SigmaStar的SSD20x處理器Nand Flash讀寫問題排查

一批用SSD20X開發的設備在用SD卡升級之后變磚,無法啟動linux操作系統;
設備升級的日志表明,設備在擦除Nand Flash時報了E_Fail的錯誤;
芯片廠家反饋應該是Nand Flash不支持,應該換成華邦1G的Nand Flash,
這個...,我們已經出貨了上萬套設備了...
正在進行的生產被緊急叫停,幾千臺設備堆在產線等著出貨;
在這危急關頭,我硬著頭皮頂上排查問題根源,
根據我的理解,我花了半天做了一些測試,據此推測可能的根源并與廠家溝通如下:
可能是因為這個nand flash出廠就有壞塊,
用專門的下載工具可以檢測到兩個壞塊,可能uboot在擦除flash時檢測不到這個壞塊,
沒有跳過壞塊區,仍然去擦,沒辦法從0擦成1,
所以報了E_Fail的擦除錯誤,
在uboot中運行nand bad,打印的信息沒有提示有壞塊;
深入函數打印日志,nand_block_isbad->nand_block_bad函數沒有判斷到壞塊;、
最終是通過HAL_SPINAND_Read的讀取oob數據,根據第一個字節是否是0來判斷壞塊;
在這個函數把讀取到的64個字節的oob 數據打印出來,
發現基本上全都是ff,有大概8個page,是 ff ff ff ff 00 ff …,即第5個字節是00,也不是壞塊所定義的第1個字節為00;
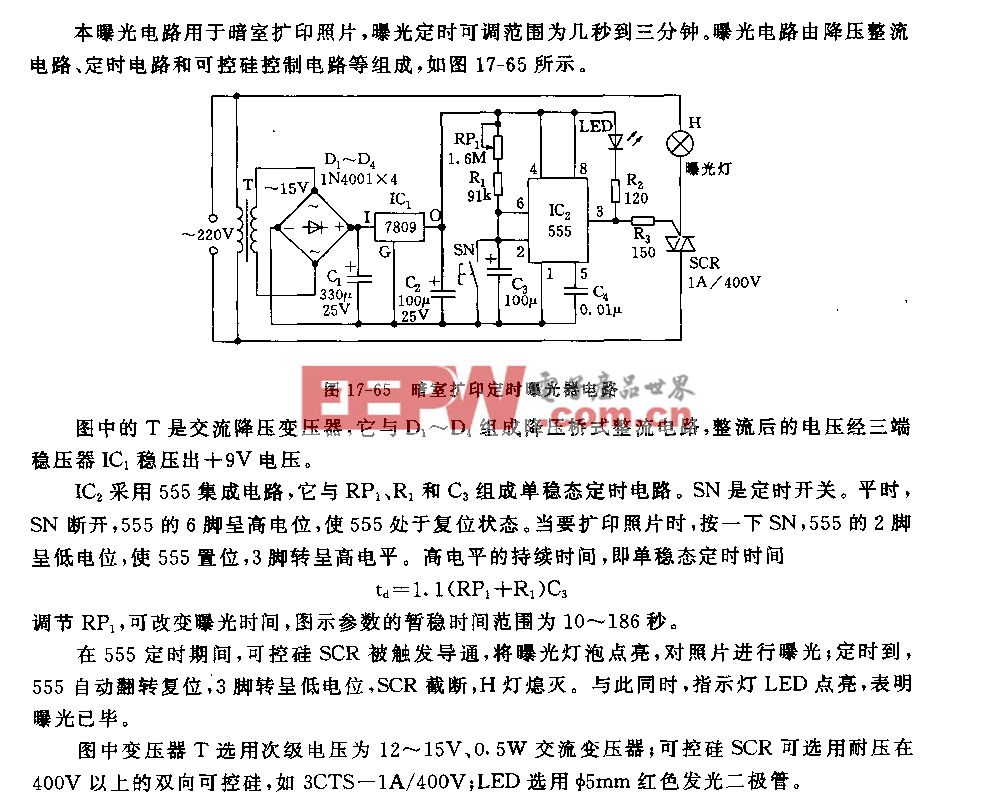
HAL_SPINAND_Read函數讀取spare區的oob數據有問題?
按照nand flash的規格書,壞塊標志00應該在每一個block的第一個page的oob的第一個字節;
廠家提供了最新V55版本的SDK, 并表示,可能是Nand flash存在壞塊在出廠時沒被標識,專用工具可以識別被標識,但是SSD20X不能識別,
我的意見:
兩個可能,一個是沒有標注壞塊,另一個有標注壞塊,SSD20x判斷錯了,誤認為不是壞塊;
Nand Flash的規格書中有這么一句話:
NAND Flash devices are shipped from the factory erased. The factory identifies invalid
blocks before shipping by attempting to program the bad-block mark into every location in the first page of each invalid block. It may not be possible to program every location in an invalid block with the bad-block mark. However, the first spare area location
in each bad block is guaranteed to contain the bad-block mark. This method is compliant with ONFI factory defect mapping requirements. See the following table for the
bad-block mark.
規格書上明確說了,nand flash會做壞塊標識,用專用工具能顯示壞塊,用nand bad沒有顯示壞塊,這肯定是有問題,順著這個問題往下查找,應該就能解決問題了。
第二天一上班,我再次仔細分析HAL_SPINAND_Read函數代碼,有了新的發現;

1. 修改的代碼
HAL_SPINAND_Read函數有問題!
讀nand flash page的函數,根據規格書的說明,首先是發命令0x13給nand flash把數據搬到cache,然后再從cache讀取數據和spare區;
因為這個flash是兩個plane,需要根據page選擇plane;
看上去應該是地址線12選擇plane,在讀數據的時候有或plane選擇位,但是讀spare區的時候并沒有或plane選擇位,
我加上圖示的紅色框內的代碼,或上plan選擇位;
再運行nand bad,可以正常檢測到壞塊,用SD卡升級程序,可以正常啟動內核;
除此之外,HAL_SPINAND_Read還存在另一個問題,

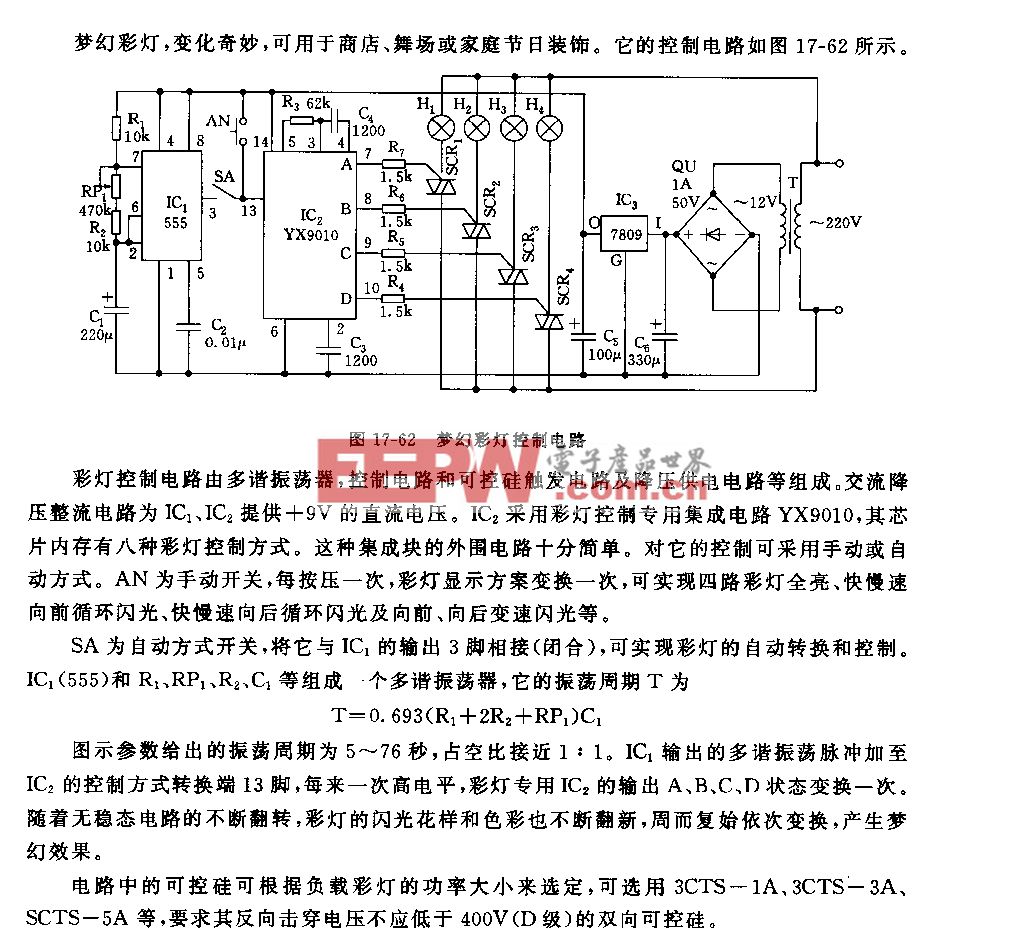
圖2. Nand Flash規格書中關于Page Read的時序說明
發送完13h之后,nand flash需要時間把數據搬到cache,
需要通過GET Features得到的狀態判斷是否搬移完成,但是程序沒有做這樣的判斷,可能導致數據沒準備好就去讀,從而得到錯誤的數據;
一、升級變磚問題
改之前:
HAL_SPINAND_Read(pSpiNandDrv->tSpinandInfo.u16_PageByteCnt...
改之后:
HAL_SPINAND_Read(u16ColumnAddr | pSpiNandDrv->tSpinandInfo.u16_PageByteCnt...
Spare區數據讀錯,奇數plane的數據錯讀偶數plane的Spare區數據,使得壞塊標識和ECC都錯誤;
廠家曾經發2023年3月份左右發布patch修正這一問題,但是當時提到的是ECC算錯的低概率的問題,并沒有提高壞塊標識檢測不到的問題;沒有合并該patch,而且廠家提供的V55版本的SDK也沒有合并該patch;
二、開機LOGO顯示錯亂的問題
V55版本的SDK和V30版本的相比,除了plane標志位的區別,還有就是QUAD讀寫的一些配置上的區別,比如bootdriversmstarspinandincconfiginfinity2mdrvSPINAND_uboot.h中的宏定義SUPPORT_SPINAND_QUAD。
這個定義按我的理解是使能QUAD SPI的讀寫方式,也就是用1根的SPI數據線還是4根SPI數據線;
V30是定義為0,也就是使用1根數據線,
V55是定義為1,也就是使用4根數據線, 這兩個配置SPI的讀寫速度完全不一樣,
當把這個宏定義改為1時,也就是用4根數據線時,開機LOGO在啟動內核前消失的一瞬間顯示錯亂;
在cmd_nand中,對nand bad命令的執行統計執行時間并打印出來,當宏義為1時,執行時間為150us,當定義為0時,執行時間為400us。
uboot啟動內核的腳 本:
bootlogo 0 1 0 0 0;
nand read.e 0x22000000 KERNEL 0x500000;
bootm 0x22000000;
改成以下的啟動代碼,LOGO顯示不錯亂:
run_command("bootlogo 0 1 0 0 0", 0);
udelay(1000);
run_command("nand read.e 0x22000000 KERNEL 0x500000", 0);
run_command("bootm 0x22000000", 0);
改成以下的啟動代碼,LOGO顯示延時3秒,并且不錯亂:
run_command("bootlogo 0 1 0 0 0", 0);
run_command("nand read.e 0x22000000 KERNEL 0x500000", 0);
udelay(3000 * 1000);
run_command("bootm 0x22000000", 0);
說明,顯示LOGO正在刷新之時,改成QAUD讀NAND之后,read kernel加快,使得LOGO的刷新與啟動KERNEL時的display的關閉沖突了。
bootm運行到以下代碼,把延時放在后面,LOGO就不延時顯示,說明boot_selected_os是kernel提供的啟動函數,在這里對硬件做了重新初始化,使得LOGO顯示錯亂。
ret = boot_selected_os(argc, argv, BOOTM_STATE_OS_GO, images, boot_fn);
udelay(3000 * 1000);
三、Feature, status的in process標志的問題
根據nand flash的時序要求:
Following successful completion of PAGE READ, the READ FROM CACHE command must be issued to read data out of cache.
The command sequence is as follows to transfer data from array to output:
? 13h (PAGE READ command to cache)
? 0Fh (GET FEATURES command to read the status)
? 03h or 0Bh (READ FROM CACHE)
…
實際的代碼并沒有讀取status狀態,進行inprocess的判斷,如果數據搬移到cache比較慢,可能出現數據還沒有準備好就去讀的情況,造成讀錯;
U32 MDrv_SPINAND_Read這個函數增加數據ready的判斷,不會出現LOGO錯亂的問題;
u32Ret = HAL_SPINAND_RFC(u32_PageIdx, &u8Status);if(u32Ret != ERR_SPINAND_SUCCESS){ return u32Ret;
}
u16Counter = 0;do{
u32Ret = MDrv_SPINAND_ReadStatusRegister(&u8Status, SPI_NAND_REG_STAT); if(u32Ret == ERR_SPINAND_SUCCESS){ if(0 == (u8Status & 0x1)){ break;
}else{ printf("%s, %d, read busy, counter=%dn", __func__, __LINE__, u16Counter);
}
}
u16Counter++;
}while(u16Counter < 100);
沒有發現有打印busy的日志,可能是cache搬移比較快,不會出現這一情況,從可靠性的角度出發,應該加上status的判斷;
另外,加上status的in process標志位判斷,開機LOGO顯示不再錯亂;
四、Quad SPI讀寫的問題
#define SUPPORT_SPINAND_QUAD (1) 配置成1使用QUAD讀nand
通過以下代碼測試時間:
if (strcmp(cmd, "bad") == 0) { printf("nDevice %d bad blocks:n", dev);
start = get_timer(0); for (off = 0; off < nand->size; off += nand->erasesize) if (nand_block_isbad(nand, off)) printf(" %08llxn", (unsigned long long)off); unsigned long elapsed = get_timer(start); // get elapsed time in us
printf("Elapsed time: %lu usn", elapsed); return 0;
}
Quad read以及增加數據ready的判斷耗時為330us;
不驗證status的in process標志,耗時325 us
#define SUPPORT_SPINAND_QUAD (0) 配置成0使用單線讀nand flash并且驗證ready, 耗時821us;
不驗證status的in process標志,耗時817 us
可見,在顯示開機LOGO和運行kernel啟動函數之間增加幾百us以上的延時就可以解決LOGO錯亂的問題






評論