征程 6X 常見 kernel panic 問題

1. 概述
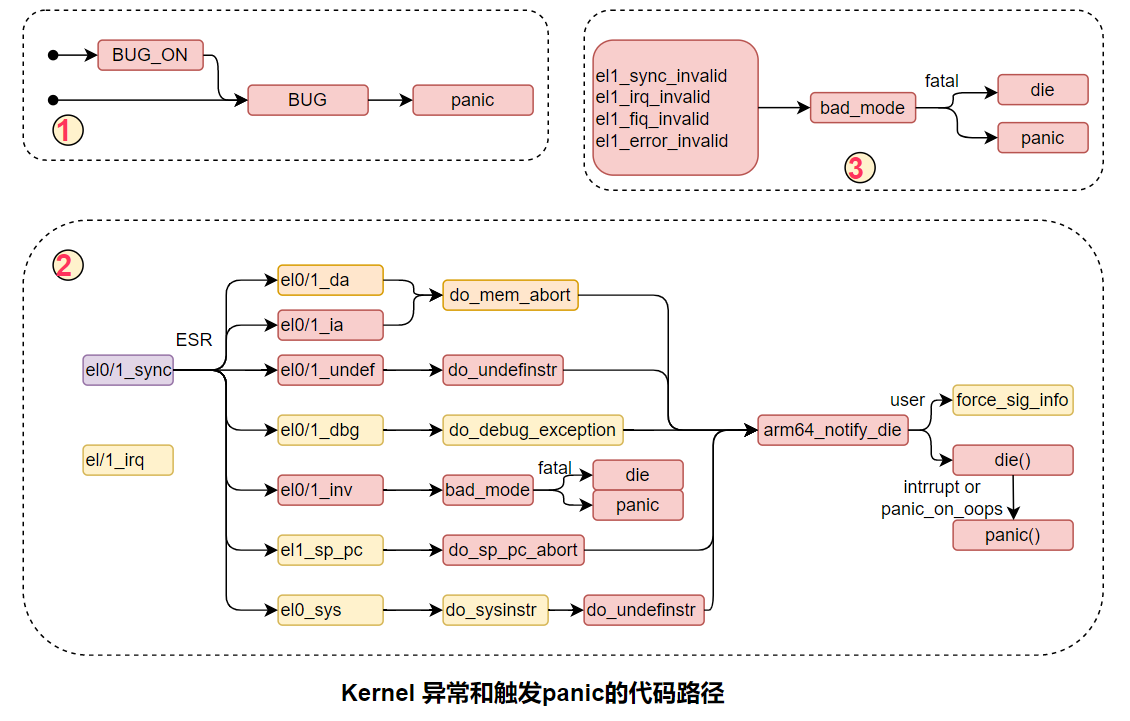
2. 通用方法
3. 典型問題
3.1. 異常指針訪問
例:
<4>[ 1486.084782] CPU: 0 PID: 0 Comm: swapper/0 Tainted: P O 6.1.134-rt51-04836-g0b3e5cbe5431 #13 <4>[ 1486.090809] Hardware name: Horizon AI Technologies, Inc. HOBOT Sigi-P Matrix (DT) <4>[ 1486.091730] pstate: 00400009 (nzcv daif +PAN -UAO -TCO BTYPE=--) <4>[ 1486.092492] pc : __memcpy+0x48/0x180 <4>[ 1486.092953] lr : kfifo_copy_in+0x68/0x94 <4>[ 1486.093456] sp : ffff8000124cbd40 <4>[ 1486.093876] pmr_save: 000000e0 <4>[ 1486.094265] x29: ffff8000124cbd40 x28: ffff0001950ae200 <4>[ 1486.094942] x27: ffff0001765b8800 x26: 0000000000000000 <4>[ 1486.095619] x25: 0000000000000340 x24: 0000000000000018 <4>[ 1486.096295] x23: 00000000f97f0681 x22: ffff8000124cbe18 <4>[ 1486.096970] x21: ffff0001950ae280 x20: 00000000ffff0001 <4>[ 1486.097646] x19: 00000000f97f0681 x18: 0000000000000000 <4>[ 1486.098321] x17: 0000000000000000 x16: 0000000000000000 <4>[ 1486.098997] x15: 000000000000000a x14: 0000000035693bc0 <4>[ 1486.099672] x13: ffff800011feecd1 x12: ffffffffffffffff <4>[ 1486.100348] x11: ffffffffffffffff x10: 0000000000000020 <4>[ 1486.101024] x9 : ffff800011feecbc x8 : 0000000005f5e100 <4>[ 1486.101699] x7 : ffff00027ee2f8b8 x6 : 00000001239ae000 <4>[ 1486.102376] x5 : ffff0001950ae280 x4 : 0000000000000008 <4>[ 1486.103052] x3 : 0000000100000025 x2 : 00000000f97f0679 <4>[ 1486.103728] x1 : ffff8000124cbe20 x0 : 00000001239ae000 <4>[ 1486.104405] Call trace: <4>[ 1486.104717] __memcpy+0x48/0x180 <4>[ 1486.105133] __kfifo_in+0x3c/0x5c <4>[ 1486.105558] bpu_core_tasklet+0x1b0/0x300 [bpu_cores] <4>[ 1486.106214] tasklet_action_common.isra.0+0x90/0xd4 <4>[ 1486.106837] tasklet_action+0x28/0x34 <4>[ 1486.107306] _stext+0x1e0/0x220 <4>[ 1486.107709] __irq_exit_rcu+0x80/0xd0 <6>[ 1486.107789] [S1][V0]subdev_balance_lost_next_frame lost_this = 0x1, lost_next = 0x1, <6>[ 1486.107803] [S2][V0]subdev_balance_lost_next_frame lost_this = 0x1, lost_next = 0x1, <6>[ 1486.107813] [S3][V0]subdev_balance_lost_next_frame lost_this = 0x1, lost_next = 0x1, <6>[ 1486.107827] [S0][V0]subdev_balance_lost_next_frame lost_this = 0x0, lost_next = 0x1, <6>[ 1486.107921] [S4][V0]cim_balance_lost_next_frame lost_this = 0x0, lost_next = 0x1, <4>[ 1486.108179] irq_exit+0x10/0x20 <4>[ 1486.113403] __handle_domain_irq+0x70/0xa0 <4>[ 1486.113928] gic_handle_irq+0x2d0/0x30c <4>[ 1486.114419] el1_irq+0xcc/0x180 <4>[ 1486.114822] arch_cpu_idle+0x30/0x38 <4>[ 1486.115278] default_idle_call+0x30/0x3c <4>[ 1486.115779] do_idle+0x130/0x258 <4>[ 1486.116194] cpu_startup_entry+0x24/0x54 <4>[ 1486.116695] rest_init+0xd4/0xe4 <4>[ 1486.117108] arch_call_rest_init+0x10/0x1c <4>[ 1486.117631] start_kernel+0x6f0/0x734
3.2. HungTask
例:
[ 605.147501] INFO: task ipi7_thread:3826 blocked for more than 120 seconds. [ 605.147532] Tainted: P O 6.1.134-rt51-04836-g0b3e5cbe5431 #13[ 605.147538] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 605.147543] task:ipi7_thread state:D stack: 0 pid: 3826 ppid: 2 flags:0x00000028 [ 605.147559] Call trace: [ 605.147562] __switch_to+0xf8/0x160 [ 605.147583] __schedule+0x268/0x800 [ 605.147594] schedule+0x84/0xf8 [ 605.147602] cimdma_swap_buffer+0x244/0x338 [hobot_cim_dma][ 605.147631] kthread+0x160/0x188 [ 605.147640] ret_from_fork+0x10/0x18 [ 605.147649] INFO: task ipi4_thread:3830 blocked for more than 120 seconds. [ 605.147654] Tainted: P O 6.1.134-rt51-04836-g0b3e5cbe5431 #13[ 605.147658] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 605.147661] task:ipi4_thread state:D stack: 0 pid: 3830 ppid: 2 flags:0x00000028 [ 605.147669] Call trace: [ 605.147671] __switch_to+0xf8/0x160 [ 605.147678] __schedule+0x268/0x800 [ 605.147685] schedule+0x84/0xf8 [ 605.147692] cimdma_swap_buffer+0x244/0x338 [hobot_cim_dma][ 605.147710] kthread+0x160/0x188 [ 605.147716] ret_from_fork+0x10/0x18 [ 605.147723] INFO: task ipi6_thread:3831 blocked for more than 120 seconds. [ 605.147728] Tainted: P O 6.1.134-rt51-04836-g0b3e5cbe5431 #13[ 605.147732] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 605.147735] task:ipi6_thread state:D stack: 0 pid: 3831 ppid: 2 flags:0x00000028 [ 605.147743] Call trace: [ 605.147745] __switch_to+0xf8/0x160 [ 605.147751] __schedule+0x268/0x800 [ 605.147758] schedule+0x84/0xf8 [ 605.147765] cimdma_swap_buffer+0x244/0x338 [hobot_cim_dma][ 605.147783] kthread+0x160/0x188 [ 605.147789] ret_from_fork+0x10/0x18 [ 605.147796] INFO: task ipi5_thread:3832 blocked for more than 120 seconds. [ 605.147801] Tainted: P O 6.1.134-rt51-04836-g0b3e5cbe5431 #13[ 605.147805] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 605.147808] task:ipi5_thread state:D stack: 0 pid: 3832 ppid: 2 flags:0x00000028 [ 605.147816] Call trace: [ 605.147818] __switch_to+0xf8/0x160 [ 605.147824] __schedule+0x268/0x800 [ 605.147831] schedule+0x84/0xf8 [ 605.147838] cimdma_swap_buffer+0x244/0x338 [hobot_cim_dma][ 605.147856] kthread+0x160/0x188 [ 605.147862] ret_from_fork+0x10/0x18
3.3. RCU Stall
例:
<3>[122235.050769] rcu: INFO: rcu_preempt detected stalls on CPUs/tasks: <3>[122235.050778] rcu: Tasks blocked on level-0 rcu_node (CPUs 0-5): <4>[122235.050789] (detected by 4, t=7502 jiffies, g=34171837, q=56419) <3>[122235.050796] rcu: All QSes seen, last rcu_preempt kthread activity 1 (4325451296-4325451295), jiffies_till_next_fqs=1, root ->qsmask 0x0 <0>[122235.050805] Kernel panic - not syncing: <4>[122235.050809] RCU Stall <4>[122235.050813] CPU: 4 PID: 0 Comm: swapper/4 Tainted: P O 6.1.134-rt51-04836-g0b3e5cbe5431 #13 <4>[122235.050822] Hardware name: Horizon AI Technologies, Inc. HOBOT Sigi-P Matrix (DT) <4>[122235.050828] Call trace: <4>[122235.050830] dump_backtrace+0x0/0x1cc <4>[122235.050846] show_stack+0x18/0x24 <4>[122235.050853] dump_stack+0xcc/0x12c <4>[122235.050863] panic+0xcc/0x344 <4>[122235.050870] panic_on_rcu_stall+0x24/0x28 <4>[122235.050881] rcu_sched_clock_irq+0x830/0x900 <4>[122235.050889] update_process_times+0x60/0x88 <4>[122235.050898] tick_sched_handle.isra.0+0x50/0x68 <4>[122235.050907] tick_sched_timer+0x4c/0x90 <4>[122235.050914] __hrtimer_run_queues+0x108/0x19c <4>[122235.050922] hrtimer_interrupt+0xb0/0x1b8 <4>[122235.050930] arch_timer_handler_phys+0x2c/0x44 <4>[122235.050940] handle_percpu_devid_irq+0x5c/0x104 <4>[122235.050951] generic_handle_irq+0x24/0x3c <4>[122235.050958] __handle_domain_irq+0x9c/0xa0 <4>[122235.050965] gic_handle_irq+0x2d0/0x30c <4>[122235.050975] el1_irq+0xcc/0x180 <4>[122235.050982] arch_cpu_idle+0x30/0x38 <4>[122235.050991] default_idle_call+0x30/0x3c <4>[122235.050999] do_idle+0x144/0x270 <4>[122235.051008] cpu_startup_entry+0x24/0x54 <4>[122235.051015] secondary_start_kernel+0x1a4/0x1bc <6>[122236.028018] [S0][V0]pym_subdev_stop <6>[122236.028038] pym_check_stop_state cnt 10 pym->irq_status = 4 <6>[122236.046863] pym_check_exit_state cnt 9 pym->irq_status = 4 <2>[122236.061751] SMP: stopping secondary CPUs <0>[122236.062276] Kernel Offset: disabled <0>[122236.062730] CPU features: 0x0040426,2a00aa38 <0>[122236.063284] Memory Limit: none
[122233.054801] [6] : swapper/6(0) -> evt_thread0(26886) [122234.026784] [6] : evt_thread0(26886) -> swapper/6(0) [122234.028451] [6] : swapper/6(0) -> grep(14873) [122234.028515] [6] : grep(14873) -> swapper/6(0) [122234.051471] [6] : swapper/6(0) -> grep(14873) [122234.051541] [6] : grep(14873) -> swapper/6(0) [122234.054793] [6] : swapper/6(0) -> evt_thread0(26886) [122235.030776] [6] : evt_thread0(26886) -> swapper/6(0)
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






