1. LLM 訓(xùn)練基礎(chǔ)概念
1.1 預(yù)訓(xùn)練(Pretrain)
LLM 首先要學(xué)習(xí)的并非直接與人交流,而是讓網(wǎng)絡(luò)參數(shù)中充滿知識(shí)的墨水,“墨水” 理論上喝的越飽越好,產(chǎn)生大量的對(duì)世界的知識(shí)積累。 預(yù)訓(xùn)練就是讓 Model 先埋頭苦學(xué)大量基本的知識(shí),例如從 Wiki 百科、新聞、書籍整理大規(guī)模的高質(zhì)量訓(xùn)練數(shù)據(jù)。 這個(gè)過程是“無監(jiān)督”的,即人類不需要在過程中做任何“有監(jiān)督”的校正,而是由模型自己從大量文本中總結(jié)規(guī)律學(xué)習(xí)知識(shí)點(diǎn)。 模型此階段目的只有一個(gè):學(xué)會(huì)詞語接龍。例如我們輸入“秦始皇”四個(gè)字,它可以接龍“是中國(guó)的第一位皇帝”。
1.2 有監(jiān)督微調(diào)(Supervised Fine-Tuning)
經(jīng)過預(yù)訓(xùn)練,LLM 此時(shí)已經(jīng)掌握了大量知識(shí),然而此時(shí)它只會(huì)無腦地詞語接龍,還不會(huì)與人聊天。
SFT 階段就需要把半成品 LLM 施加一個(gè)自定義的聊天模板進(jìn)行微調(diào)。例如模型遇到這樣的模板【問題-> 回答,問題-> 回答】后不再無腦接龍,而是意識(shí)到這是一段完整的對(duì)話結(jié)束。 稱這個(gè)過程為指令微調(diào),就如同讓已經(jīng)學(xué)富五車的「牛頓」先生適應(yīng) 21 世紀(jì)智能手機(jī)的聊天習(xí)慣,學(xué)習(xí)屏幕左側(cè)是對(duì)方消息,右側(cè)是本人消息這個(gè)規(guī)律。
1.3 人類反饋強(qiáng)化學(xué)習(xí)(Reinforcement Learning from Human Feedback, RLHF)
在預(yù)訓(xùn)練與有監(jiān)督訓(xùn)練過程中,模型已經(jīng)具備了基本的對(duì)話能力,但是這樣的能力完全基于單詞接龍,缺少正反樣例的激勵(lì)。 模型此時(shí)尚未知什么回答是好的,什么是差的。
希望模型能夠更符合人的偏好,降低讓人類不滿意答案的產(chǎn)生概率。 這個(gè)過程就像是讓模型參加新的培訓(xùn),優(yōu)秀員工作為正例,消極員工作為反例,學(xué)習(xí)如何更好地回復(fù)。可以使用 RLHF 系列之-直接偏好優(yōu)化(Direct Preference Optimization, DPO)或與 PPO(Proximal Policy Optimization)。DPO 相比于 PPO:
RLHF 訓(xùn)練步驟并非必須,此步驟難以提升模型“智力”而通常僅用于提升模型的“禮貌”,有利(符合偏好、減少有害內(nèi)容)也有弊(樣本收集昂貴、反饋偏差、多樣性損失)。
GRPO(Generalized Reinforcement Preference Optimization)是一種改進(jìn)的強(qiáng)化學(xué)習(xí)方法,用于優(yōu)化模型輸出更符合人類偏好。它是對(duì) PPO(Proximal Policy Optimization)+ RLAIF(Reinforcement Learning from AI Feedback)等方法的泛化和增強(qiáng),本質(zhì)上是對(duì) RLHF(人類反饋強(qiáng)化學(xué)習(xí))的一種高效實(shí)現(xiàn)。GRPO 的目標(biāo):從兩個(gè)或多個(gè)候選輸出中,優(yōu)化模型朝更高偏好方向移動(dòng),而不是只學(xué)單個(gè)“正確答案”。
1.4 知識(shí)蒸餾(Knowledge Distillation, KD)
經(jīng)過預(yù)訓(xùn)練、有監(jiān)督訓(xùn)練、人類反饋強(qiáng)化學(xué)習(xí),模型已經(jīng)完全具備了基本能力,通常可以學(xué)成出師了。
知識(shí)蒸餾可以進(jìn)一步優(yōu)化模型的性能和效率,所謂知識(shí)蒸餾,即學(xué)生模型面向教師模型學(xué)習(xí)。 教師模型通常是經(jīng)過充分訓(xùn)練的大模型,具有較高的準(zhǔn)確性和泛化能力。 學(xué)生模型是一個(gè)較小的模型,目標(biāo)是學(xué)習(xí)教師模型的行為,而不是直接從原始數(shù)據(jù)中學(xué)習(xí)。
在 SFT 學(xué)習(xí)中,模型的目標(biāo)是擬合詞 Token 分類硬標(biāo)簽(hard labels),即真實(shí)的類別標(biāo)簽(如 0 或 100)。 在知識(shí)蒸餾中,教師模型的 softmax 概率分布被用作軟標(biāo)簽(soft labels)。小模型僅學(xué)習(xí)軟標(biāo)簽,并使用 KL-Loss 來優(yōu)化模型的參數(shù)。
通俗地說,SFT 直接學(xué)習(xí)老師給的解題答案。而 KD 過程相當(dāng)于“打開”老師聰明的大腦,盡可能地模仿老師“大腦”思考問題的神經(jīng)元狀態(tài)。知識(shí)蒸餾的目的只有一個(gè):讓小模型體積更小的同時(shí)效果更好。 然而隨著 LLM 誕生和發(fā)展,模型蒸餾一詞被廣泛濫用,從而產(chǎn)生了“白盒/黑盒”知識(shí)蒸餾兩個(gè)派別。 GPT-4 這種閉源模型,由于無法獲取其內(nèi)部結(jié)構(gòu),因此只能面向它所輸出的數(shù)據(jù)學(xué)習(xí),這個(gè)過程稱之為黑盒蒸餾,也是大模型時(shí)代最普遍的做法。黑盒蒸餾與 SFT 過程完全一致,只不過數(shù)據(jù)是從大模型的輸出收集。
1.5 LoRA (Low-Rank Adaptation)
LoRA 是一種高效的參數(shù)高效微調(diào)(Parameter-Efficient Fine-Tuning, PEFT)方法,旨在通過低秩分解的方式對(duì)預(yù)訓(xùn)練模型進(jìn)行微調(diào)。 相比于全參數(shù)微調(diào)(Full Fine-Tuning),LoRA 只需要更新少量的參數(shù)。 LoRA 的核心思想是:在模型的權(quán)重矩陣中引入低秩分解,僅對(duì)低秩部分進(jìn)行更新,而保持原始預(yù)訓(xùn)練權(quán)重不變。
2. LLM 訓(xùn)練流程簡(jiǎn)介
訓(xùn)練任何模型,需要清楚兩個(gè)問題:
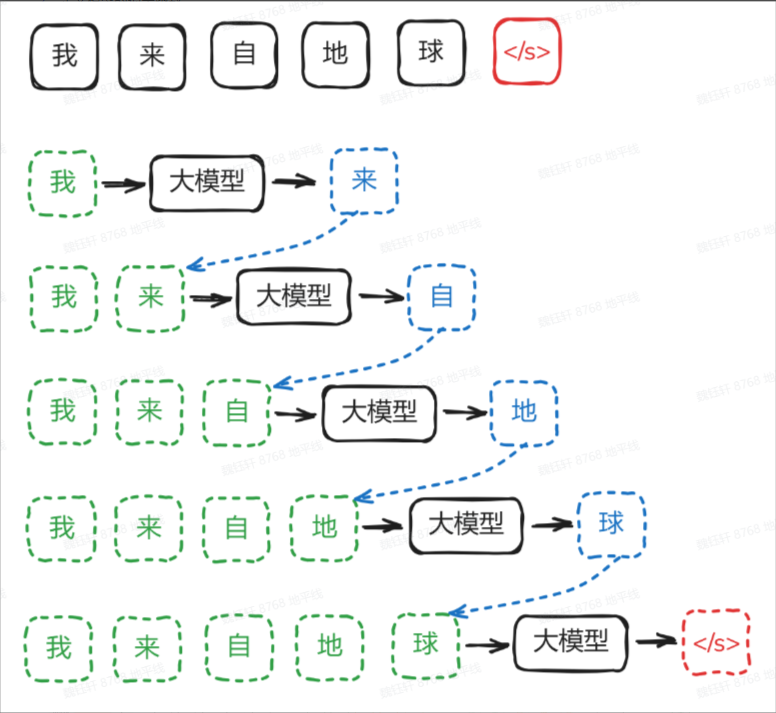
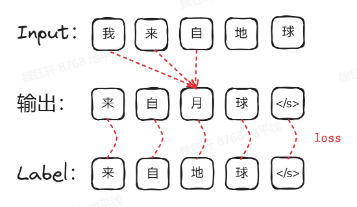
LLM,即大語言模型,本質(zhì)上是一個(gè)“token 接龍”高手,它不斷預(yù)測(cè)下一個(gè)詞符。這種推理生成方式被稱為自回歸模型,因?yàn)槟P偷妮敵鰰?huì)作為下一輪的輸入,形成一個(gè)循環(huán)。
剛開始,一個(gè)隨機(jī)大模型,面對(duì)輸入,它預(yù)測(cè)的下一個(gè)字符完全是隨機(jī)的
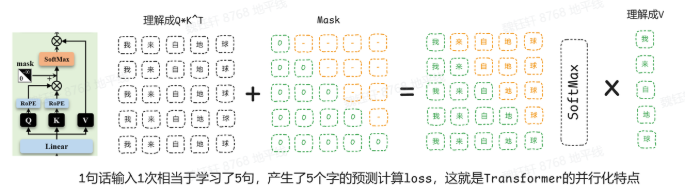
那么,它是如何學(xué)習(xí)的呢?在自注意力機(jī)制中,通過為 qk 增加掩碼,softmax 后將負(fù)無窮對(duì)應(yīng)到 0,隱藏掉 n 字符以后的內(nèi)容。這樣,輸出的第 n+1 個(gè)字符只能關(guān)注到前 n 個(gè)字符,如同戴上了一副“只看過去”的眼鏡。
通過訓(xùn)練,大模型從一個(gè)隨機(jī)混沌的狀態(tài),逐漸學(xué)會(huì)輸入與下一個(gè)詞符之間的潛在聯(lián)系。
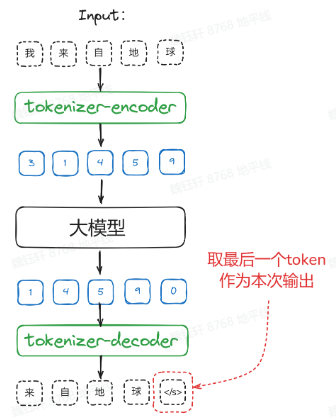
大模型的輸入是由數(shù)字組成的張量,而非自然語言字符。自然語言通過 tokenizer(可以理解為一種詞典)映射到詞典的頁碼數(shù)字 ID,進(jìn)行輸入計(jì)算。得到的輸出數(shù)字再利用詞典進(jìn)行解碼,重新得到自然語言。
大模型的輸出是一個(gè) N*len(tokenizer)的多分類概率張量,在 Topk 中選出的有概率的 token,得到下一個(gè)詞。
學(xué)習(xí)率:與 batchsize 成倍數(shù)關(guān)系,batchsize 變大一倍,學(xué)習(xí)率也增大一倍
參考鏈接
https://github.com/jingyaogong/minimind
https://developer.horizon.auto/blog/13043
*博客內(nèi)容為網(wǎng)友個(gè)人發(fā)布,僅代表博主個(gè)人觀點(diǎn),如有侵權(quán)請(qǐng)聯(lián)系工作人員刪除。