型(auto regressive models),有時是狀態空間模型(SSMs)。這些模型的形態和規模各不相同,對 NVLink、HBM 內存或其他組件的壓力也會不斷變化。
因此,我的觀點是,由于工作負載變化如此之快,而且全球的創新速度也在加快,英偉達之所以能夠成為通用解決方案,正是因為我們的靈活性。大家明白我的意思嗎?如果你的工作負載從早到晚都在變化,而且客戶需求各不相同,那么我們的產品具有很強的通用性,幾乎適用于所有場景。你可能能夠針對某一種特定工作負載進行極致優化,但如果這種工作負載只占總負載的 10%、5% 甚至 12%,那么當它不被使用時,這部分數據中心資源就被浪費了 —— 而你只有 1 吉瓦的電力資源。
關鍵在于,你不能把數據中心看作是擁有無限資金和空間的資源,而是要在有限的電力下實現整體利用率的最大化。架構越靈活,整體效益就越好。如果采用統一的架構 —— 例如,當我們更新 DeepSeek 模型時,數據中心內所有 GPU 的性能都會立即提升;當我們更新通義千問(Qwen)模型的庫時,整個數據中心的性能都會提升 —— 這樣的協同效應是非常顯著的。但如果你有 17 種不同的架構,每種架構只適用于特定場景,那么整體的總擁有成本(TCO)反而會更高。這就是面臨的挑戰。即使在我們研發這些技術時,也非常清楚這一點 —— 這非常困難。
(如果您需要完整版黃仁勛CES后的分析師會議問答記錄,可以私信留言獲取。)








評論