征程 6 H/P 工具鏈 QAT 精度調優

流程總覽:
針對征程 6H/P 的硬件特性,以 int8+int16+fp16 的混合精度量化為主要調優配置,會增加較多的 fp16 設置來優化量化精度
注意:
征程 6H/P 上會用到更多 fp16 高精度和 GEMM 類算子雙 int16 等的配置,為了配置方式更加簡單靈活,QAT 量化工具提供了一套新的 qconfig 量化配置模板,具體使用方式和注意事項參考:
【地平線 J6 工具鏈入門教程】QAT 新版 qconfig 量化模板使用教程
調優原則:
如上是一個標準的對稱量化公式,產生誤差的地方主要有:
round 產生的舍入誤差。例如:當采用 int8 量化,scale 為 0.0078 時,浮點數值 0.0157 對應的定點值為 round(0.0157 / 0.0078) = round(2.0128) = 2,浮點數值 0.0185 對應的定點值為 round(0.0185 / 0.0078) = round(2.3718) = 2,兩者均產生了舍入誤差,且由于舍入誤差的存在,兩者的定點值一致。 對于舍入誤差,可以使用更小的 scale,這樣可以使得單個定點值對應的浮點值范圍變小。由于直接減小 scale 會導致截斷誤差,所以常用的方法是使用更高的精度類型,比如:將 int8 換成 int16,由于定點值范圍變大, scale 將減小。
clamp 產生的截斷誤差。當 qmax * scale 無法覆蓋需要量化的數值范圍時,可能產生較大截斷誤差。例如:當采用 int8 量化,scale 為 0.0078 時,qmax * scale = 127 * 0.0078 = 0.9906,大于 0.9906 的值對應的定點值將被截斷到 127。 對于截斷誤差,可以使用更大的 scale。scale 一般是由量化工具使用統計方法得到,scale 偏小的原因是校準數據不夠全,校準方法不對,導致 scale 統計的不合理。比如:某一輸入的理論范圍為 [-1, 1],但校準或 qat 過程中,沒有觀測到最大值為 1 或最小值為 -1 的樣本或觀測到此類樣本的次數太少。應該增加此類數據或者根據數值范圍,手動設置固定 scale。在截斷誤差不大的情況下,可以調整校準參數,通過不同的校準方法和超參緩解截斷誤差。
因此,QAT 量化精度調優以減少上述兩種誤差為基本原則,下文將針對 QAT 每個階段做調優介紹:
注意:
征程 6H/P 平臺的浮點模型量化友好設計以及 QAT 模型改造等內容和征程 6E/M 一致,仍可參考該文章對應章節:
【地平線 J6 工具鏈進階教程】J6 E/M 工具鏈 QAT 精度調優
1.1 模型檢查完成模型改造和量化配置后,調用 Prepare 接口時會對模型做算子支持和量化配置上的檢查,這些檢查一定程度上反映了模型量化存在的問題。對于不支持的算子將以報錯的形式提醒用戶,一般有兩種情況:
未正確進行模型的量化改造。Prepare 過程中 QAT 量化工具會對模型進行 trace 來獲取完整的計算圖,在這個過程中會完成算子替換等的優化,對于這些已替換的算子,輸入輸出類型如果是 torch.tensor 而非經過 QuantStub 轉化后的 qtensor,則會觸發不支持算子的報錯,表現為 xxx is not implemented for QTensor;
確實存在不支持的算子。工具鏈已支持業界大量的常用算子,但對于部分非常見算子的不支持情況,需考慮進行算子替換或者作為算子需求向工具鏈團隊導入。
Prepare 運行成功后會在當前目錄下自動保存模型檢查文件 model_check_result.txt 和 fx_graph.txt,建議參考下列解讀順序:
算子融合檢查。算子融合作為 QAT 量化工具的標準優化手段,常見的融合組合為 Conv+ReLU+BN 和 Conv+Add 等,未融合的算子會在 txt 文件中給出,未按預期融合的算子可能是因為共享沒有融合成功或者是 QAT 量化工具的融合邏輯變更(針對新版 qconfig 量化模板 enable_optimize=True 情況,見【地平線 J6 工具鏈入門教程】QAT 新版 qconfig 量化模板使用教程),需要檢查代碼,確認未融合的情況是否符合預期:
# 示例:未融合的Conv+Add算子 Fusable modules are listed below: name type------ ------------------------- model.view_transformation.input_proj.0.0(shared) <class'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> model.view_transformation._generated_add_0 <class'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'>
未融合的算子對模型性能會有一定影響,對于精度的影響需視量化敏感度具體分析,一般來說,Conv/Linear+ReLU+BN 可能會因為算子復用導致未融合,此時建議手動修改融合;在 OE 3.5.0 以及之后版本使用新 qconfig 模板下,Conv+Add 默認不會融合,可不修改
共享模塊檢查。一個 module 只有一組量化參數,多次使用將會共享同一組量化參數,多次數據分布差異較大時,會產生較大誤差:
# 示例:該共享模塊被調用8次 Each module called times: name called times --------- -------------- ... model.map_head.sparse_head.decoder.gen_sineembed_for_position.div.reciprocal 8
called times > 1 的模塊可能有很多個,全部改寫成非共享是一勞永逸的。對于修改簡單且精度影響大的共享算子如 QuantStub,強烈建議取消共享;對于 DeQuantStub 算子,共享不會對模型精度產生影響,但是會影響 Debug 結果的分析,也建議取消共享,修改方式參考征程 6E/M“模型改造”章節。
例如下面的共享模塊,量化表示的最大值為 128 * 0.0446799 ≈ 5.719,在第一次使用中,輸出范圍明顯小于 [-5.719, 5.719],誤差較小, 第二次使用中,輸出范圍超出 [-5.719, 5.719],數值被截斷,產生了較大誤差。兩次數值范圍的差異也造成了統計出的 scale 不準確,因此該共享模塊必須修改
+-+-+-+-+-+-+--+-+-+-+-+| | mod_name | base_op_type | analy_op_type | shape | quant_dtype | qscale |base_model_min | analy_model_min | base_model_max | analy_model_max ||-+-+--+-+-+-+-+-+-+-+-+...| 1227 | model.map_head.sparse_head.decoder.gen_sineembed_for_position.div | horizon_plugin_pytorch.nn.div.Div | horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional.mul | torch.Size([1, 1600, 128])| qint8 | 0.0446799 | 0.0002146 | 0.0000000 | 4.5935526 | 4.5567998 |...| 1520 | model.map_head.sparse_head.decoder.gen_sineembed_for_position.div | horizon_plugin_pytorch.nn.div.Div | horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional.mul | torch.Size([1, 1600, 128]) | qint8 | 0.0446799 | 0.0000000 | 0.0000000 | 6.2831225 | 5.7190272 |...
上面共享算子的修改方式可以參考:
class Model(nn.Module):def __init__(self, ) -> None:super().__init__()...
self.steps = 2for step in range(self.steps):setattr(self, f'div{step}', FloatFunctional())def forward(self, data):...for step in range(self.steps):
data = getattr(self, f'div{step}').div(x)...對于不帶權重的 function 類算子都可以參考上面的拆分方式,但是也存在部分共享算子或模塊帶有權重參數拆分起來比較復雜,是否需要拆分建議先根據量化敏感度進行分析。帶有權重參數算子拆分時需要復制權重,拆分方式可以參考:
class Model(nn.Module):def __init__(self, ) -> None:super().__init__()...
self.steps = 3
self.conv0 = nn.Conv2d(...)
shared_weight = self.conv0.weight
shared_bias = self.conv0.bias
for step in range(1, self.steps):setattr(self, f'conv{step}', nn.Conv2d(...))getattr(self, f'conv{step}').weight = shared_weight
getattr(self, f'conv{step}').bias = shared_bias
def forward(self, data):...for step in range(self.steps):
data = getattr(self, f'conv{step}')(x)...上述共享算子修改生效后,在 model_check_result.txt 文件中可見到無該算子共享相關的信息:
# 修改生效后下面信息將不再顯示 Modules below are used multi times: name called times ------ -------------- xxxxx 2
此外,未調用的模塊也會在文件中體現,called times 為 0,當 Calibration/QAT/模型導出出現 miss_key 時,可以檢查模型中是否有模塊未被 trace。
量化配置檢查。txt 文件中會給出模型量化精度的統計信息:
# 算子輸入量化精度統計input dtype statistics:+---+--+--+--+| module type | torch.float32 | qint8 | qint16 ||---+---+--+--+| <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 290 | 15 | 0 || <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> | 5 | 117 | 9 || <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> | 0 | 8 | 0 |...# 算子輸出量化精度統計 output dtype statistics:+---+--+--+--+| module type | torch.float32 | qint8 | qint16 ||---+--+--+--+| <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 0 | 123 | 182 |...# 使用fp16量化精度的算子,量化精度統計+---+--+--+--+--+| module type | torch.float32 | qint8 | qint16 | torch.float16 ||-----+--+--+--+--|| <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 34 | 0 | 0 | 0 || <class 'torch.nn.modules.padding.ZeroPad2d'> | 0 | 11 | 0 | 0 || <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 48 | 14 | 9 | 50 |...
重點檢查的信息有:
<class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 的 input dtype 應為 torch.float32,對于 qint8 或者 qint16 的 input dtype,一般是冗余的 QuantStub 算子可以改掉,不會對精度產生影響但可能會對部署模型性能有影響(算子數量)
正常來說模型中的算子不應出現 torch.float32 的輸入精度(除下文 c 情況),如上圖的 <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'>,需要檢查是否漏插 QuantStub 未轉定點,未轉定點的算子在導出部署模型時會 cpu 計算從而影響模型性能。對于模型中的一些浮點常量 tensor,工具已支持自動插入 QuantStub 轉定點,建議獲取最新版本
對于 GEMM 類算子(Conv/Matmul/Linear)作為模型輸出時支持高精度輸出(征程 6E/M 支持 int32 輸出,征程 6B/H/P 支持浮點輸出),體現到這里則是 <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> 的 input dtype 應為 torch.float16 或 torch.float32,對于 qint8 或 qint16 輸入的 DeQuantStub 需要檢查是否符合高精度輸出的條件,符合條件但未高精度輸出的需修改。此外對于下面左圖的結構,也建議優化為右圖結構來保證高精度輸出的優化
qint8 和 qint16 算子的占比,可以協助判斷是否配置全 int16 生效;torch.float16 算子的占比,可以協助判斷是否配置 fp16 生效
txt 文件同時會給出逐層的量化配置信息:
# 激活逐層qconfig Each layer out qconfig:+--+--+--+--+--+--+| Module Name| Module Type | Input dtype | out dtype | ch_axis | observer ||--+--+--+--+--+---|# 固定scale| quant | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | [torch.float32] | ['qint16']| -1 | FixedScaleObserver(scale=tensor([3.0518e-05], device='cuda:0'),zero_point=tensor([0], device='cuda:0')) |# QAT訓練激活scale更新| mod2.1.attn.q | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | ['qint16'] | ['qint16'] | -1 | MinMaxObserver(averaging_constant=0.01) |# QAT訓練激活scale不更新| mod2.1.FFN.out_conv.1.0| <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | ['qint16']| ['qint16']| -1| MinMaxObserver(averaging_constant=0) |# 激活fp16 qconfig| bev_fusion.multi_view_cross_attn.32.global_cross_window_attn._generated_add_2[add]| <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | [torch.float16, torch.float32] | [torch.float16] | FakeCast(dtype=torch.float16, min_val=-0.0009765625, max_val=0.0009765625) | |# 權重逐層qconfig Weight qconfig:+-----+----+-----+------+---+| Module Name | Module Type | weight dtype|ch_axis|observer ||---+-------+----+----+---|| mod1.0 | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> |qint8 | 0 | MinMaxObserver(averaging_constant=0.01) |
重點檢查的信息有:
每層算子的輸入輸出 dtype、權重的 dtype,是否符合量化配置;若和量化配置不符合,比如配置了 int16,但是算子顯示為 int8,則需要關注下算子回退信息,例如在舊模板下 Conv+Add 融合時 Conv 不支持 int16 輸入,會導致前序算子輸出回退到 int8。新的 qconfig 量化配置模板下算子回退過程需查看 qconfig_changelogs.txt,詳細參考:https://developer.horizon.auto/blog/13112
配置了 fix scale 的算子,是否正確顯示 FixedScaleObserver 信息,scale 值是否正確
逐層算子的 observer 是否正確:權重默認 MinMaxObserver,QAT 校準時激活默認 MSEObserver,QAT 訓練時激活默認 MinMaxObserver
若為 QAT 訓練階段且配置了固定校準的激活 scale,查看 averaging_constant,判斷是否生效,生效為 averaging_constant=0(即不更新 scale),默認為 0.01(更新 scale)
對于 fx_graph.txt,可以從中獲取到模型中 op/module 的上下游調用關系,例如當存在算子 called times 為 0 未被調用的情況,可以通過 Graph 定位到上下文算子從而定位未被調用的原因(通常因為在 init 函數中定義了但在 forward 中沒有調用,也可能存在邏輯判斷或循環次數變化的情況);此外當出現導出的部署模型(bc 模型)精度異常,也可以通過 Graph 信息來排查是否是導出計算圖改變導致的
# 模型Graph圖結構信息
Graph:
opcode name target args kwargs
---- ----- ------- ------- -------
placeholder input_0 input_0 () {}
call_module quant quant (input_0,) {}
call_module traj_decoder_src_proj_0_0 traj_decoder_src_proj.0.0 (quant,) {}
call_function scope_end <function Tracer.scope_end at 0x7f4477d7dc60> ('traj_decoder_src_proj.0',) {}
call_function __get__ <method-wrapper '__get__' of getset_descriptor object at 0x7f460922b800> (traj_decoder_src_proj_0_0,) {}
call_function __getitem__ <slot wrapper '__getitem__' of 'torch.Size' objects> (__get__, 0) {}
call_function __getitem___1 <slot wrapper '__getitem__' of 'torch.Size' objects> (__get__, 1) {}
call_function __getitem___2 <slot wrapper '__getitem__' of 'torch.Size' objects> (__get__, 2) {}
call_function __getitem___3 <slot wrapper '__getitem__' of 'torch.Size' objects> (__get__, 3) {}
call_function permute <method 'permute' of 'torch._C.TensorBase' objects> (traj_decoder_src_proj_0_0, 0, 2, 3, 1) {}...重點關注的 Graph 信息:
opcode 為算子調用類型
name 為當前算子名稱,需注意和 model_check_result.txt 中的 module.submodule 名稱區別
target 為算子輸出
args 為算子輸入
如果模型中吸收了前后處理的相關算子和操作,這部分默認需要 fp16 精度進行量化
對于 int8+int16+fp16 混合精度而言,主要的量化配置如下(配置方式參考【地平線 J6 工具鏈入門教程】QAT 新版 qconfig 量化模板使用教程):
基礎配置: TAE 算子(Conv/Matmul/Linear)雙 int8、其他算子 fp16
精度優化配置: TAE 算子(Conv/Matmul/Linear)單 int16(部分雙 int16)、其他算子 fp16
精度上限配置: TAE 算子(Conv/Matmul/Linear)雙 int16、其他算子 fp16
性能上限配置: 全局 int8,建議僅在測試模型最優性能(精度無保證)或作為高精度耗時優化的對比參考時配置
同樣的對于較難量化的模型而言,初始應使用精度上限配置,在這個配置下解決量化流程可能的問題,優化量化風險較大的算子/模塊,往往通過 Debug 工具進行定位,但在使用 Debug 工具較難定位到量化瓶頸時,可以使用分步量化的小技巧(參考本文最后章節"調優技巧"),也即對選中算子取消量化后對比精度,如定位到前后處理的算子/模塊產生明顯掉點,建議從模型中剝離;定位到模型中算子/模塊,可以使用設置 fix_scale 和拆分共享模塊等方式,或者從量化友好角度修改浮點模型(參考征程 6E/M 量化調優對應章節:【地平線 J6 工具鏈進階教程】J6 E/M 工具鏈 QAT 精度調優)
精度上限配置下的模型較難滿足部署側的延時要求,因此解決掉上述的量化瓶頸后需要回歸到基礎配置。在基礎配置上通過敏感度的分析結果,增加 TAE 的 int16 算子,也就是精度優化配置。在基礎配置和精度優化配置下精度達標的模型,視延時情況可能需要進一步做性能優化,主要方向為:
基礎配置下,回退 fp16 性能瓶頸算子到低精度 int8
精度優化配置下,回退雙 int16 的 TAE 算子到單 int16,回退 fp16 性能瓶頸算子到低精度 int8
精度優化配置下如果 int16 算子比例已超出部署預期但精度仍有一定差距,則可以考慮回退部分 int16 算子后嘗試 QAT 訓練;基礎配置下精度表現距離浮點差距較小(量化精度/浮點精度 > 90%,經驗值),直接嘗試 QAT 訓練,在 量化精度/浮點精度 >= 95%(經驗值)的情況下,建議優先嘗試固定校準激活 scale 的 QAT 訓練(僅調整權重感知量化誤差)
對于不同精度配置下的 QAT 校準,都有一些校準超參可以調整,需要用戶結合具體模型去做調參優化,其中主要的參數有校準數據的 batch size、校準的 steps,詳細的參數參考:
基礎調優手段:調優指南_基礎調優手段
高級調優手段:調優指南_高級調優手段
由于征程 6H/P 平臺使用了較多浮點 FP16 精度,該精度下數值范圍超限場景有以下常見的優化方法和優缺點總結:
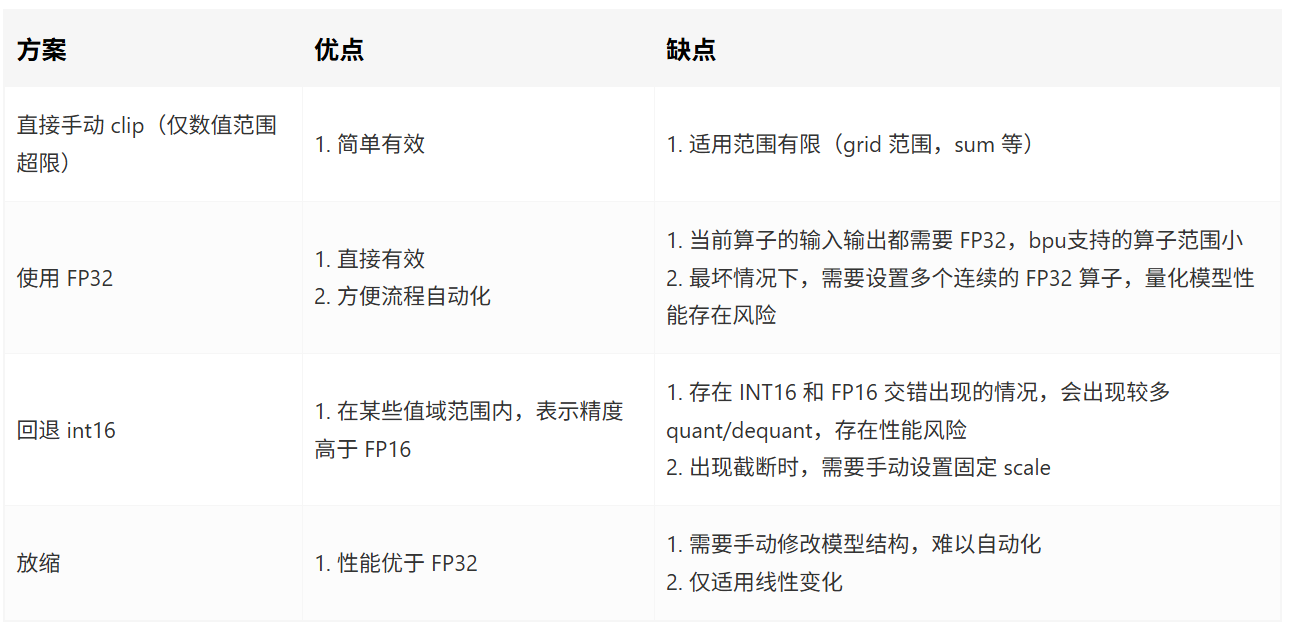
總結:
int8+int16+fp16 混合精度調優的重點應放在 TAE 雙 int16+ 其他算子 fp16 的調優上,這里需要把使用問題,量化不友好模塊等等各種千奇百怪的問題都解決,看到模型的精度上限,然后根據模型部署的性能要求進行 TAE int8 和 int16 混合精度的調優,最后對非 TAE 算子進行 int8+fp16 混合精度的調優,最終達成部署精度和部署性能的平衡。
1.2.2 Debug 產出物解讀征程 6H/P 平臺 Debug 產出物的解讀和征程 6E/M 一致,仍可參考該文章對應章節:【地平線 J6 工具鏈進階教程】J6 E/M 工具鏈 QAT 精度調優
Badcase 調優對于實車或回灌反饋的可視化 badcase,利用 Debug 工具的調優流程為:
大部分模型僅通過 QAT 校準就可以獲得較好的量化精度,對于部分較難調優的模型,以及還需要繼續優化誤差類指標的模型,通常校準設置的高精度比例導致延時超過部署上限,但精度仍無法達標,這種情況可以嘗試 QAT 訓練來獲得滿足預期性能-精度平衡的量化模型。
根據前文所述,在 QAT 校準 量化精度/浮點精度 >= 95%(經驗值) 的情況下,充分利用校準階段較好的激活量化參數,優先嘗試固定校準激活 scale 的 QAT 訓練(僅調整權重感知量化誤差),設置方式具體參考征程 6E/M 精度調優的“模型改造”章節:【地平線 J6 工具鏈進階教程】J6 E/M 工具鏈 QAT 精度調優
參考浮點訓練,QAT 訓練在大部分配置保持和浮點訓練一致的基礎上,也涉及到部分超參的調整來提升量化訓練的精度,例如 QAT 的學習率、weight_decay、迭代次數等,詳細的參數調整策略參考:
基礎調優手段:調優指南_基礎調優手段
高級調優手段:調優指南_高級調優手段
浮點和 QAT 訓練中都涉及到對 BN 的狀態控制,在浮點訓練中可能會采用 FreezeBN fine-tune 的方式來提升模型精度,在多任務訓練中也會采用 FreezeBN 的技巧。因此在 QAT 訓練中,提供了 FuseBN 和 WithBN 兩種訓練方式:
FuseBN 即在 Prepare 后,QAT 訓練前將 BN 的 weight 和 bias 吸收到 Conv 的 weight 和 bias 中,在訓練過程中不再單獨更新,這一吸收過程是無損的。FuseBN 也是 QAT 默認的訓練方式。
WithBN 則是在 QAT 訓練階段保持 Conv+BN 不融合,帶著 BN 進行訓練,BN 的參數單獨更新,在訓練結束后轉成部署模型時再做融合。浮點訓練階段如果采用了 FreezeBN 的訓練方式,QAT 訓練時需設置 WithBN 來對齊浮點訓練方式,設置方式如下:
from horizon_plugin_pytorch.qat_mode import QATMode, set_qat_mode set_qat_mode(QATMode.WithBN)
通過觀察 QAT 訓練過程的 Loss 變化來初步判斷 QAT 訓練的量化效果,一般來說和浮點最后的 Loss 結果越接近越好,Loss 過大可能難以收斂,Loss 過小可能影響泛化性,對于異常的 Loss 建議的優化手段:
異常 INF 和 NAN 的 Loss 值,或者初始 Loss 極大且無收斂跡象,按如下順序排查:
去掉 prepare 模型的步驟,用 qat pipeline finetune 浮點模型,排除訓練 pipeline 的問題,Loss 如果仍異常,需要檢查訓練鏈路的配置如優化器 optimizer 和 lr_updater 等
保持當前 QAT 訓練配置,只關閉偽量化節點后觀察訓練的 Loss 現象,理論上和浮點有微小差異
from horizon_plugin_pytorch.quantization import set_fake_quantize, FakeQuantState ... set_fake_quantize(qat_model, FakeQuantState._FLOAT) train(qat_model, qat_dataloader)
在排查完鏈路問題后出現初始 Loss 較大,有收斂跡象但收斂較慢,這種情況可以嘗試調整學習率,延長 QAT 迭代次數,因為 QAT 訓練本質上是對已收斂浮點模型的 fine-tune,本身存在一定的隨機性,用較大的學習率可以快速波動到一個理想精度(依賴一些中間權重的評測)
對于少數模型,QAT 訓練以及嘗試了多次超參調整后精度仍無法達標,建議回歸 QAT 校準階段增加少量高精度算子(增加 GEMM 類算子 int16,以及其他算子增加 FP16)、回歸浮點結構檢查是否還存在量化不友好的結構如使用了大量 GeLU 等(參考征程 6E/M 精度調優對應章節【地平線 J6 工具鏈進階教程】J6 E/M 工具鏈 QAT 精度調優)
由于 QAT 訓練過程需要感知模型量化所帶來的損失,因此模型中會被插入必要的量化相關的節點:數據觀測節點 Observer 和偽量化節點 FakeQuant。數據觀測節點會不斷統計模型中數據的數值范圍,偽量化節點會根據量化公式對數據做模擬量化和反量化,兩者都會存在開銷,此外就是 QAT 工具內部會對部分算子例如 LN 層做拆分算子的實現,因此相同配置下的 QAT 訓練效率是會略低于浮點訓練效率,具體還和模型參數規模、算子數量等有關。
對于用戶可明顯感知到的 QAT 訓練效率降低,建議的優化手段有:
使用 QAT 工具提供的算子,這些算子優化了訓練效率,例如 MultiScaleDeformableAttention(參考手冊 )
更新到最新的 horizon-plugin-pytorch 版本,新版本會有持續的 bug fix 和新特性優化,如模型中某些結構或者算子訓練耗時增加明顯,可以向工具鏈團隊導入
完成 QAT 精度調優后得到的模型仍是 PyTorch 模型,需要使用簡單易用的接口來一步步導出編譯成部署模型:PyTorch模型 -> export -> convert-> compile
export 得到 qat.bc; convert 得到 quantized.bc; compile 得到 hbm
由于導出生成物中計算差異的存在,對于每個生成物需簡單驗證其精度,可通過單張可視化或 mini 數據集,過程中如存在精度掉點,請參考【地平線 J6 工具鏈進階教程】J6 E/M 工具鏈 QAT 精度一致性問題分析流程
二.調優技巧2.1 分部量化下面這種方式僅適用于 Calib 階段,QAT 階段因為模型已經適應了量化誤差,關閉偽量化精度無法保證
from horizon_plugin_pytorch.utils.quant_switch import GlobalFakeQuantSwitch class Model(nn.Module): def _init_(...): def forward(self, x): x = self.quant(x) x = self.backbone(x) x = self.neck(x) GlobalFakeQuantSwitch.disable() # 使偽量化失效 # --------- float32 --------- x = self.head(x) # --------------------------- GlobalFakeQuantSwitch.enable() # 重新打開偽量化 return self.dequant(x)2.2 部分層凍結下的 QAT 訓練
模型 QAT 訓練時,要求模型為 train() 狀態,此時若部分層凍結,則需要對應修改狀態,參考代碼如下:
from horizon_plugin_pytorch.quantization import (
QuantStub,
prepare,
set_fake_quantize,
FakeQuantState,)
qat_model = prepare(model, example_inputs=xxx, qconfig_setter=(xxx))
qat_model.load_state_dict("calib_model_ckpt.pth")
qat_model.train()# 關閉requires_grad可固定權重不更新,但Drop、BN仍然會更新for param in qat_model.backbone.parameters():
param.requires_grad = False# 配置eval()可固定Drop、BN不更新,但不會固定權重,因此兩者需要配合使用
qat_model.backbone.eval()
set_fake_quantize(qat_model.backbone, FakeQuantState.VALIDATION)#配置head的FakeQuant為QAT狀態
set_fake_quantize(qat_model.head, FakeQuantState.QAT)2.3 Calib/QAT 過程 NaN 值定位出現 NaN 值可通過下面的修改在 calib/qat forward 過程中報錯,從而定位到具體的算子:
from horizon_plugin_pytorch.quantization.fake_quantize import FakeQuantize FakeQuantize.check_nan_scale='forward'#默認為save,在torch.save時檢查是否有nan,有nan會報錯 qat_model = prepare(model, (input), default_qat_qconfig_setter)
常見的可能出現 NaN 值的結構:
Multi-head Attention 的 attn mask,需要手動做數值的 clamp
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






