大模型 | VLA 初識及在自動駕駛場景中的應用

VLA (Vision Language Action)是一種多模態機器學習模型,結合了視覺、語言和動作三種能力,旨在實現從感知輸入直接映射到控制動作的完整閉環能力。VLA 強調一體化多模態端到端架構,非感知規控的模塊化方案。
下圖是常見端到端的框架,是 RT-2、OpenVLA、CLIP-RT 等 VLA 系統的典型代表,這些系統均采用基于 Transformer 的視覺和語言骨干網絡,并通過跨模態注意力機制進行融合。
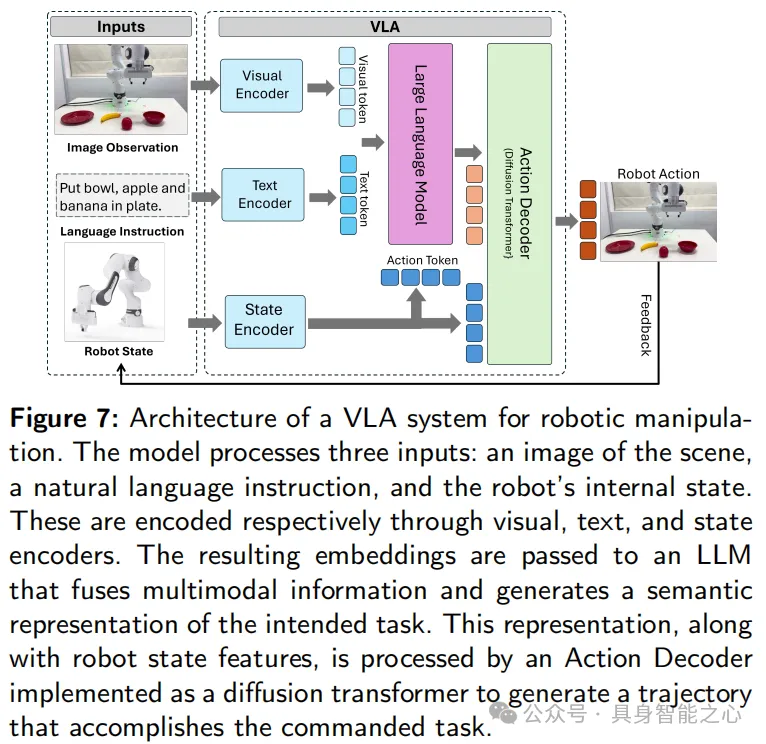
該架構融合視覺、語言和本體感受三類編碼器,視覺編碼器(如 ViT、DINOv2)提取圖像特征,語言編碼器(如 PaLM、LLaMA)將自然語言指令嵌入相同空間,狀態編碼器則將機器人感知與運動狀態編碼為輔助 tokens,支持可達性推理與反饋調整。
所有 tokens 拼接后送入 Transformer,可通過擴散策略(如 Diffusion Policy)或直接映射策略得到控制命令。輸出可為連續動作信號(如執行器速度)。
1.2 VLA 典型結構VLA 模型典型結構如下,圍繞視覺編碼器、語言編碼器和動作解碼器三個關聯模塊構建
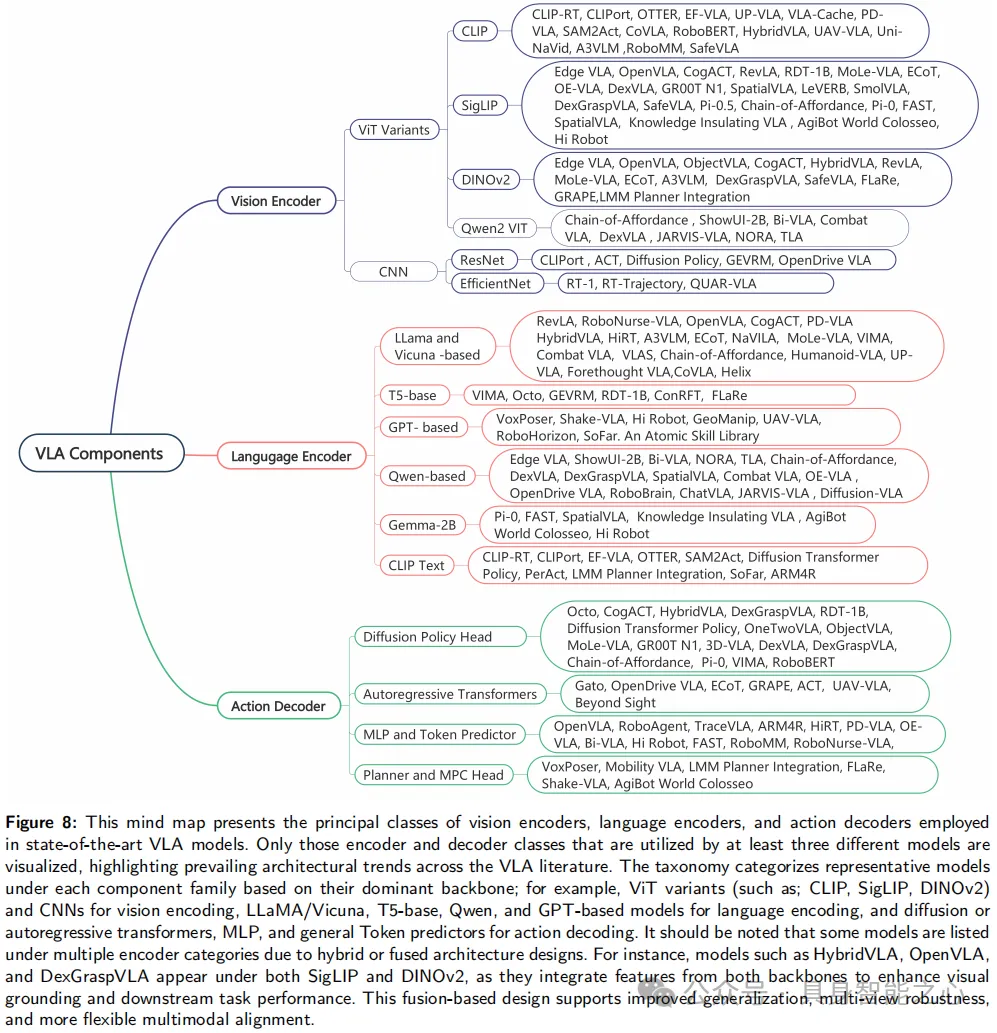
視覺編碼器中:
基于 CLIP 和 SigLIP 的編碼器因對比學習帶來的強視覺文本對齊能力受青睞,應用于 CLIPort 等模型;
DINOv2、Qwen2 VIT 等 ViT 變體因能建模長距離空間依賴和高級視覺語義,應用于 HybridVLA 等模型;
ResNet、EfficientNet 等基于 CNN 的編碼器則出現在 CLIPort、ACT、RT-1、QUAR-VLA 等模型中;
語言編碼器:
LLaMA 和 Vicuna 系列用于 RevLA、OpenVLA 等模型,支持指令理解和零樣本推理;
T5 風格模型應用于 VIMA、Octo 等,提供靈活的編碼器 - 解碼器結構;
GPT 和 Qwen 系列在 VoxPoser 等模型中平衡泛化能力與緊湊部署;
Gemma-2B 用于 Pi-0、FAST;
CLIP 文本編碼器則在 CLIPort 等中完成基礎對齊任務;
動作解碼器:
基于擴散的 Transformer 是 Octo 等模型首選,通過迭代去噪實現細粒度、平滑控制;
自回歸 Transformer 頭在 Gato 等中逐步生成動作序列,優化實時響應;
VoxPoser 等模型嵌入模型預測控制或規劃頭支持動態決策;
MLP 或 tokens 預測器頭用于 OpenVLA 等實現高效低級控制;
總結:
視覺編碼器多采用 CLIP 和 SigLIP 基于的 ViT 骨干網絡;
語言領域以 LLaMA 家族為主;
動作解碼中基于擴散的 Transformer 頭因建模復雜多模態動作分布能力最受青睞;
視覺語言模型(VLM)雖然擅長理解復雜場景,但存在以下問題:
空間精度不高:輸出軌跡點是基于語言生成的,易產生偏差。
傳統端到端模塊雖然推理快,但缺乏全局語義理解能力。可以通過一種“慢 → 快”的協同機制來連接兩者,Trajectory Refinement(軌跡優化) 就是這個橋梁。Trajectory Refinement 用于提升路徑規劃的精度與實時性,其本質是使用 DriveVLM(慢系統)輸出的粗略軌跡作為參考,引導傳統自動駕駛模塊(快系統)進行高頻率、實時的精細軌跡生成。
端到端快系統 的輸入端是以視覺為主的傳感器信息,輸出端是行駛軌跡。VLM 慢系統 的輸入端是 2D 視覺信息、導航信息,輸出端是文本而非軌跡(VLM 并非端到端神經網絡)。
端到端模型和 VLM 是兩個獨立的模型,且運行頻率不同,做聯合訓練與優化非常困難。
VLM 在語義推理空間和純數值軌跡的行動空間之間仍然存在巨大鴻溝。
VLM 通過疊加多幀的圖像信息完成時序建模,會受到 VLM 的 Token 長度限制,會增加額外的計算開銷。
VLA 的輸入端是視覺為主的傳感器信息、2D 視覺信息、3D 視覺信息、導航信息、語音指令信息,輸出端是文本和行駛軌跡。
VLA 視覺-語言-動作 模型與端到端系統,均為(傳感輸入)端到(控制輸出)端神經網絡,在神經網絡架構上均能實現全程可導。
VLM 視覺-語言模型因為其并不直接輸出軌跡,導致無法受益于真實數據和生成數據的驅動。
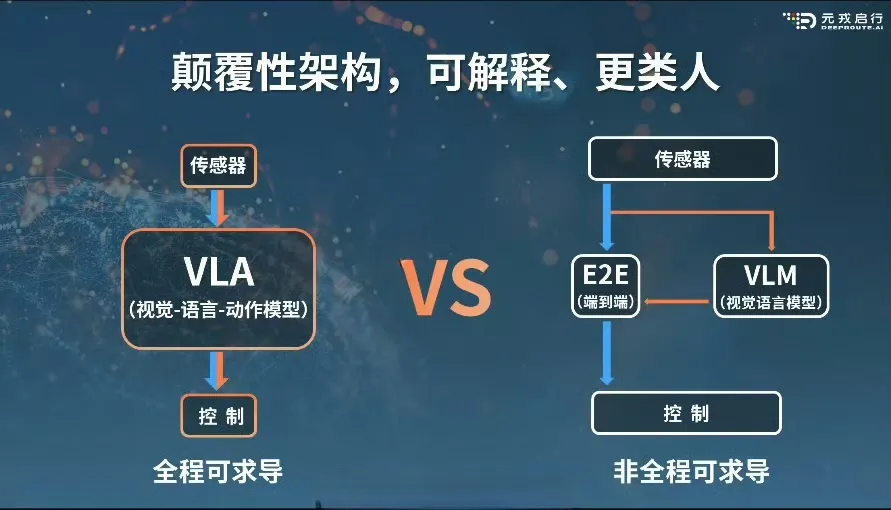
全程可求導和非全程可求導的區別在于,無論是數據驅動的端到端還是知識驅動的 VLA,都能高效率、低成本地通過自動化的數據閉環實現駕駛場景數據驅動,而 VLM 視覺語言模型無法借助數據閉環,實現高效率、低成本的數據驅動。
在算法架構層面,VLA 引入了大語言模型,在算法形式層面,VLA 保持了從傳感輸入到軌跡輸出的端到端神經網絡形式。
三、智駕中典型 VLA 架構3.1 MindVLA:理想MindVLA 整合空間智能、語言智能和行為智能,基于端到端和 VLM 雙系統架構,通過 3D 空間編碼器和邏輯推理生成合理的駕駛決策(LM),并利用擴散模型優化駕駛軌跡。LLM 基座模型采用 MoE 混合專家架構和稀疏注意力技術。
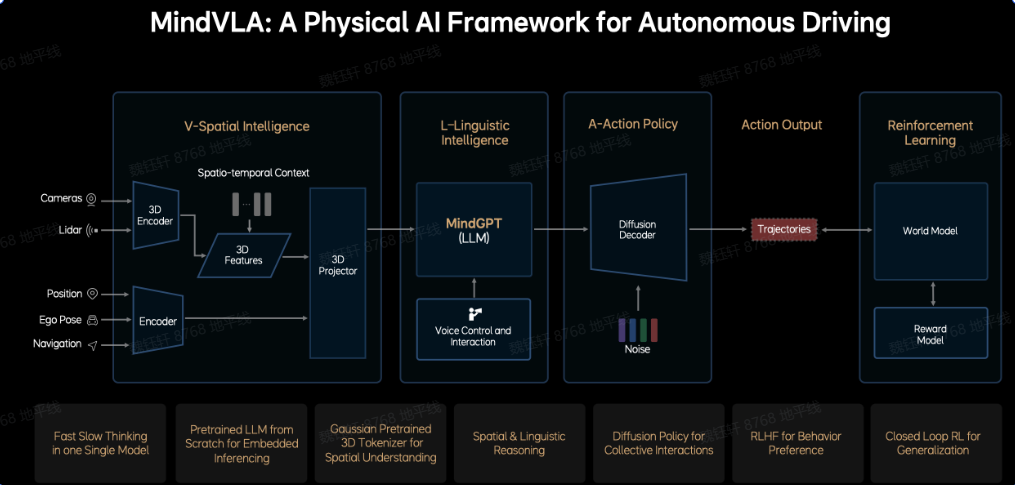
V 空間智能模塊:輸入為多模態傳感器數據,使用 3D 編碼器提取時空特征,然后將所有傳感器與語義信息融合成統一的特征。
L 語言智能模塊:大語言模型 MindGPT,用于空間 + 語言的聯合推理,支持語音指令和反饋,可實現人車交互。
A 動作策略模塊:使用擴散模型生成車輛未來軌跡,引入噪聲來引導擴散過程,從而生成多樣化的動作規劃。
強化學習模塊:使用 World Model 模擬外部環境響應,評估行為后果;使用獎勵模型(Reward Model)提供駕駛偏好,將人類駕駛偏好轉化為獎勵函數(RLHF)。
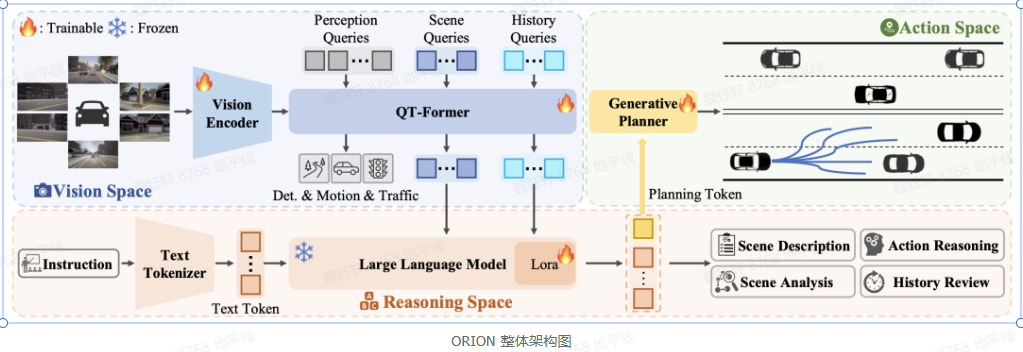
通過視覺語言指令指導軌跡生成的端到端自動駕駛框架。ORION 引入了 QT-Former 用于聚合長期歷史上下文信息,VLM 用于駕駛場景理解和推理,并啟發式地利用生成模型對齊了推理空間與動作空間,實現了視覺問答(VQA)和規劃任務的統一端到端優化。
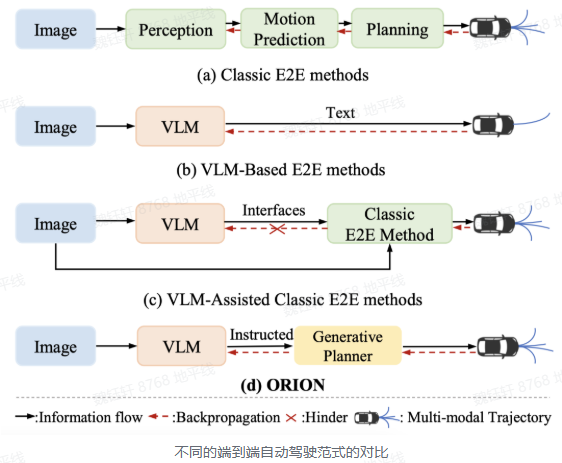
VLM:結合用戶指令、長時和當前的視覺信息,能夠對駕駛場景進行多維度分析,包括場景描述、關鍵物體行為分析、歷史信息回顧和動作推理,并且利用自回歸特性聚合整個場景信息以生成規劃 token,用來指導生成模型進行軌跡預測。
生成模型:通過生成模型,將 VLM 的推理空間與預測軌跡的動作空間對齊。生成模型使用變分自編碼器(VAE)或擴散模型,以規劃 token 作為條件去控制多模態軌跡的生成,確保模型在復雜場景中做出合理的駕駛決策。生成模型彌補了 VLM 的推理空間與軌跡的動作空間之間的差距。
QT-Former:通過引入歷史查詢和記憶庫,有效聚合長時視覺上下文信息,增強了模型對歷史場景的理解能力,聚合歷史場景信息,使模型能夠將歷史信息整合到當前推理和動作空間中。可以減少計算開銷,還能更好地捕捉靜態交通元素和動態物體的運動狀態。
https://developer.horizon.auto/blog/13051 https://developer.horizon.auto/blog/12961 https://mp.weixin.qq.com/s/j3DYoYfkp0yrNlO9oR2tgA https://zhuanlan.zhihu.com/p/1888994290799195699 https://mp.weixin.qq.com/s/nP70QtcVLjgLq8Ue95BdJw https://mp.weixin.qq.com/s/j3DYoYfkp0yrNlO9oR2tgA https://mp.weixin.qq.com/s/PR_RFtbEfOV2L0cQXg574A
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






